
DataWorks比较源CSV和目标表时,列的顺序不同。
这就是为什么需要映射每一列。但在没有映射列的情况下,我在运行时甚至单击“带参数运行”时都会出错,因为不同的列顺序彼此不同?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
可以手动修改映射关系 或者 转脚本模式以后 再调整column列表里的字段顺序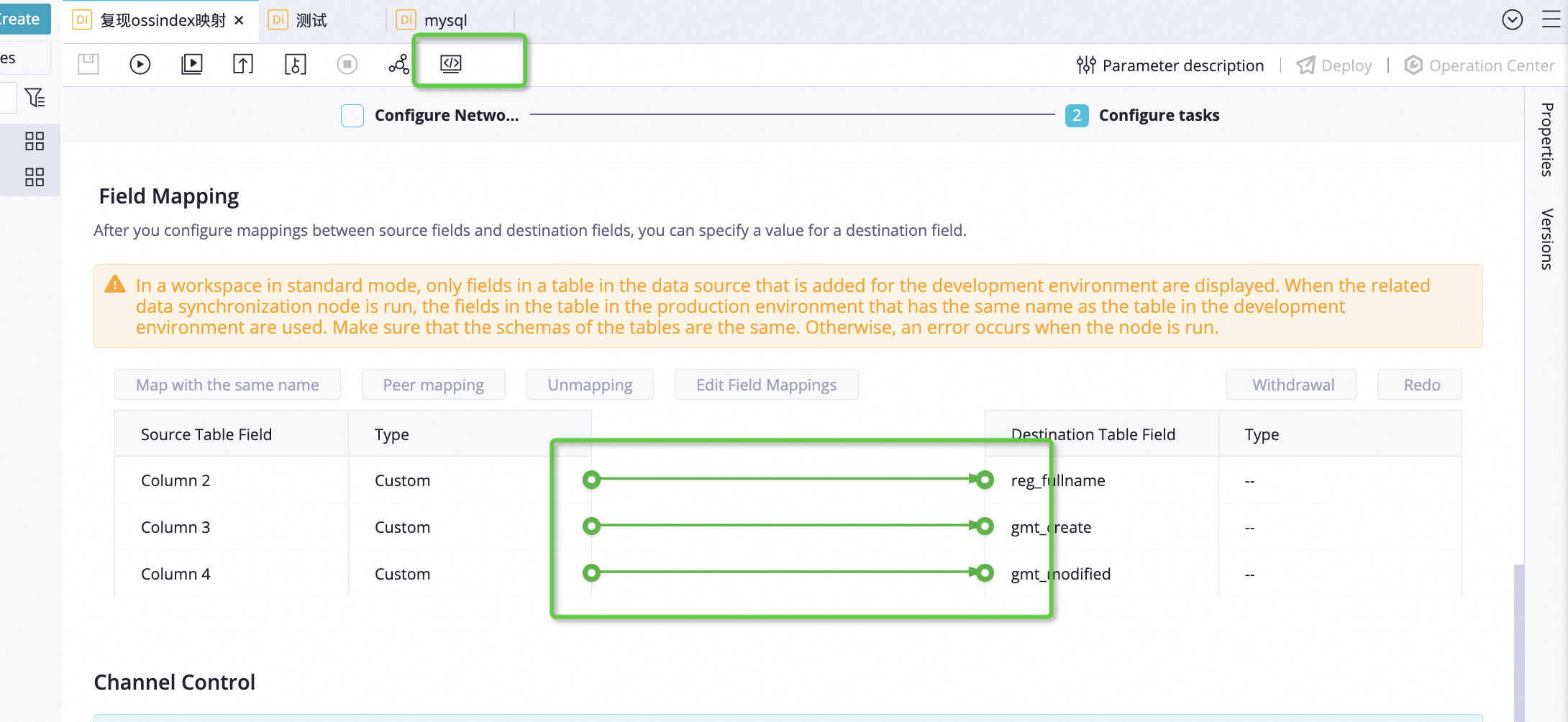
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
是的,当你在DataWorks中进行数据同步任务时,如果源CSV文件的列顺序与目标表的列顺序不一致,这会导致数据加载失败,因为系统默认按照列的位置进行一一对应的数据写入。即使字段名称相同,但顺序不同,也会造成数据错位的问题。
为了解决这个问题,你需要在DataWorks的数据同步任务配置中明确指定源列和目标列之间的映射关系,确保每个源列都正确地对应到目标表的相应列上。以下是进行映射的一般步骤:
进入数据同步任务的配置界面:在DataWorks的工作流中,找到你的数据同步任务并进入其配置页面。
选择源表和目标表:在任务配置的起始处,你已经定义了源数据和目标数据的位置。确认源CSV文件路径和目标数据库表名是否正确。
列映射设置:在“字段映射”或“列映射”部分,系统通常会自动尝试按照列名匹配,但因为你的列顺序不同,所以需要手动调整。这里,你可以看到源表的所有列和目标表的所有列。通过拖拽或下拉选择等方式,为每个目标列选择正确的源列。
检查映射:确认所有的目标列都已经从源列中正确选择,并且顺序与目标表的期望顺序一致。
保存并测试:保存配置后,可以先进行一次“预检查”或“测试同步”,以验证列映射是否正确无误,这可以帮助你在正式运行前发现并修正问题。
运行任务:一旦列映射设置正确并通过测试,就可以正式运行数据同步任务了。
通过上述步骤,即便源CSV文件和目标表的列顺序不同,你也能确保数据能够正确无误地加载到目标表中。
列映射确保数据的一致性,防止因为列顺序不同而导致的数据错误或数据丢失。
目标表的某些列可能有特定的约束条件,如非空、唯一或外键约束。错误的列映射可能导致这些约束被违反。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


