
在Flink CDC中这种双流join爆红怎么调优,如何解决?请参考图片: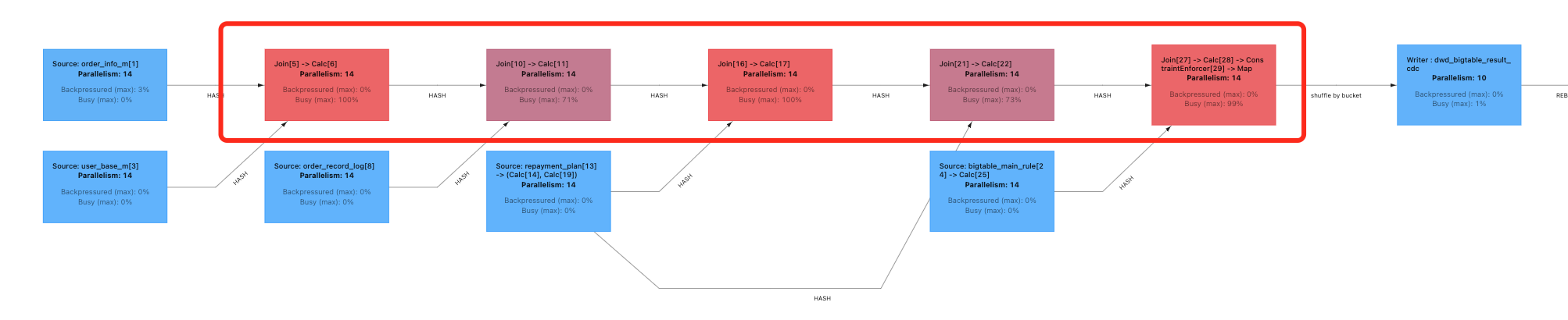
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

针对Flink CDC中双流Join导致的状态膨胀和资源压力问题,可以通过以下策略进行调优与解决:
合理设置JOIN_STATE_TTL Hint:
利用主键优化连接操作:
优化Append-Only流的去重:
改进聚合查询性能:
调整多流Join顺序:
理解状态算子的产生与管理:
通过上述方法,可以有效应对Flink CDC双流Join中遇到的状态膨胀问题,减少资源消耗,提升作业性能。
相关链接
SQL作业大状态导致反压的调优原理与方法 调优方法 https://help.aliyun.com/zh/flink/use-cases/control-state-size-to-prevent-backpressure-in-sql-deployments
在 Flink CDC 中处理双流 Join(两个来自不同数据源的流进行 Join 操作)时,确实可能会遇到性能瓶颈,尤其是在处理大量数据和高并发场景下。您提到的调优策略是非常有针对性的,下面我将进一步解释这些策略以及它们如何帮助提升性能。
配置方式:通过设置 table.exec.join.kv-separate 为 FORCE 来强制开启 KV 分离。这个配置告诉 Flink 在执行 Join 操作时,尽量将 Key 和 Value 分开存储和处理,以减少内存占用和提高处理速度。
设置合适的 Checkpoint 间隔:通过调整 execution.checkpointing.interval 参数,可以在延迟和容错之间找到平衡。较长的间隔可以减少 Checkpoint 对性能的影响,但也会增加数据丢失的风险(在发生故障时)。
配置 MiniBatch:通过设置 table.exec.mini-batch.enabled 为 true 来启用 MiniBatch,并通过 table.exec.mini-batch.allow-latency 来控制允许的额外延迟。这个配置允许 Flink 在一定程度上牺牲延迟来换取更高的吞吐率。
综合考虑
在调优 Flink CDC 中的双流 Join 性能时,需要综合考虑上述策略,并根据具体的应用场景和性能要求进行调整。此外,还可以通过以下方式进一步优化:
优化 Join 条件:确保 Join 条件尽可能高效,避免使用高成本的函数或计算。
调整并行度:通过调整 Flink 作业的并行度来更好地利用集群资源。
监控和日志:使用 Flink 的监控和日志功能来实时跟踪作业的性能指标,及时发现并解决问题。
最终,调优是一个迭代的过程,需要不断地尝试和调整,直到找到最适合当前应用场景的配置。
Flink CDC中双流Join导致的性能问题,可以尝试以下调优策略:
开启KV分离优化:对于Gemini StateBackend,自动推导并开启KV分离优化,提升双流Join性能。可以通过配置table.exec.join.kv-separate来控制,设置为FORCE强制开启。
资源优化:增加JobManager和TaskManager的CPU和内存,以应对高并发和复杂拓扑。
调整Checkpoint间隔:设置合适的execution.checkpointing.interval以平衡延迟和容错。
开启MiniBatch:使用table.exec.mini-batch.enabled和table.exec.mini-batch.allow-latency来减少State访问,提升吞吐。
确保您的Flink版本支持这些优化,并参考配置作业运行参数进行设置。
针对Flink CDC中双流join导致的状态大小膨胀(爆红)问题,可以从以下几个方面进行调优:
合理设置JOIN_STATE_TTL Hint: 通过设置合适的JOIN_STATE_TTL提示,可以有效管理状态的生命周期。例如,将左流的保存周期缩短至12小时,而右流保持18天,这样在保证数据完整性的同时,减少了状态的大小
利用主键优化连接操作:
确保在建表DDL中声明主键,并在双流连接时优先使用主键。当连接键包含主键时,系统会使用ValueState存储,仅保留每个键的最新记录,极大节省存储空间
若连接非主键字段,系统将使用MapState存储所有相关记录,这会占用更多资源。因此,尽可能使用主键进行连接是优化的关键。
优化去重操作: 使用ROW_NUMBER函数替代FIRST_VALUE或LAST_VALUE进行去重,能更高效地处理数据,减少不必要的状态存储
改进聚合查询: 利用AGG WITH FILTER语法替换CASE WHEN,以共享状态信息,减少状态读写,从而提升聚合查询性能,尤其是在多维度统计场景下
官网给的调优方案:
根据集群资源和任务需求,适当调整 parallelism 参数。在您提供的信息中,Parallelism: 10 可能不是最优设置,可以根据任务负载进行调整。
根据数据特性选择合适的 Join 类型,例如:如果数据量不大,可以使用 broadcast join。
调整状态后端:
如果使用状态后端(如 RocksDB),调整状态后端的配置,例如:设置合理的 state.time-to-live 参数,减少状态大小。
两种解决思路:
减少状态大小:在 Flink Join 中的有效的优化措施就是减少 state key 的数量。在未优化之前 A 流和 B 流的数据往往是存储在单独的两个 State 实例中的,优化思路就是将同 Key 的数据放在一起进行存储,一个 key 的数据只需要存储一份,减少了 key 的数量。
转移状态至外存:大 State 会导致 Flink 任务不稳定,就将 State 存储在外存中,让 Flink 任务轻量化,比如将数据存储在 Redis 中,A 流和 B 流中相同 key 的数据共同维护在一个 Redis 的 hashmap 中,以供相互进行关联。
——参考链接。
1.爆红通常指的是算子或步骤的执行时间过长,导致整个作业的进度变慢或停滞。双流join操作涉及两个数据流的合并,涉及到大量的数据匹配和转换。如果数据量很大,或者数据的结构复杂,那么join操作的效率就会降低,导致爆红。
我们首先创建了两个DataFrame,然后使用pandas的merge函数进行了双流join操作。这个函数会自动识别两个DataFrame中相同的列,并进行数据匹配。输出结果应该是一个包含两组数据(来自df1和df2)的DataFrame。
```
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


