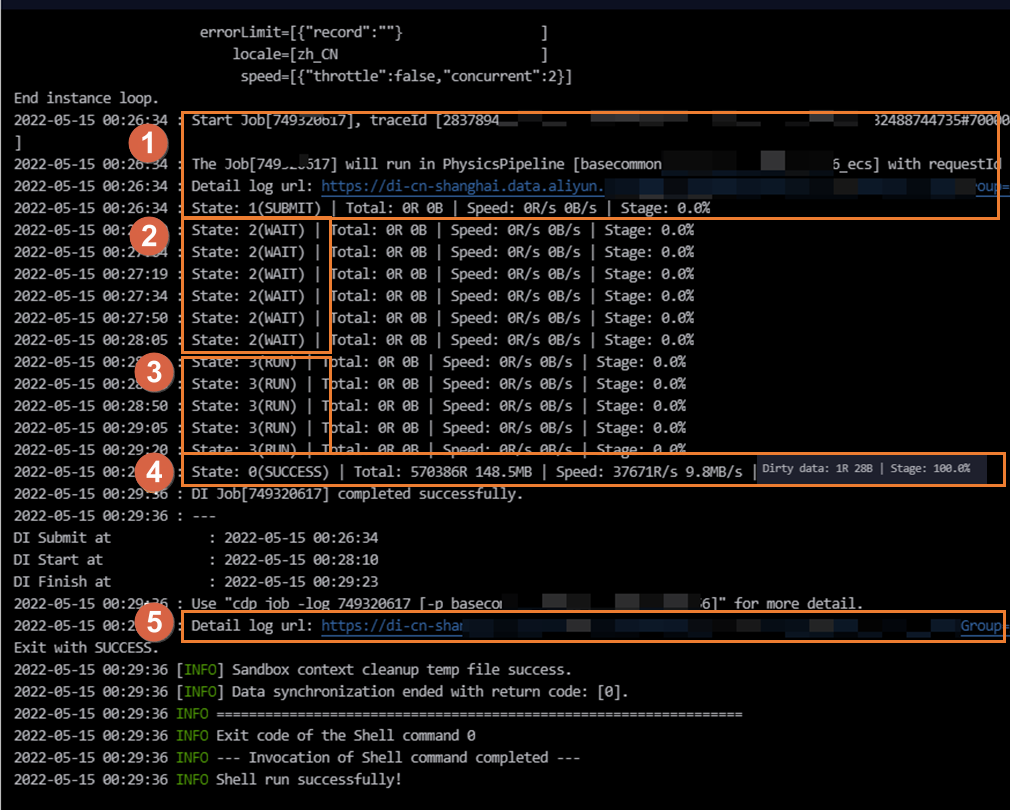
DataWorks任务是执行成功的,怎么看日志有没有脏数据呢?源端是TSDB,查询的metric是存在的,目标端有配置表和分区,也是任务中使用的表和分区,日志中有如下打印,


这种是脏数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果任务涉及SQL操作,可以使用特定的SQL查询来查找脏数据。例如,查找空值、超出预期范围的值、不符合格式的数据等:
查找空值:
SELECT FROM your_table WHERE column_name IS NULL;
查找超出范围的值:
SELECT FROM your_table WHERE column_name < 1 OR column_name > 100;
查找不符合格式的数据:js
SELECT * FROM your_table WHERE column_name NOT LIKE '__--__';
在DataWorks中,您可以通过查看任务日志来检查是否有脏数据。以下是一些常见的方法:
查看任务日志:
在DataWorks中,您可以在任务列表中查看任务的执行日志。在日志中,您可以查看任务的执行结果、执行时间、执行日志等信息。如果任务执行失败,您可以在日志中查看错误信息,并根据错误信息进行排查和修复。
使用条件判断语句:
在DataWorks中,您可以使用条件判断语句来检查数据是否符合要求。例如,您可以使用以下语句检查数据是否为空:
if value == '':
print('Data is empty')
else:
print('Data is not empty')
使用数据清洗工具:
在DataWorks中,您可以使用数据清洗工具来清洗数据。数据清洗工具可以帮助您去除无用数据、处理缺失值、处理重复值等问题。您可以使用DataWorks内置的数据清洗工具,例如Pandas、Numpy等,也可以自己编写数据清洗脚本。
使用数据质量监控工具:
在DataWorks中,您可以使用数据质量监控工具来监控数据质量。数据质量监控工具可以帮助您监控数据的一致性、完整性、准确性等问题。您可以使用DataWorks内置的数据质量监控工具,例如DataGuard、DataClean等,也可以自己编写数据质量监控脚本。
以上是一些常见的方法,您可以根据自己的需求选择适合自己的方法来检查数据是否存在脏数据。
查找脏数据标识:在日志内容中,搜索关键词“Dirty data”。如果存在脏数据,日志中通常会有类似Dirty data: xxR的字样出现,这里xxR代表脏数据的数量
。这表明有部分数据因不符合目标表的约束或转换规则而未被写入。
在DataWorks中,按照更新推送一周以前的数据,使用date_format进行配置是正确的方法。
DataWorks支持使用date_format函数来格式化日期和时间,这对于配置增量数据同步特别有用。要推送一周前的数据,可以结合调度参数bizdate来实现。假设您的业务日期是每天凌晨0点更新,您可以在数据过滤条件中使用类似以下的表达式:col3 >= DATE_FORMAT(DATE_SUB('${bizdate}', INTERVAL 7 DAY), '%Y-%m-%d 00:00:00') AND col3 < '${bizdate}'。
需要注意的是,这里的col3代表包含日期时间信息的数据列,而bizdate是一个系统参数,表示当前的业务日期。通过这样的配置,您可以确保只同步一周前的数据。同时,请确保您的源表包含一个时间戳或日期类型的列,以便于识别增量数据。
在DataWorks中,即使任务执行成功,也可以通过查看任务日志来检测是否存在脏数据。以下是具体的操作步骤和分析方法:
登录控制台
登录到DataWorks控制台并进入相应的项目。
查找任务实例
在项目首页,点击左侧的“运维中心”,然后选择“实例管理”或类似选项。找到需要查看的任务实例,并点击旁边的“查看日志”按钮。
分析日志概览
在任务的详情页面中,查找日志或日志链接部分。通常成功执行的任务日志中也会包含同步的统计信息以及潜在的警告或错误信息。
识别脏数据提示
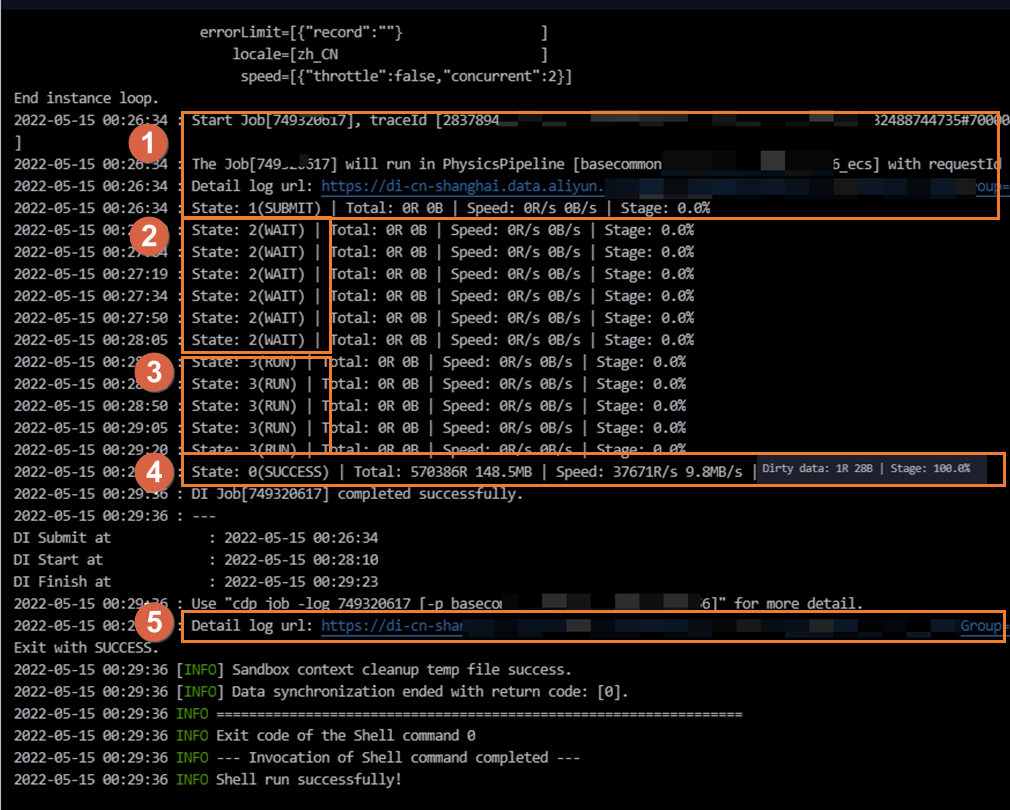
在日志中搜索关键词“脏数据”(可能显示为“Dirty data”)或者相关的错误提示。如果存在脏数据,日志中会出现类似“Dirty data: xxR”的字样,这表明有数据因不符合目标表的约束或格式而未被写入。
深入分析日志详情
如果日志概览中提及脏数据,点击“详细日志链接”或类似的按钮来查看更详尽的日志信息。这将帮助定位到具体的脏数据记录及其原因。
使用SQL查询
如果任务涉及SQL操作,可以使用特定的SQL查询来查找脏数据。例如,查找空值、超出预期范围的值、不符合格式的数据等:
查找空值:SELECT FROM your_table WHERE column_name IS NULL;
查找超出范围的值:SELECT FROM your_table WHERE column_name < 1 OR column_name > 100;
查找不符合格式的数据:SELECT * FROM your_table WHERE column_name NOT LIKE '__--__';
分析脏数据信息
根据日志中提供的脏数据信息,分析源端数据与目标端表结构的兼容性问题,如字段类型是否匹配,数据长度是否在目标字段的容许范围内等。
调整数据处理策略
如果脏数据不影响业务需求,且任务配置允许一定数量的脏数据,可以评估是否需要调整脏数据策略。否则,需要修正数据或调整目标表结构以避免未来发生类似问题。
使用智能分析功能
DataWorks提供了智能分析功能,可以帮助快速定位问题并给出诊断结果和建议。在日志分析列表中选择目标日志,点击操作栏中的智能分析,页面下方展开日志分析界面。
总的来说,通过上述步骤,可以有效地查看和分析DataWorks任务日志中可能存在的脏数据,从而确保数据的质量和一致性。
要在DataWorks中检查一个执行成功的任务是否存在脏数据,您可以按照以下步骤操作:
查看任务日志:
识别脏数据提示:
深入分析日志详情:
分析并解决问题:

从您提供的截图来看这是一段日志输出,其中包含了GC的信息,但并没有直接显示脏数据的具体内容。为了确定是否有脏数据,您可以按照以下步骤操作:
查看任务日志:在DataWorks的任务运行历史中找到对应的任务实例,点击“日志”按钮来查看详细运行过程中的输出。如果有脏数据,可能会在日志中出现相应的警告或错误信息。
数据质量监控:在DataWorks中可以设置数据质量监控规则,例如空值检测、重复值检测等。当这些规则被触发时,系统会自动标记出可能存在的脏数据。
人工审查:对于重要的任务,还可以通过抽取部分样本数据进行人工审查,确认是否存在脏数据。
至于您提到的WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null这条警告信息,它表明某个数值字段尝试转换为数字类型时遇到了null值,导致了NumberFormatException。虽然这不是典型的脏数据情况,但它确实可能影响到您的数据处理流程。建议检查源头数据是否正确,或者在数据清洗阶段添加适当的处理逻辑来处理这类异常值。
要在DataWorks中查看任务执行的日志来检查是否有脏数据,您可以遵循以下步骤:
如果您是在SQL任务中处理数据,则可以通过运行特定的SQL查询来查找脏数据。例如,您可以查找空值、超出预期范围的值、不符合格式的数据等。以下是一些示例查询:
SELECT * FROM your_table WHERE column_name IS NULL;
假设您的列应该在1到100之间:
SELECT * FROM your_table WHERE column_name < 1 OR column_name > 100;
如果某列应该是日期格式:
SELECT * FROM your_table WHERE column_name NOT LIKE '____-__-__';
如果您有自定义的日志记录逻辑,在代码中加入适当的日志记录语句,可以帮助您追踪脏数据的来源。例如,在Python中使用logging模块:
import logging
# 设置日志级别
logging.basicConfig(level=logging.INFO)
# 检查脏数据
def check_dirty_data(data):
if data is None:
logging.info("Found null value in data")
elif not is_valid_data(data): # 假设is_valid_data是您定义的验证函数
logging.warning("Invalid data found: %s", data)
# 使用示例
check_dirty_data(None)
check_dirty_data("invalid data")
DataWorks本身也提供了数据质量检测功能,您可以利用这些功能来自动检测脏数据。这通常涉及到设置规则并运行数据质量检测任务。
最后,结合您的具体业务逻辑来确定什么样的数据被认为是脏数据。例如,如果某些字段是必需的,则任何缺失这些字段的数据都应被视为脏数据。
如果需要进一步的帮助或具体的代码示例,请告诉我更多关于您的任务和数据的具体信息。
在DataWorks中,即使任务执行成功,也可能存在数据质量问题,比如脏数据。要检查日志中是否有脏数据,确认源端TSDB的数据类型和目标端表的字段类型是否匹配。如果类型不匹配,可能会导致转换错误。
数据质量帮助您第一时间感知源端数据的变更与ETL(Extract Transformation Load)中产生的脏数据,自动拦截问题任务,有效阻断脏数据向下游蔓延。避免任务产出不符合预期的问题数据,影响正常使用和业务决策。同时也能显著降低问题处理的时间成本,避免任务重新运行带来的资源费用浪费。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/data-quality-overview?spm=a2c4g.11186623.0.i77
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。