
有大佬自定义过ScanTableSource,如果让其只支持批处理模式。我的上游是一个api接口。现在启动报了一个错?:Querying an unbounded table 'default_catalog.default_database.test1' in batch mode is not allowed. The table source is unbounded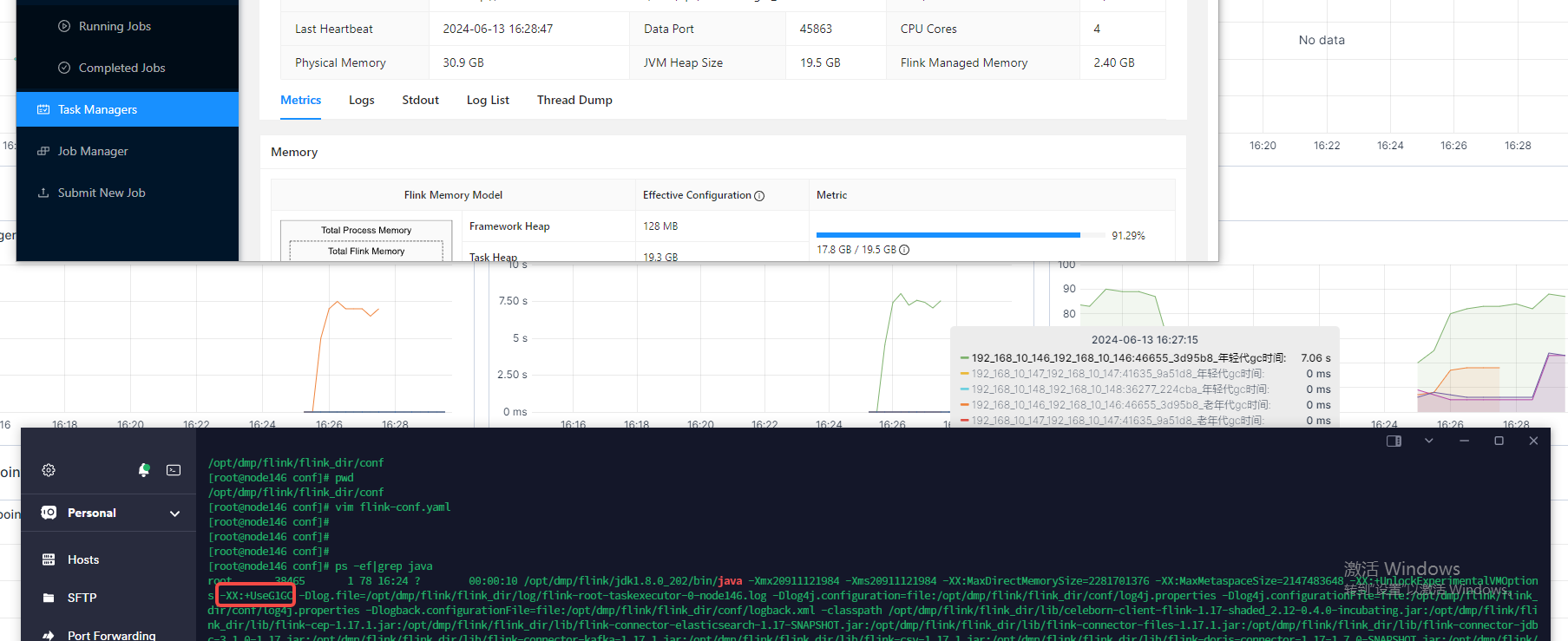
source读取很快就把堆占满了 导致GC超时 tm 心跳丢失 这个问题有处理办法么 ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
关于自定义ScanTableSource以支持批处理模式,若要使其仅支持批处理模式,您可以重写isBounded()方法返回true,并确保scan()方法返回一个BatchTableSource实例而不是StreamTableSource。这样,Flink将能正确识别该表源为批处理模式,遇到的“Querying an unbounded table in batch mode is not allowed”错误,这表明尝试在批处理作业中查询一个不支持批处理的流式表源。要解决这个问题,您需要确保您的表源是有界的,并且正确实现了批处理模式所需的方法和返回类型,还有有Flink的批处理模式专注于处理有界数据集,并且重点在于提供高吞吐量的数据处理。在这种模式下,作业通常由多个阶段组成,这些阶段可以并行执行以提高资源利用率。而流处理作业则需要预先分配所有资源,以确保所有子任务能够同时部署并运行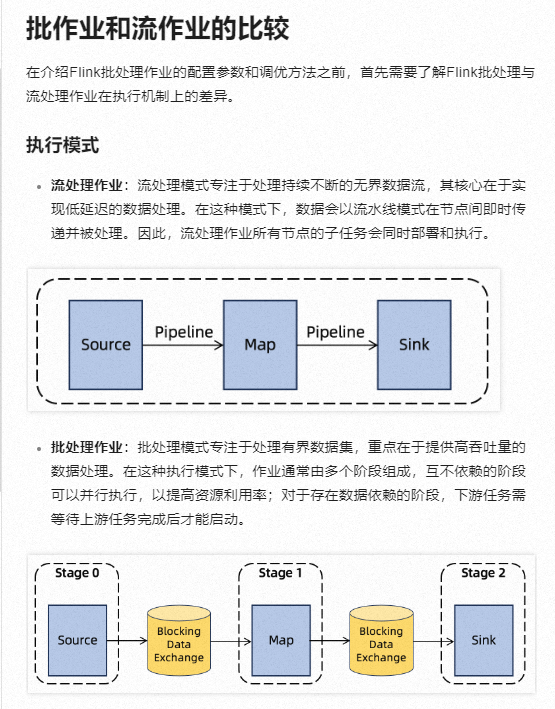
根据你提供的信息似乎你的ScanTableSource正在返回一个无限流(unbounded stream),这导致了错误:"Querying an unbounded table 'default_catalog.default_database.test1' in batch mode is not allowed. The table source is unbounded."要解决这个问题,请确保你的ScanTableSource实现正确地限制了数据量或时间范围,以使其成为有限的(bounded)数据源。你可以通过以下方式来做到这一点:
限制查询结果的数量:
确保你的API接口有一个参数可以用来限制返回的结果数量。然后,在你的ScanTableSource实现中使用这个参数来限制结果的数量。
基于时间范围进行限制:
如果你的API接口是基于时间戳进行查询的,那么请确保你的ScanTableSource实现能够接受一个时间范围作为输入,并将此范围传递给API请求。
分页处理:
如果你的API接口不提供直接的限制方法,你可以考虑使用分页机制。每次调用API时,只获取一定数量的结果,然后在下一次迭代中继续获取剩余的结果,直到达到预期的限制。
TaskManager 设置了合适的内存大小。可以通过 -Xmx 和 -Xms 参数设置 JVM 堆内存。
可以通过调整 JVM 的 GC 参数来优化垃圾收集性能,例如使用 G1 垃圾收集器并调整相关参数:
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=32M
检查 ScanTableSource 是否有优化空间,比如限制每次读取的数据量。
TM心跳丢失:TM(Task Manager)心跳丢失意味着任务管理器与任务节点之间的通信中断,可能导致任务无法正常执行或数据同步出现问题。解决此问题的方法可能包括检查网络连接,确保消息队列的正常运行,或者调整心跳间隔和重试机制
您提到的Flink CDC(Change Data Capture)导致GC超时、TM心跳丢失以及自定义ScanTableSource相关问题,可能是指在Flink生态系统中的一些特定场景或配置问题。以下是对这些问题的简要分析和可能的解决方法:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。




