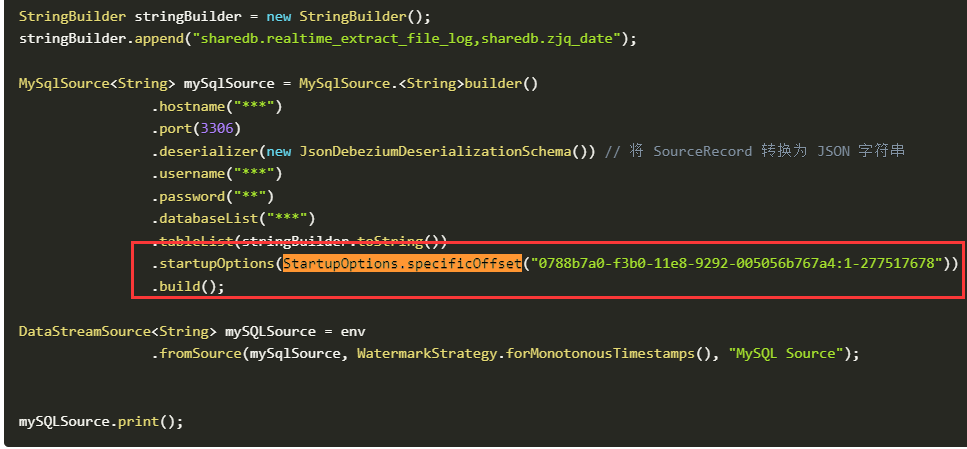
在Flink CDC中StartupOptions.latest()正常运行但是StartupOptions.specificOffset启动就报错的情况吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有遇到过,Flink CDC(Change Data Capture)是Apache Flink的一个组件,它允许Flink以流的方式读取数据库的变更日志。StartupOptions是Flink CDC Connector的配置选项之一,用于定义Flink作业启动时的读取位置。
StartupOptions.latest()是StartupOptions的一个静态方法,它告诉Flink CDC Connector从最新的变更开始读取数据。如果这个方法在正常运行的情况下没有问题,但是在其他配置下报错,可能的原因有很多,包括但不限于:
版本兼容性问题:确保你使用的Flink CDC Connector版本与你的Flink版本兼容。
配置错误:可能存在配置文件或代码中的其他配置错误,导致StartupOptions.latest()无法正常工作。
环境问题:可能是数据库环境或网络环境的问题,导致Flink无法连接到数据库或获取不到最新的变更数据。
权限问题:Flink作业可能没有足够的权限去读取数据库的变更日志。
资源问题:可能是由于资源不足,如内存或CPU限制,导致作业无法正常启动。
错误使用API:可能是在代码中错误地使用了StartupOptions.latest(),例如在不恰当的地方调用或者与其他配置冲突。

在Flink CDC中,使用StartupOptions.latest()能够正常启动而切换到StartupOptions.specificOffset时遇到报错,这可能是由于几个原因造成的:
位点信息不准确:确保在使用specificOffset时提供的Binlog文件名(scan.startup.specific-offset.file)和位置(scan.startup.specific-offset.pos)是准确无误的。如果这些参数指向了一个无效或不存在的Binlog位点,将会导致启动失败[1]。
GTID不匹配:如果使用的是GTID集(scan.startup.specific-offset.gtid-set)来指定启动位点,确保GTID集合精确且与数据库中的实际GTID相匹配。任何不匹配都可能导致启动失败。
权限与网络问题:虽然报错未直接提及,但确保Flink任务运行的环境有足够权限访问MySQL数据库,并且网络通畅,没有因防火墙或网络策略导致的连接中断问题>。
配置冲突:检查是否有其他配置项与specificOffset启动模式存在潜在冲突,比如是否正确设置了scan.incremental.snapshot.enabled参数。在某些情况下,不当的配置组合可能导致启动异常。
驱动或版本兼容性:确认使用的Flink版本与MySQL CDC Connector以及JDBC驱动之间的兼容性。不兼容的版本组合可能引发意料之外的错误
为了解决这个问题,建议采取以下步骤:
specificOffset模式相适应,避免配置冲突。请根据上述建议排查并调整配置,以解决specificOffset启动模式下的报错问题。
相关链接
CDC问题 报错:The primary key is necessary when enable 'Key: 'scan.incremental.snapshot.enabled' https://help.aliyun.com/zh/flink/support/faq-about-cdc
在使用 Apache Flink 的 Change Data Capture (CDC) 连接器时,StartupOptions 用于指定作业启动时从源数据读取的起始位置。StartupOptions.latest() 通常用于从最新的数据开始读取,而 StartupOptions.specificOffset(String offset) 则允许你指定一个具体的偏移量来开始读取数据。
如果你在使用 StartupOptions.specificOffset(String offset) 时遇到错误,而 StartupOptions.latest() 正常运行,这可能是由几个原因造成的:
偏移量格式或值错误:
确保你提供的偏移量格式符合源数据库或存储系统的要求。不同的 CDC 连接器(如 Debezium、Canal 等)对于偏移量的格式有不同的要求。
检查偏移量是否确实存在于源数据中。如果指定的偏移量不存在或已被删除,那么连接器可能无法正确初始化。
源数据状态:
如果源数据在指定偏移量之后发生了某些变更(如表的重新创建、分区调整等),那么该偏移量可能不再有效。
检查源数据库或存储系统的日志,看是否有与表或数据变更相关的错误或警告。
连接器配置:
检查 Flink CDC 连接器的配置,确保所有必要的配置项都已正确设置。
特别注意与源数据库连接相关的配置,如服务器地址、端口、用户凭证等。
版本兼容性:
确保你使用的 Flink CDC 连接器版本与 Flink 集群版本兼容。
如果可能,尝试更新到最新版本的 Flink 和 CDC 连接器。
错误日志:
仔细查看 Flink 作业的日志输出,特别是与 CDC 连接器相关的部分。日志中通常会包含导致错误的具体原因和堆栈跟踪。
权限问题:
确保 Flink 作业有足够的权限从源数据库或存储系统中读取数据。
为了解决这个问题,你可以尝试以下步骤:
重新检查并验证你提供的偏移量。
尝试使用 StartupOptions.earliest() 来测试连接器是否能从最早的数据开始读取,以排除其他潜在问题。
在开发或测试环境中模拟相同的场景,以便更容易地调试和修复问题。
查阅 Flink CDC 连接器的官方文档或社区论坛,看看是否有其他用户遇到并解决了类似的问题。
如果问题仍然存在,你可能需要联系 Flink CDC 连接器的开发者或维护者以获取进一步的帮助。
当在Flink CDC中使用StartupOptions.latest()启动作业通常不会有问题,因为这会让作业从最新的数据源状态开始消费。但是如果使用StartupOptions.specificOffset()指定特定偏移量启动,并出现错误,可能是因为指定的偏移量无效或者超出当前可用的数据范围。
在Flink CDC中,指定特定偏移启动要求确切的源位置,如果这个位置在当前源数据之后或之前不存在,就会导致启动失败。请检查您指定的偏移是否正确,并确保它们存在于数据源中。
有几个可能
1。位点信息不准确:确保提供的Binlog文件名
(scan.startup.specific-offset.file) 和位置
(scan.startup.specific-offset.pos) 或GTID集合
(scan.startup.specific-offset.gtid-set) 是准确且存在于MySQL服务器上的。任何不匹配或无效的位点信息都可能导致启动失败
参考文档:https://help.aliyun.com/zh/flink/developer-reference/mysql-connector
还有可能是表结构变更:如果你尝试从一个特定的位点恢复,且该位点之前的表结构与当前表结构不同,可能会因结构不匹配而导致解析错误
。特别是当表没有主键或者使用了无主键表时,必须正确设置scan.incremental.snapshot.chunk.key-column,且该列不应发生更新操作以保证数据处理的准确性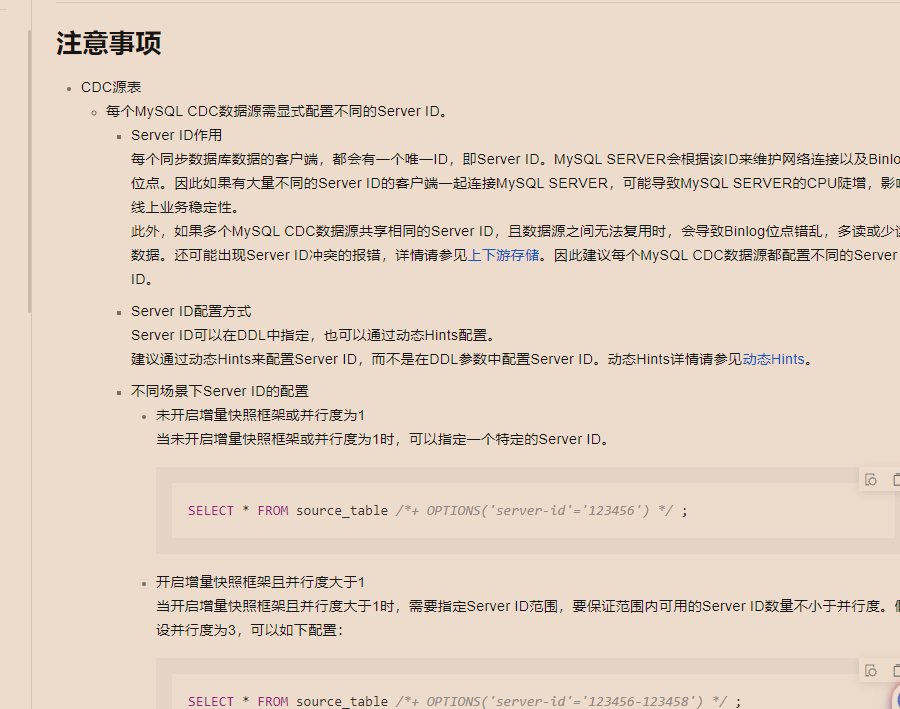
检查 StartupOptions.specificOffset() 的配置是否正确,包括任何必要的时间戳或其他参数。
配置信息传递给 LogProxy 时格式不正确
配置 StartupOptions.latest()
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.connector.source.abilities.StartupMode;
import static org.apache.flink.table.api.Expressions.$;
public class FlinkCdcJob {
public static void main(String[] args) throws Exception {
// 设置执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, EnvironmentSettings.newInstance().build());
// 配置源表,使用 Flink CDC Connector 连接到数据库
String sourceDDL = """
CREATE TABLE my_source_table (
id INT,
data STRING,
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'your-mysql-host',
'port' = '3306',
'username' = 'your-username',
'password' = 'your-password',
'database-name' = 'your-database',
'table-name' = 'your-table'
)
""";
tEnv.executeSql(sourceDDL);
// 设置作业启动模式为从最新的偏移量开始读取
StartupOptions startupOptions = StartupOptions.initial();
// 可以替换为 StartupOptions.latest() 如果只需要捕获新变更的数据
// StartupOptions startupOptions = StartupOptions.latest();
// 使用 SQL 语句创建一个接收数据的 sink 表
String sinkDDL = """
CREATE TABLE my_sink_table (
id INT,
data STRING,
ts TIMESTAMP(3)
) WITH (
'sink' = '...', // 填写你的 sink connector 名称
// ... 其他配置项
)
""";
tEnv.executeSql(sinkDDL);
// 执行 SQL 语句,将数据从源表复制到 sink 表
TableResult result = tEnv.executeSql("INSERT INTO my_sink_table SELECT * FROM my_source_table");
// 等待作业执行完成
result.getJobClient().get().waitForCompletion();
}
}
这可能是由于几个原因导致的:
建议检查并确认:
是否已为表定义了主键,尤其是在需要并行读取的环境中。
specific-offset模式下的偏移量设置是否准确无误。
网络和权限配置是否满足要求,避免SSL相关的异常。
确认scan.startup.mode配置与实际使用的StartupOptions`逻辑相一致。
文件位置信息填的不对吧?
StartupOptions.latest()
从最新的数据开始读取
StartupOptions.specificOffset()
StartupOptions specificOffset(String specificOffsetFile, int specificOffsetPos)
指定一个读取的文件信息,自己指定个任意个位置
使用比较少
参考文档https://www.malaoshi.top/show_1IX3WMCdbfZ6.html
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。