
请教一下Flink lookup join的表使用starrocks表合适吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 中的 lookup join 是一种特殊的 join 操作,用于将流数据与外部系统(如数据库、键值存储或搜索引擎)中的静态或缓慢变化的数据进行关联。在使用 lookup join 时,你需要考虑数据存储的性能、延迟、一致性和并发访问能力。
StarRocks 是一个面向在线分析处理(OLAP)的列式数据库,它优化了针对大数据的复杂查询,并且具有高性能和低延迟的特点。
以下是考虑使用 StarRocks 作为 Flink lookup join 表的一些因素:
性能:StarRocks 专为高速查询而设计,如果 lookup join 的表数据量较大,且查询性能要求高,StarRocks 可能是一个合适的选择。
并发访问:如果你的 Flink 作业需要高并发地访问 lookup 表,StarRocks 的分布式架构能够提供较好的并发支持。
数据一致性:StarRocks 支持强一致性读,这对于需要准确结果的 lookup join 是很重要的。
实时更新:如果你的 lookup 表数据需要实时更新,StarRocks 的实时数据更新能力可以满足这一需求。
集成和连接器:你需要确保有可用的 Flink StarRocks 连接器或者可以通过自定义实现来与 StarRocks 进行交互。Flink 社区可能提供了与 StarRocks 集成的连接器,或者你可以自己实现。
延迟:对于流处理而言,延迟是一个关键指标。StarRocks 的低延迟特性使其成为流处理的合适选择,尤其是在 lookup join 场景下。
成本:部署和维护 StarRocks 集群可能会有一定的成本,你需要评估是否值得为了 lookup join 的性能而投入这些资源。
总的来说,如果以下条件满足,使用 StarRocks 作为 Flink lookup join 的表是合适的:
你需要高性能和低延迟的查询。
Lookup 表的数据量大,且查询复杂。
你可以接受 StarRocks 的部署和维护成本。
存在可用的 Flink 连接器或你可以实现自定义连接器。
不过,在做出决定之前,建议进行一些基准测试和性能评估,以确保 StarRocks 能够满足你的具体需求。同时,也要考虑数据的更新频率、一致性要求以及整个系统架构的兼容性。
Flink Lookup Join操作非常适合与StarRocks表结合使用。StarRocks是一个高性能的分析型数据库,特别优化了OLAP查询场景,支持高并发和低延迟查询。在Flink SQL作业中,当您需要执行Lookup Join操作,尤其是涉及到维表查询且追求高效性能时,StarRocks连接器的引入可以带来显著优势。
使用StarRocks作为Flink Lookup Join的维表来源时,应确保您的实时计算引擎版本支持StarRocks Catalog的配置,至少需要VVR-6.0.6-Flink-1.15及以上版本。此外,虽然StarRocks连接器增强了对多种数据类型的支持,包括JSON类型,以及在连接器层面进行了性能优化,但在实际应用中还需根据具体业务需求和数据规模,合理配置连接器参数和优化Join策略,比如利用支持自定义Partitioner来提高数据处理效率
Flink的lookup join适合用于访问静态或者更新不频繁的数据,如果StarRocks表的数据更新频率不高且能被Flink缓存,可以考虑用于lookup join。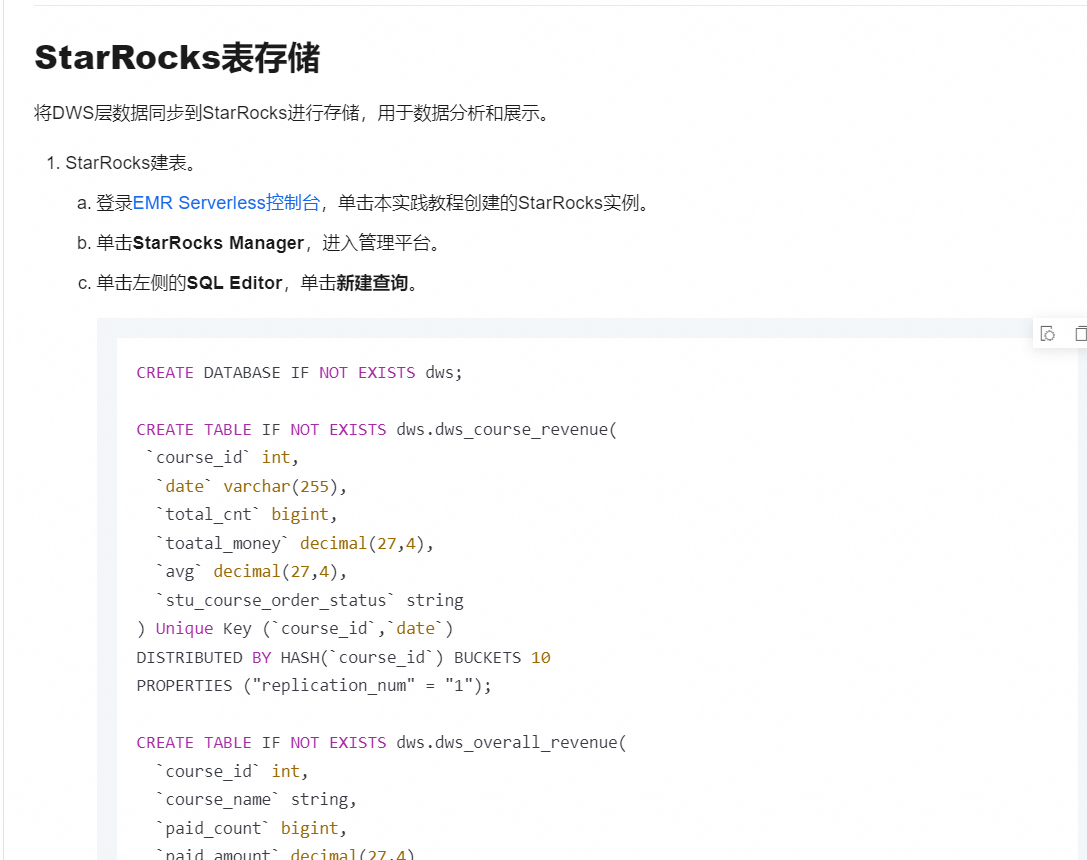
你可以试试,StarRocks是在需要处理动态变化的维表数据场景还是可以的,Flink SQL在执行Lookup Join时,如果维表( Lookup Source )中的数据是动态变化的(例如通过CDC机制捕获变更),引入带有状态的LookupJoin算子可以有效应对
。StarRocks作为一种高性能的分析型数据库,支持高并发查询和实时数据更新,适合作为这类动态维表的存储引擎

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



