DataWorks像这种mapjoin构建hash table时间过长,有什么优化方向吗?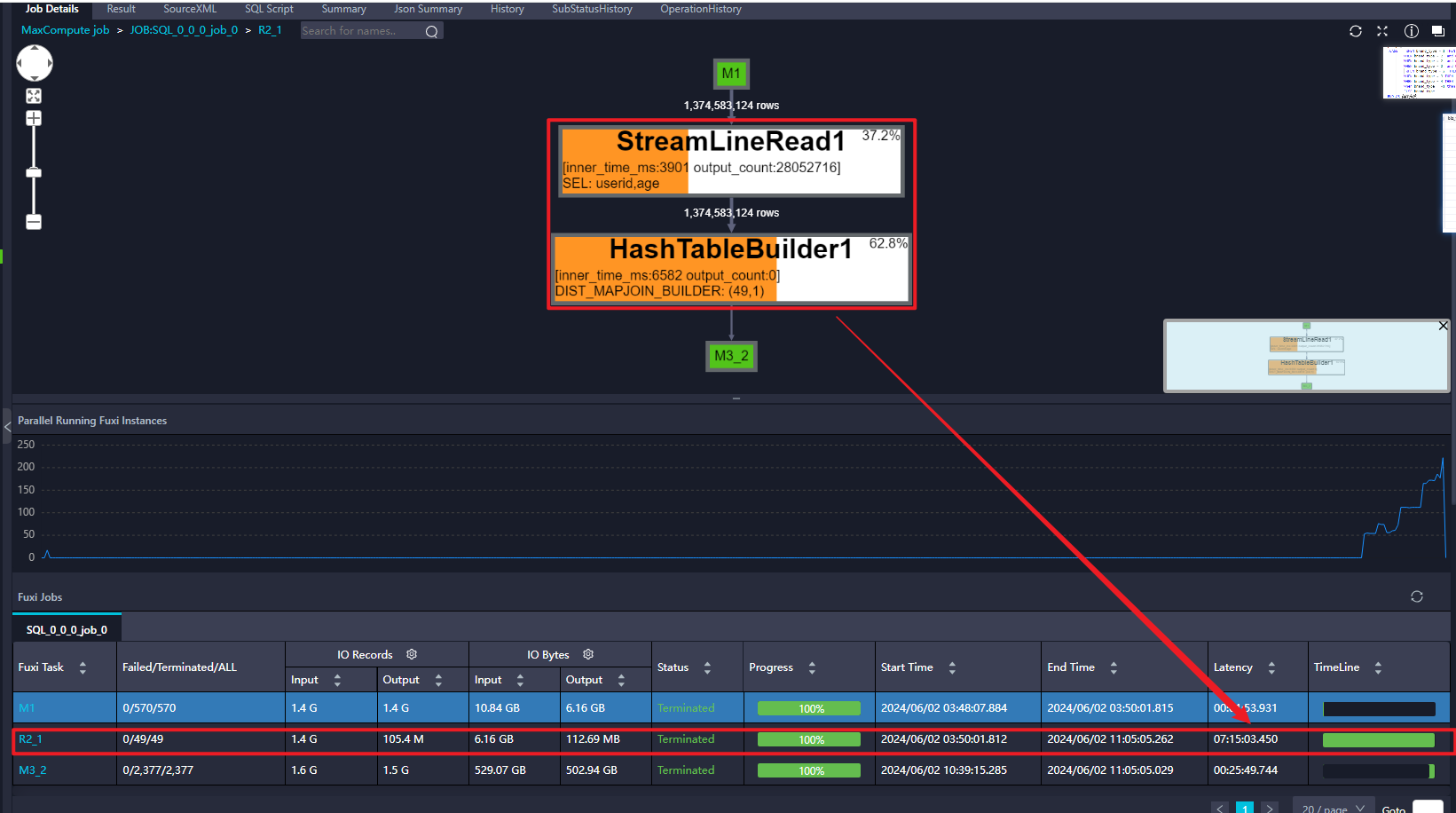
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
优化SQL语句
减少参与Join的列数:只保留必要的列参与MapJoin,减少不必要的数据处理。
使用过滤条件:在MapJoin之前尽可能使用WHERE子句过滤数据,减少参与Join的行数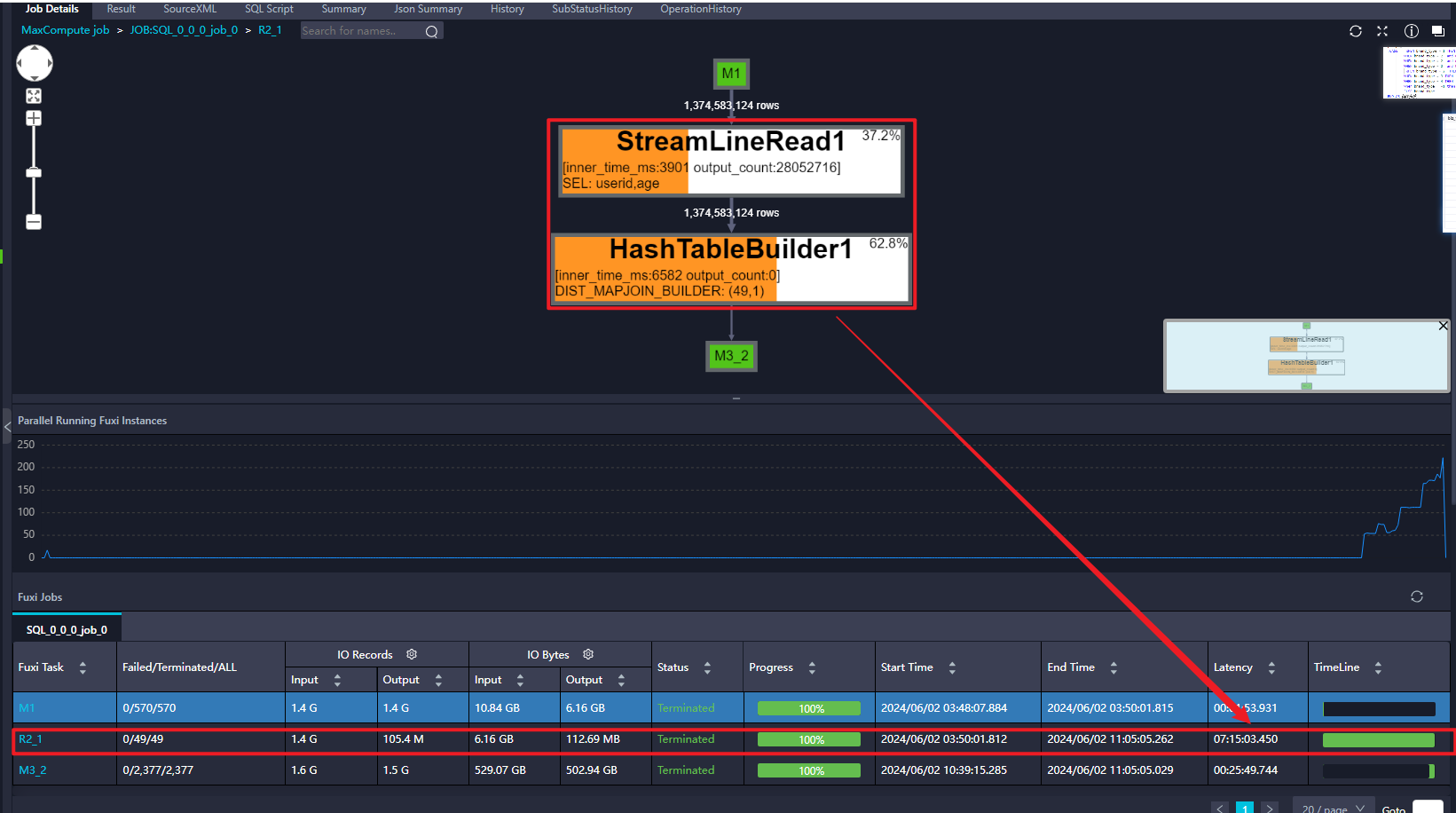
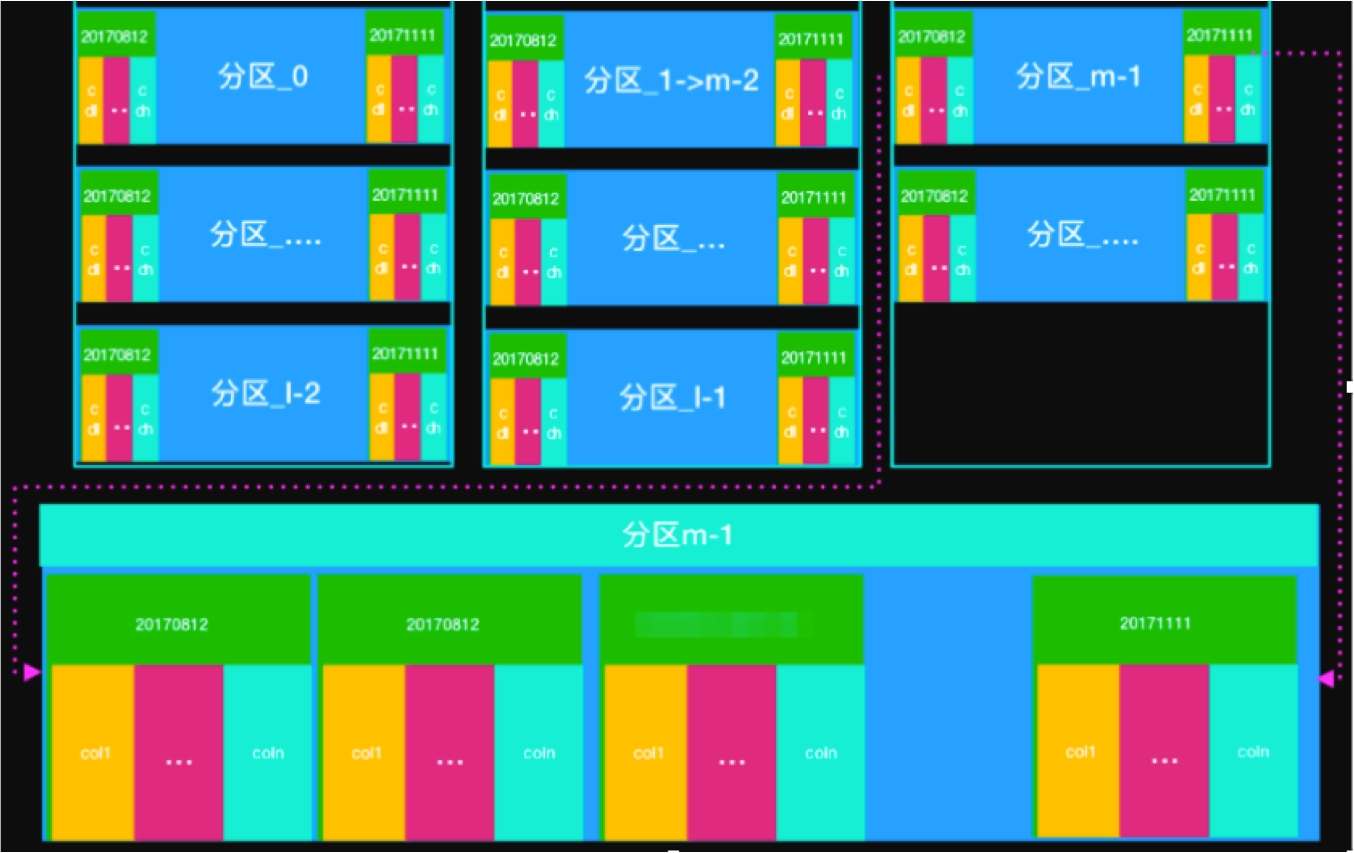
分区设计是大数据处理中优化查询性能和简化数据管理的重要手段。以下是对您提供内容的总结和补充,以便更好地理解和应用分区设计:
DataWorks中,MapJoin是一种高效的大表与小表的连接方式,通过在Map阶段将小表整个加载到内存中,以减少数据传输和加快连接速度。然而,当构建哈希表的时间过长时,就需要采取一系列优化措施来提升性能。具体分析如下:
确保小表足够小
检查小表大小:MapJoin要求小表远小于大表,如果小表过大,可能不适合使用MapJoin。
考虑使用采样:对于较大的小表,可以通过采样减少数据量,使其适合MapJoin操作。
优化表的分布
使用分区表:分区表可以显著减少MapJoin操作需要处理的数据量,从而提高性能。
确保数据均匀分布:避免数据倾斜,确保数据均匀分布在各个分区或桶中。
调整并行度
增加并行度:适当增加并行度可以分散构建哈希表的压力,但要避免过度增加导致资源浪费。
使用合适的Join策略
考虑其他Join策略:如果MapJoin的哈希表构建时间过长,可以考虑使用Broadcast Join或Shuffle Join等其他策略。
优化SQL语句
减少参与Join的列数:只保留必要的列参与MapJoin,减少不必要的数据处理。
使用过滤条件:在MapJoin之前尽可能使用WHERE子句过滤数据,减少参与Join的行数。
调整MapReduce参数
调整MapReduce参数:根据具体情况调整MapReduce的参数,以优化MapJoin的性能。
使用物化视图
创建物化视图:如果经常进行相同的MapJoin操作,可以通过创建物化视图预先计算结果,减少MapJoin的使用。
数据预处理
数据预处理:对数据进行预处理,如排序或聚合,以减少MapJoin的负担。
检查数据类型
确保数据类型一致:避免参与MapJoin的列因数据类型不一致而产生额外的类型转换开销。
使用索引
建立索引:虽然MaxCompute不支持传统意义上的索引,但在某些场景下可以考虑使用类似于索引的预处理技术来加速查询。
利用中间表
适用于数据量非常大的表:如果下游任务很多,可以利用中间表来优化数据处理流程。
拆表和合表
拆表:对于产出极慢的个别字段,可以将字段拆分为单独的表。
合表:针对业务重叠或重复的表,可以进行任务和数据合并,以简化数据处理。
此外,在进行上述优化时,还应注意以下几点:
避免在资源限制较为严格的环境下使用资源密集型的Distributed MapJoin,以免造成系统不稳定。
在进行MapJoin时,应严格遵循表设计规范,以确保数据的准确性和查询的效率。
如果存在数据倾斜问题,可以通过增加分区数或采用采样倾斜键后重新分布数据的方法来平衡负载。
总的来说,在DataWorks中使用MapJoin时,构建哈希表时间过长的问题可以通过多种方法进行优化。这些方法包括确保小表足够小、优化表的分布、调整并行度、使用合适的Join策略、优化SQL语句、调整MapReduce参数、使用物化视图、数据预处理、检查数据类型、使用索引以及利用中间表、拆表和合表等技巧。在实施这些优化措施时,还应考虑到环境因素和数据特性,以确保优化效果的最大化。
在DataWorks中使用MapJoin构建哈希表时间过长,主要涉及到大数据处理和优化的问题。MapJoin是一种常用的大数据计算模式,它通过在Map阶段就进行join操作来加快查询速度,特别是对于大表与小表之间的join操作非常有效。然而,如果构建哈希表的时间过长,将严重影响性能。以下是一些优化方向的建议:
确保小表足够小
检查小表大小:MapJoin的基本要求是一小一大两个表,其中小表应远小于大表。如果小表数据量过大,它将无法全部加载到内存中,导致构建哈希表缓慢。
使用采样或分割:如果小表仍然相对较大,可以考虑对小表进行采样或者分割后再进行MapJoin操作。这样可以减少数据量,加快哈希表的构建速度。
优化表的分布
使用分区表:如果可能,使用分区表可以显著减少MapJoin的哈希表构建时间。分区可以使得查询时只扫描相关的部分数据,而不是全表扫描。
确保数据均匀分布:检查数据是否均匀分布在各个分区或桶中,避免数据倾斜。数据倾斜会导致某些节点处理的数据过多,从而增加构建哈希表的时间。
调整并行度
增加并行度:通过增加并行度可以分散构建哈希表的压力,提高整体任务的执行效率。但要注意不要过度增加并行度,以免造成资源浪费。
根据资源调整并行度:根据集群资源和任务需求合理设置并行度。这需要综合考虑CPU、内存等资源的限制以及当前集群的负载情况。
使用合适的Join策略
考虑其他Join策略:如果MapJoin的哈希表构建时间过长,可以考虑使用其他Join策略,如Broadcast Join或Shuffle Join。这些策略在不同的场景下可能会有更好的表现。
优化SQL语句
减少参与Join的列数:尽量减少参与MapJoin的列数,只保留必要的列,这样可以减轻数据传输和处理的负担。
使用过滤条件:在MapJoin之前,尽可能使用WHERE子句过滤数据,减少参与Join的行数,这样可以减少哈希表的大小,提高构建速度。
调整MapReduce参数
调整MapReduce参数:根据具体情况调整MapReduce的参数,如mapreduce.job.reduce.slowstart.completedmaps,以优化MapJoin的性能。这些参数调整可以帮助更好地利用资源,提升任务执行效率。
使用物化视图
创建物化视图:如果经常进行相同的MapJoin操作,可以考虑创建物化视图来预先计算结果,从而减少MapJoin的使用。物化视图可以加速查询,特别是对于重复的查询模式。
数据预处理
数据预处理:对数据进行预处理,例如排序或聚合,以减少MapJoin的负担。预处理可以使得数据更加有序,从而加快哈希表的构建速度。
检查数据类型
确保数据类型一致:确保参与MapJoin的列具有相同的数据类型,以避免类型转换带来的开销。数据类型不一致会增加额外的计算负担。
使用索引
建立索引:虽然MaxCompute不支持传统意义上的索引,但在某些场景下可以考虑使用类似于索引的预处理技术来加速查询。比如,通过对关键列进行排序或者创建值到行的映射关系,来实现快速定位。
利用中间表拆表合表
中间表的利用:适用于数据量非常大且下游任务很多的表。中间表可以减少每次处理的数据量,从而优化性能。
拆表:适用于个别字段产出极慢的情况。将字段拆分为单独的表,可以有针对性地优化这些字段的处理过程。
合表:随着数仓的发展,针对业务重叠或重复的表,可以进行任务和数据的合并,以减少存储和计算的负担。
合理利用拉链表
拉链表的使用:合理利用拉链表能减少存储消耗并加快查询速度。拉链表适用于历史数据的处理,能够有效管理数据变更。
此外,还需要从其他方面考虑进一步的优化措施:
日志分析:查看MapJoin操作的日志,分析是否有详细的错误信息或异常记录,有助于定位具体的问题源头。
性能考虑:MapJoin操作会占用较多的内存和CPU资源,确保集群的性能充足,特别是在高并发场景下。
第三方工具和平台的利用:如果依赖于第三方平台或工具进行数据处理和分析,也需要确认这些工具对MapJoin的支持情况。
备份与恢复:在进行相关配置更改前,备份当前的配置和重要数据,以防修改后出现其他问题可以快速恢复。
总的来说,通过上述多个方面的优化措施,通常能够有效减少DataWorks中MapJoin构建哈希表的时间,从而提升整体数据处理的效率。结合具体的数据特点和业务需求,逐一排查和调整这些设置,是确保优化效果的关键。
你这个构建时间是挺久的啊
评估map表的大小,如果数据量非常大,考虑是否可以对其进行抽样或分割,另外可以对大表进行合理的分区,可以减少MapJoin操作中需要处理的数据量。
还有如果map表足够小,可以考虑使用广播Join(broadcast join),让每个reduce任务都持有map表的副本。
在 DataWorks 中使用 MapJoin 时,如果构建哈希表的时间过长,这可能是由于多种原因造成的。MapJoin 通常用于加快查询速度,尤其是在处理大型数据集时,但有时候构建哈希表的过程可能会变得缓慢。以下是一些优化方向:
mapreduce.job.reduce.slowstart.completedmaps,以优化 MapJoin 的性能。表的其他优化技巧
建议您严格遵循表设计规范。此外,您还可以利用下列技巧完成表的优化:
中间表的利用:适用于数据量非常大,下游任务很多的表。
拆表:适用于个别字段产出极慢的情况,您可以将字段拆分为单独的表。
合表:随着数仓的发展,针对业务重叠或重复的表,您可以进行任务和数据合并。
拉链表:合理利用拉链表能减少您的存储消耗,关于拉链存储的详情请参见拉链存储。
利用MaxCompute表的特殊功能:详情请参见MaxCompute表的高级功能。
表设计规范:https://help.aliyun.com/zh/maxcompute/use-cases/table-design-specifications?spm=a2c4g.11186623.0.0.4b5878caQRIN2v#concept-226512
表设计最佳实践 :https://help.aliyun.com/zh/maxcompute/use-cases/best-practices-for-table-design?spm=a2c4g.11186623.0.0.4b5878caQRIN2v#concept-226662
将大表进行合理的分区
增加DataWorks集群的内存资源
独享资源组模式下,机器的物理资源(网络、磁盘、CPU和内存等)完全独享。独享资源组模式的作用如下:
支持隔离不同用户间的资源使用。
支持隔离不同工作空间任务的资源使用。
支持扩容、缩容功能,可以满足资源独享、灵活配置等需求。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。