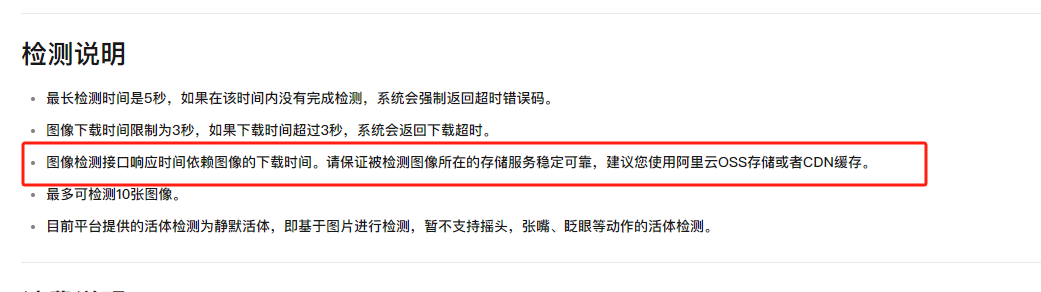
在视觉智能平台中人脸活体检测的接口,如何调高活体识别率?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在视觉智能平台中调高人脸活体检测接口的活体识别率,可从以下方面着手:
优化输入图像质量
保证图像清晰:确保输入的人脸图像分辨率足够高且清晰,避免模糊、噪点多的图像,可参考平台对图像分辨率的要求,如阿里云视觉智能平台建议图像分辨率大于256x256像素。
控制光照条件:避免过强或过弱的光线,防止阴影或反光影响人脸特征提取,尽量选择光线均匀、柔和的环境拍摄人脸图像。
规范人脸姿态:要求人脸在图像中保持正脸姿态,尽量减少侧脸、仰头、低头等大幅度姿态变化,以利于准确提取人脸特征。
合理配置接口参数
选择合适算法版本:使用平台推荐的最新算法模型版本,通常新版本在活体识别准确率上有优化,如腾讯云人脸静态活体检测建议使用“3.0”版本。
调整置信度阈值:根据业务需求和实际测试情况,在平台允许范围内适当调整置信度阈值。若误判率较高,可提高阈值;若漏判率较高,可降低阈值,但需经充分测试找到平衡点。
进行数据增强与校准
数据增强:对训练数据进行多样化处理,如旋转、翻转、添加噪声等,增加数据的丰富性,让模型学习到更多不同姿态和光照条件下的人脸特征,提高模型的泛化能力。
定期校准:定期使用已知活体和非活体的样本对模型进行校准和评估,及时发现模型性能下降的情况并进行调整优化。
结合多模态信息
如果平台支持,可结合人脸的多种特征信息,如红外图像、深度信息等多模态数据进行活体检测。多模态信息能提供更丰富的特征,有助于提高活体识别的准确率。