
EMR全托管starrocks集群使用spark connector导入任务事务处理慢如何解决
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
EMR全托管starrocks集群使用spark connector导入任务事务处理慢,ErrorMessage打印:
wait for publishing partition xxx version xxx.self version xxx.table xxx
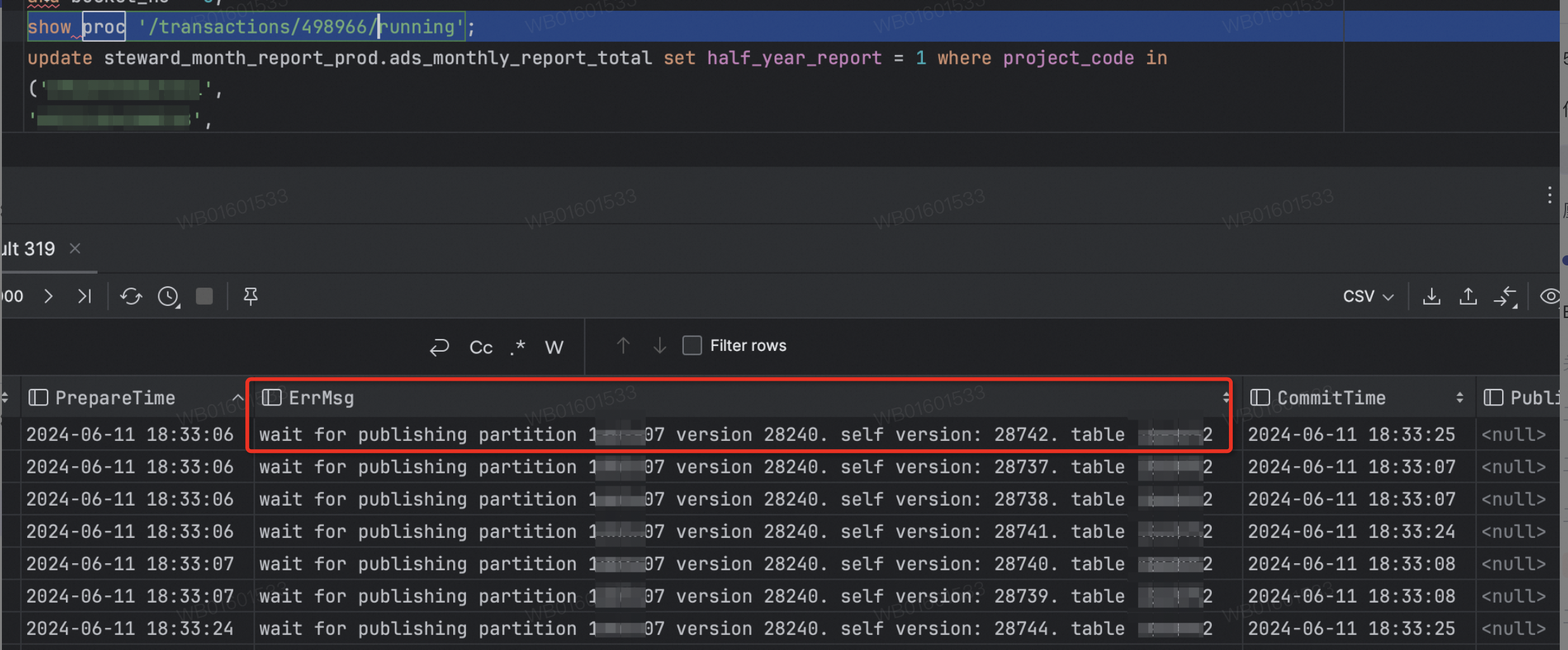
这是因为事务堆积到上限导致的导入变慢,
可调整参数lake_enable_batch_publish_version为true。如下是参数解析:
将StarRocks参数lake_enable_batch_publish_version设置为true时,其主要作用是启用湖仓表(Data Lake Analysis,DLA)中数据发布版本的批处理模式。这意味着在处理数据加载或数据更新操作时,系统会积累一定数量的变更,而不是每次变更后立即发布一个新的版本到数据湖中。而是将这些变更批次处理后,作为一个整体的版本统一发布。
这样的设计带来的好处主要包括:
