Flink有没有大佬尝试写入数据到hudi,存储在本地文件系统的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
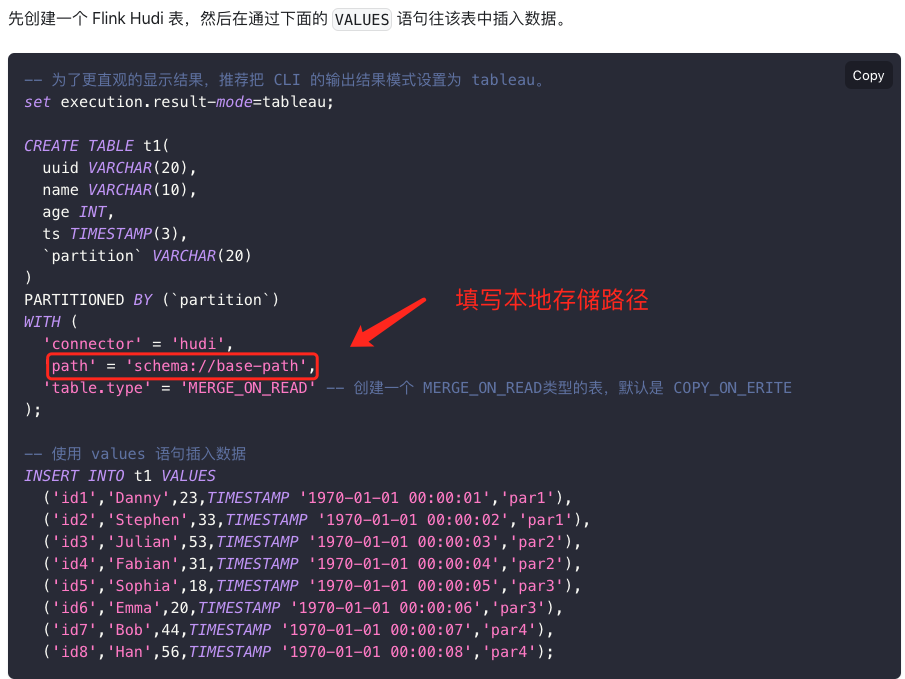
在 Apache Flink 中,可以通过使用 Flink-Hudi 连接器将数据写入 Apache Hudi 表,并存储在本地文件系统中。Apache Hudi 是一个开源的实时数据湖平台,用于高效地管理大规模数据集。使用 Flink-Hudi 连接器,可以将流式数据处理和存储到 Hudi 表中,支持增量更新和查询。
以下是一个示例程序,展示了如何使用 Flink-Hudi 将数据写入 Hudi 表并存储在本地文件系统中。
准备工作
下载 Flink 和 Hudi:
确保你已经下载并配置好了 Apache Flink 和 Apache Hudi。
添加依赖:
如果你使用 Maven 构建项目,需要在 pom.xml 中添加 Flink-Hudi 的依赖。
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_2.12</artifactId>
<version>0.10.0</version>
</dependency>
请根据需要的 Hudi 版本和 Scala 版本进行调整。
示例程序
以下是一个简单的 Flink 应用程序,将数据写入 Hudi 表并存储在本地文件系统中。
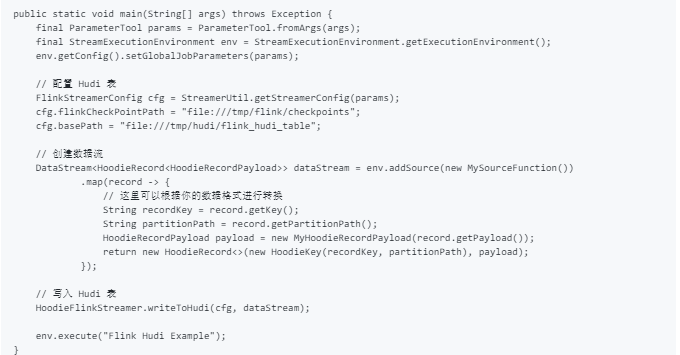
配置参数
在运行上述代码之前,需要配置一些参数,例如 Hudi 表的基本路径和 Flink 的检查点路径。可以通过命令行参数或参数文件进行配置。
flink run -c com.example.FlinkToHudiExample /path/to/jarfile.jar \
--base-path file:///tmp/hudi/flink_hudi_table \
--flink-checkpoint-path file:///tmp/flink/checkpoints
注意事项
检查点路径:确保 Flink 的检查点路径在本地文件系统中是可写的。
Hudi 表路径:确保 Hudi 表的存储路径在本地文件系统中是可写的。
依赖版本:根据 Flink 和 Hudi 的版本选择合适的依赖版本和配置。
通过以上示例代码和配置,您应该能够将数据通过 Flink-Hudi 连接器写入 Hudi 表,并将数据存储在本地文件系统中。如果遇到问题,可以查看 Flink 和 Hudi 的官方文档,以获取更多详细信息和支持。
要在Flink中配置写入Hudi并将数据存储至本地文件系统,您需要关注以下几个关键点: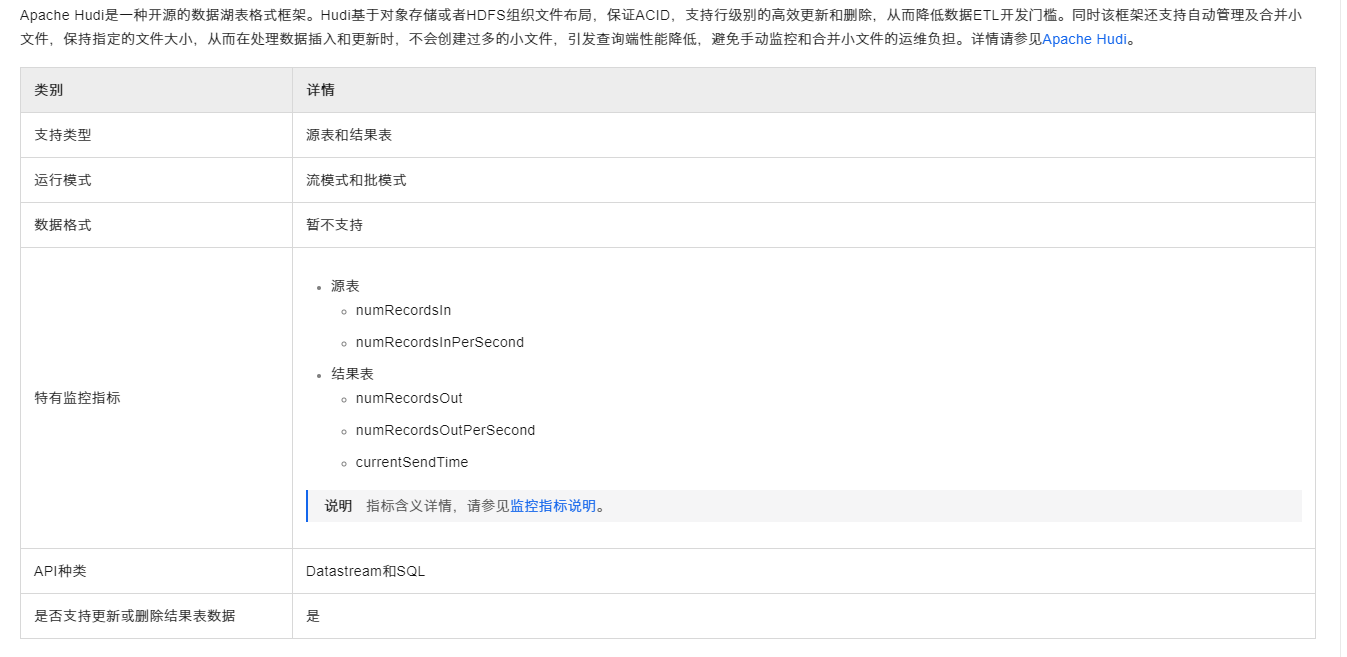
Hadoop配置: 使用hadoop.${you option key}形式的配置项,可以通过Flink传递Hadoop配置,确保Flink能够访问到本地文件系统。例如,如果Hudi需要识别本地文件系统作为存储位置,可能需要适当配置Hadoop的fs.defaultFS属性<
写入模式选择: Flink连接Hudi时,可以通过设置write.operation来指定写入操作类型,如upsert、insert或bulk_insert。这影响着数据如何被写入及更新到Hudi表中
本地路径指定: 在创建或配置Hudi表时,指定表的位置为本地文件系统的路径。例如,表的路径可以被设置为file:///path/to/your/local/hudi/table,确保该路径对运行Flink任务的用户是可写的。
参考连接https://help.aliyun.com/zh/flink/developer-reference/hudi-connector?spm=a2c6h.13066369.question.99.7d2a2dfbLZSjUo#e461ee9114amu
Flink确实可以将数据写入到存储在本地文件系统的Hudi中。要实现这个,您需要配置Hudi的连接器参数,指定Hudi表的本地文件系统路径。例如,您可以在write.path参数中设置本地文件系统的路径。在配置其他参数如write.operation、write.tasks等时,确保Flink作业有权限访问和写入指定的本地路径。可参考 Flink Hudi 数据写入
可以配置写入数据到 Hudi,并且支持数据存储在本地文件系统上。为了实现这一目标,您需要通过 Hudi 的 Flink Connector 进行配置。虽然给出的参考资料未直接提及本地文件系统的存储细节,但 Hudi 和 Flink 的集成允许您指定各种 Hadoop 配置项,这之中就包括了数据的存储位置。
关键在于设置 Hadoop 配置参数 fs.defaultFS 指向本地文件系统(通常是 file:///)。这样配置后,Flink 作业在执行时会将数据写入到本地文件系统中
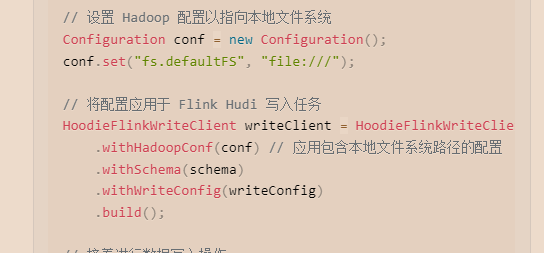
这样来
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。