
DataWorks用tunnel导入数据,cat文本文件,可以看到中文,但在dw界面里看到的是方块?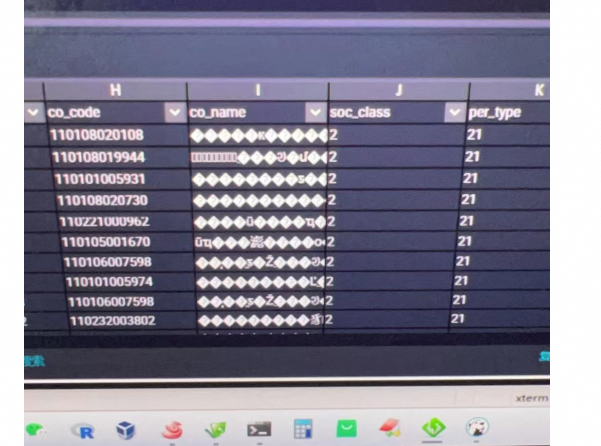
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到在DataWorks中使用Tunnel命令导入数据后,通过cat命令查看文本文件时中文显示正常,但在DataWorks界面中显示为方块(乱码)的情况,通常是字符编码不匹配导致的。以下是解决此问题的几个步骤:
首先,确认你的文本文件的编码格式。如果是UTF-8编码,那么在大多数情况下,DataWorks应该能正确识别。你可以使用如file -i yourfile.txt(在Linux环境下)命令来检查文件的编码,或者使用文本编辑器查看。
DataWorks的Tunnel命令本身不直接支持指定文件编码,但是确保在创建表或上传数据时,表的字符集设置与文件的编码一致是非常重要的。默认情况下,MaxCompute(原名ODPS)的表字符集为UTF-8。
虽然这种情况比较少见,但有时浏览器或DataWorks界面本身的字符集设置也可能影响中文的显示。确保你的浏览器设置支持并优先使用UTF-8编码显示网页内容。
如果你在创建表或使用Tunnel上传数据时没有明确指定字符集,而且数据源文件确实使用了非默认(如GBK)编码,你可能需要先将数据转换为UTF-8编码再上传。这可以通过命令行工具(如iconv)完成,或者在数据上传前的ETL过程中加入编码转换的步骤。
如果你确定文件是GBK编码,可以使用以下命令将其转换为UTF-8:
iconv -f GBK -t UTF-8 yourfile.txt -o yourfile_utf8.txt
之后,使用转换后的文件上传至DataWorks。
如果上述方法都无法解决问题,且确认数据库表的字符集不匹配,理论上MaxCompute(ODPS)的表字符集一旦创建就不可更改,但这非常罕见。一般建议在创建表时就正确指定字符集,或重新创建表以匹配数据文件的编码。
大多数情况下,确保文件本身的编码与MaxCompute表的预期编码(通常为UTF-8)一致,是解决乱码问题的关键。如果问题依旧,检查数据导入流程中的每一步,包括数据准备、上传和最终展示的环境设置,都是排查问题的有效途径。
遇到在DataWorks使用tunnel导入数据时,中文显示为方块(乱码)的问题,通常是因为字符编码不匹配导致的。以下是一些可能的解决步骤:
检查文件编码:
file -i your_file.txt(Linux命令)或者Notepad++等文本编辑器查看文件编码。设置正确的字符集:
数据库字符集一致性:
SHOW CREATE TABLE your_table;来查看表的字符集设置,必要时可使用ALTER TABLE your_table CONVERT TO CHARACTER SET utf8mb4;来更改字符集。DataWorks界面编码设置:
使用DataX任务配置:
encoding参数,例如: <parameter>
<property>
<name>encoding</name>
<value>UTF-8</value>
</property>
</parameter>
日志检查:
预处理数据:
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


