DataWorks现在同一个源头得数据 写入到hdfs上面 一个3.5G得表 只需要20分钟 同步到同一台机器上面去就要4个小时?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
并发读取:多个File支持并发读取。通过配置并发读取,可以显著提高数据同步的速度。
数据压缩:使用合适的数据压缩方式,如ORCFile支持的SNAPPY和ZLIB压缩。压缩数据可以减少网络传输的时间和存储空间。
当您遇到DataWorks在将3.5GB的表数据写入HDFS只需20分钟,但同步至同一台机器却需要4个小时的情况时,可以从以下几个方面进行优化和调整:
资源组配置
使用独享数据集成资源组:确保使用独享数据集成资源组来完成数据同步任务。独享资源组可以提供更稳定的网络连接和更高的同步速度。
网络连通性:检查并优化源端到目标端的网络连接。网络链路的复杂性可能会影响数据传输的效率,确保网络路径尽可能直接且带宽充足。
数据格式与类型转换
选择合适的文件格式:HDFS Writer支持TextFile、ORCFile和ParquetFile格式。根据实际需求选择最适合的文件格式,例如,如果需要高效的列式存储,可以选择ORC或Parquet格式。
数据类型兼容性:在进行类型转换时,必须指定数据类型。确保所使用的数据类型在Hive中是受支持的,并且与源数据兼容。
性能优化
并发读取:多个File支持并发读取。通过配置并发读取,可以显著提高数据同步的速度。
数据压缩:使用合适的数据压缩方式,如ORCFile支持的SNAPPY和ZLIB压缩。压缩数据可以减少网络传输的时间和存储空间。
权限管理
确保足够的权限:数据同步进程以admin账号启动,需要确保该账号具备访问相应HDFS文件的读写权限。
同步策略
选择合适的同步策略:根据数据的特点和业务需求,选择合适的同步策略,如全量同步、增量同步或实时同步。
任务配置与监控
合理配置任务参数:在脚本模式下配置同步任务时,按照统一格式要求编写脚本中的reader参数和writer参数。
监控同步任务:在同步过程中监控任务的运行状态,及时发现并解决可能出现的问题。
此外,在进行数据同步时,还可以关注以下几个方面:
分区策略:对于Hive分区表,目前仅支持一次写入单个分区。如果需要同步的数据涉及多个分区,需要合理安排同步顺序。
数据一致性:确保源数据与目标数据的一致性,特别是在处理增量同步时,需要正确配置where子句来过滤待同步的数据。
错误处理:在网络中断等异常情况下,需要有相应的错误处理机制,如手动删除已经写入的文件和临时目录。
综上所述,您可以根据实际情况调整同步策略,优化网络配置,选择合适的文件格式和数据类型,以及合理配置同步任务参数,以提高数据同步的效率。同时,确保在同步过程中有足够的权限,并对任务进行监控,以确保数据同步的顺利进行。
针对您在DataWorks中遇到的问题,即一个3.5GB的表从源头写入到HDFS耗时20分钟,想要优化这一过程,可以参考以下策略:
优化同步任务配置:
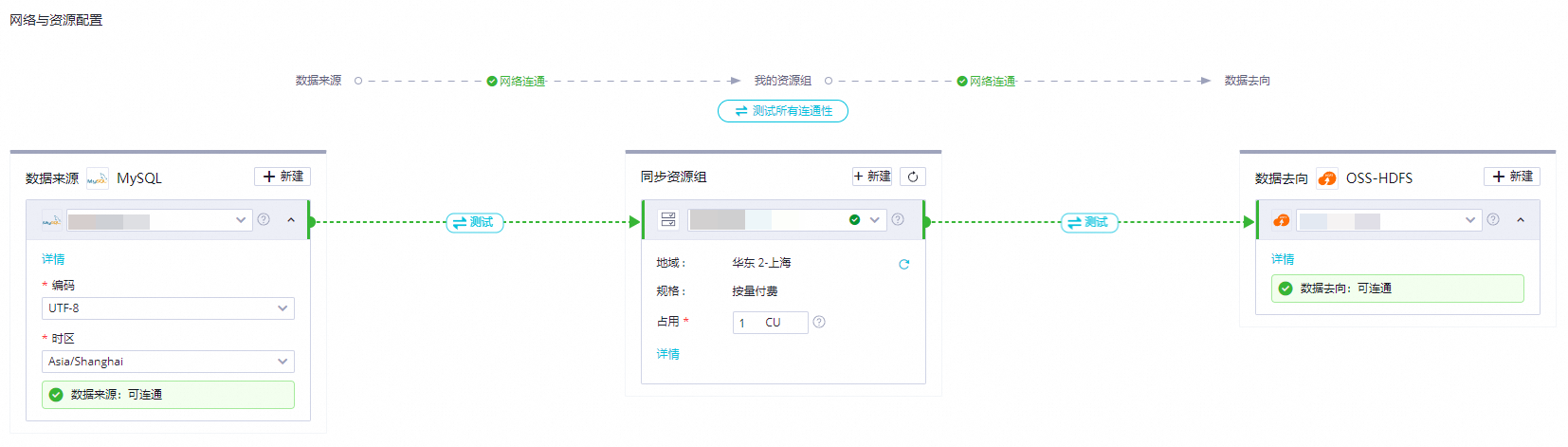
数据分区策略:
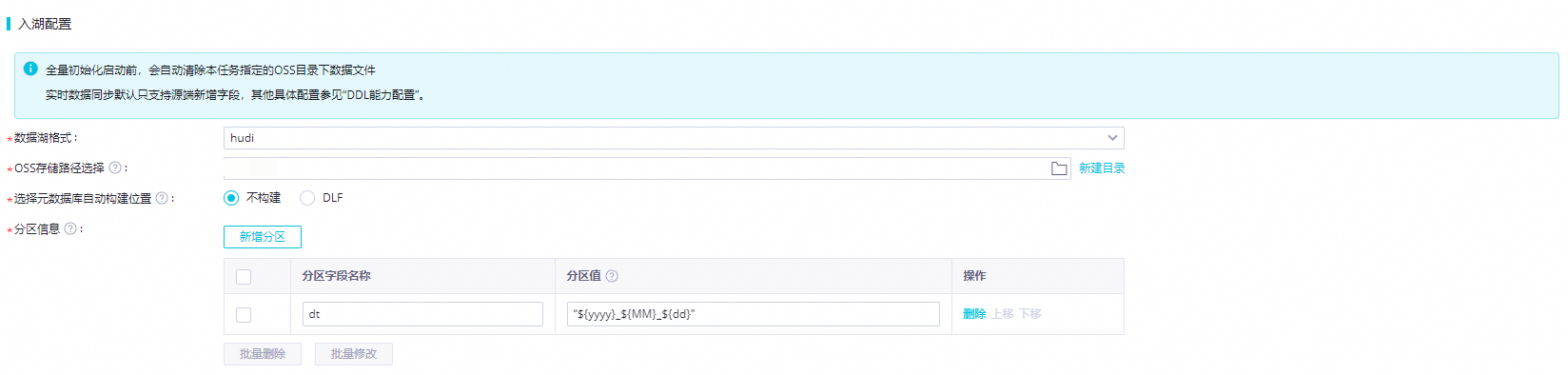
文件格式与压缩:
网络与I/O优化:
通过上述方法,您可以尝试优化数据写入HDFS的效率,缩短写入时间。不过,请注意平衡性能提升与成本消耗,避免不必要的高资源消耗。
相关链接
https://help.aliyun.com/zh/dataworks/user-guide/mysql-real-time-lake-iceberg-oss-hdfs
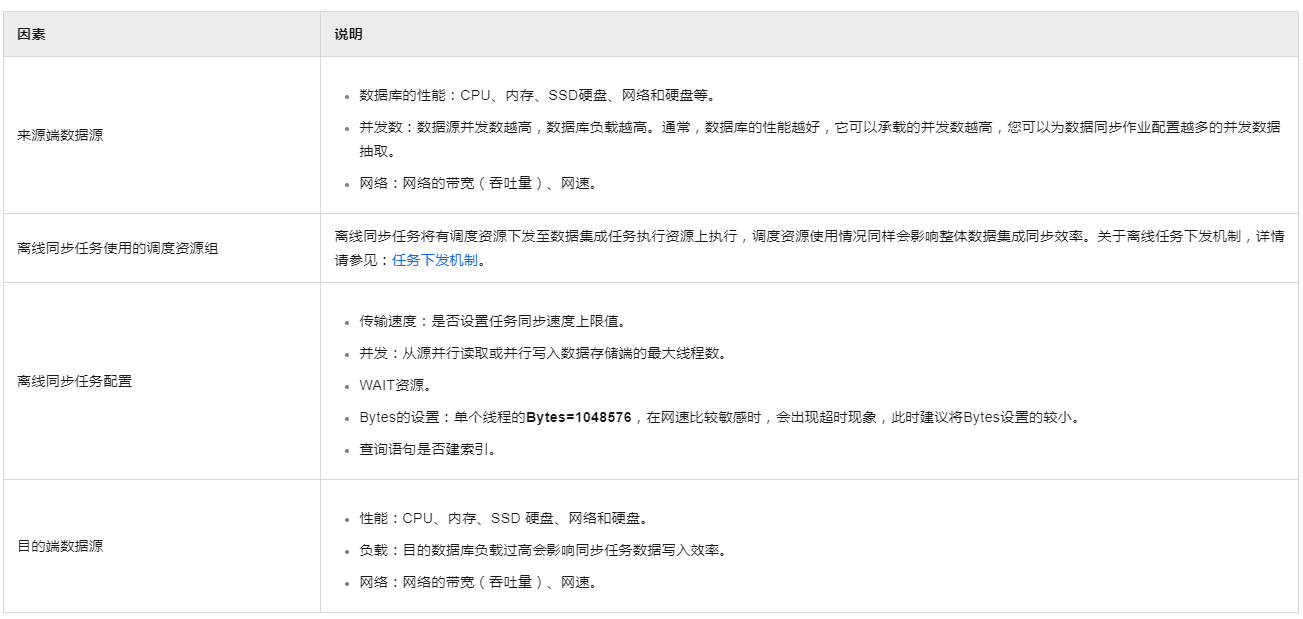
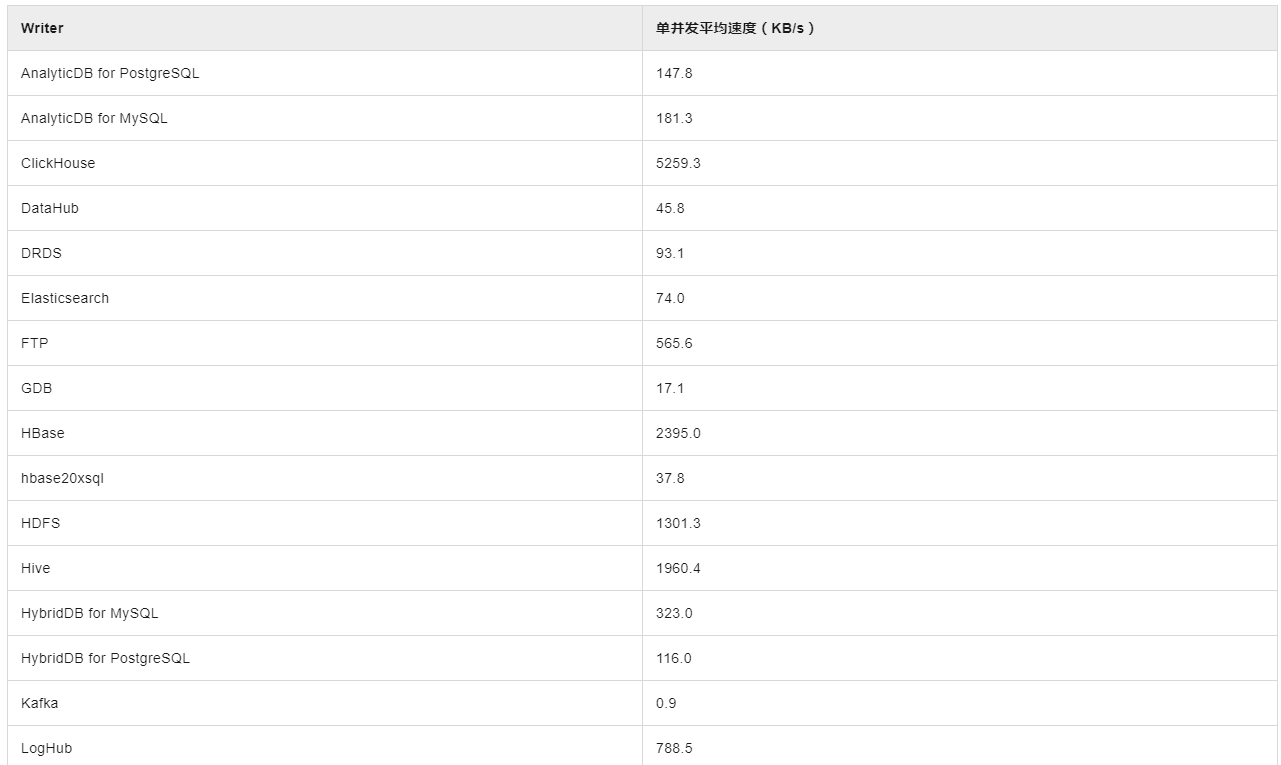
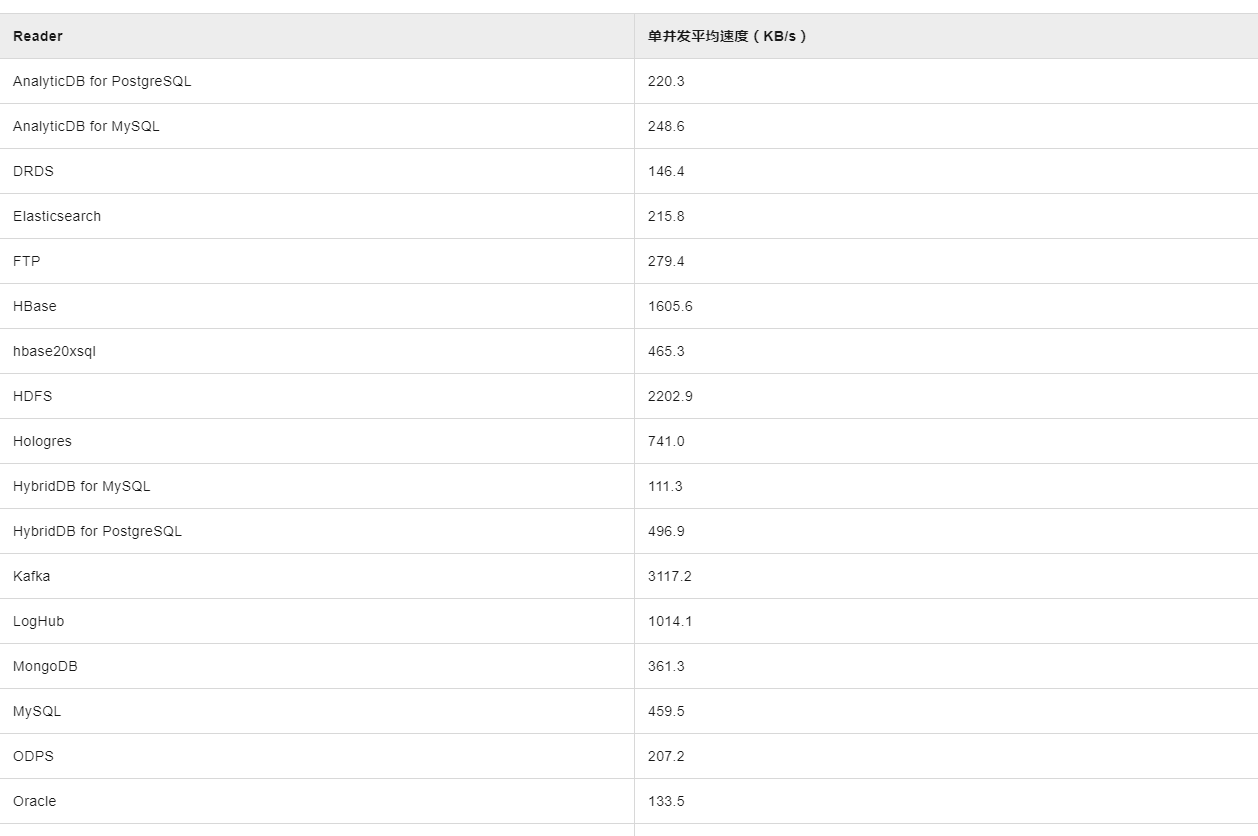
在处理DataWorks中的数据同步问题时,提高数据同步速度是一个常见的需求。为了解决您提到的将3.5GB的表数据在20分钟内同步到HDFS的情况,先需要分析可能影响同步速度的各种因素,然后提出具体的优化措施。以下是影响数据同步速度的因素以及相应的解决方案:
源端数据库性能
提升数据库性能:确保源数据库服务器拥有足够的CPU、内存和SSD硬盘资源,以支持高并发的数据读取操作。
网络带宽和延迟:检查并优化源数据库服务器与DataWorks平台之间的网络连接,确保网络带宽足够大且延迟最低。
目的端HDFS性能
增强HDFS性能:提高HDFS的写入性能,包括对namenode和datanode进行优化,确保它们具备足够的处理能力和存储带宽。
降低目的端负载:在数据同步期间,尽量减少HDFS上的其他负载,避免因资源竞争而影响写入效率。
任务配置优化
调整并发设置:根据源数据库和HDFS的负载能力,适当增加并发数,以提高数据传输的并行度。
减少单个线程数据量:如果网络敏感,适当减小Bytes的设置,以避免超时现象,从而提升响应时间和减少等待时间。
网络环境优化
使用独享资源组:利用独享数据集成资源组来执行数据同步任务,确保有专用的网络通道和计算资源,减少等待资源的时间。
保证网络访问能力:确保独享数据集成资源组具备访问HDFS的namenode和datanode的网络能力,避免因网络白名单限制等安全设置而影响数据同步速度。
Hive数据类型优化
数据类型兼容:确保源数据类型与Hive(HDFS上常用的数据管理系统)数据类型兼容,避免在数据同步过程中进行复杂的类型转换,从而减少额外的处理时间。
任务调度策略
选择合适的调度资源组:选择性能更优的调度资源组执行数据同步任务,以确保任务能够获得稳定的运行资源。
减少等待资源时间:通过运行诊断页面查看当前任务等待资源的情况,并根据情况调整任务优先级或资源分配,减少等待资源的时间。
HDFS 配置优化
平衡数据分布:通过HDFS的平衡器工具(Balancer)来均衡数据在不同节点之间的分布,从而提高整体写入效率。
磁盘容量扩展:适时对HDFS的磁盘容量进行扩展,以便能够处理更大规模的数据同步任务。
数据同步限速
合理设置限速:根据源数据库的实际负载能力,合理设置数据同步作业的速度上限,以避免对源数据库造成过大的压力。
阶段性同步策略:如果数据同步任务可以分阶段进行,考虑采用分批次同步的策略,逐步提交各部分任务,以减轻单次同步的压力。
此外,为了进一步提升数据同步的效率和稳定性,您还可以参考以下建议:
保持数据同步任务版本最新:确保您使用的DataWorks及HDFS版本是最新的,以便获得最新的性能改进和功能支持。
定期维护数据环境:对源数据库和HDFS进行定期维护,包括更新、清理和维护硬件设备,以保持最佳运行状态。
监控数据同步进度:利用DataWorks提供的监控工具实时跟踪数据同步的进度和性能指标,及时发现并解决潜在的瓶颈问题。
优化数据格式:选择适合HDFS的数据存储格式(如Parquet、ORC),这些格式通常能提供更高效的数据压缩和查询性能。
培训团队成员:确保涉及数据同步工作的团队成员具备足够的技术知识,了解如何优化数据同步任务和解决常见问题。
综上所述,通过上述多个方面的综合优化,您可以显著提升DataWorks将数据同步到HDFS的速度,从而有效缩短同步时间,满足您的业务需求。每个环节的优化不仅关注当前的效率提升,还应考虑到长远的稳定性和可维护性,以保证数据同步任务的持续高效运行。
DataWorks的实时同步任务中,3.5GB的数据从源头到HDFS只需要20分钟,但同机的写入却耗时4小时,可能存在以下问题:
写入瓶颈:检查写入端是否有性能瓶颈,如HDFS的写入压力过大,或者磁盘I/O限制。
并发与资源:确认同步任务的并发设置和资源分配,可能需要增加并发或调整任务内存。
数据倾斜:检查是否数据分布不均,导致某些分区写入慢。
系统异常:查看日志中是否存在异常信息,特别是Error/Exception,这可能影响了写入速度。
请参考实时同步任务延迟解决方案,检查任务运行详情,包括窗口等待时间、日志和Failover事件,根据情况调整配置或优化任务。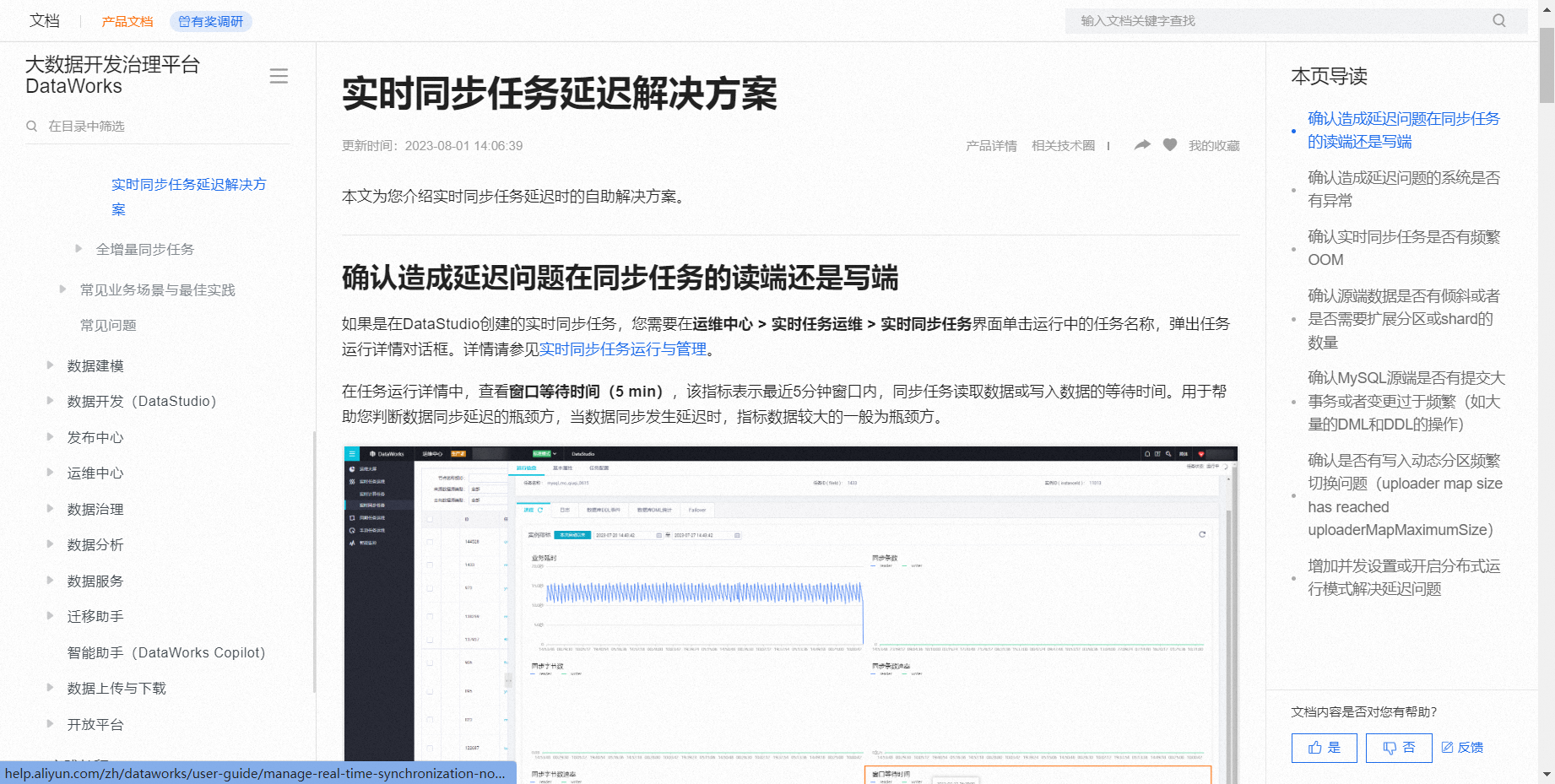
在DataWorks中配置同步任务时,不同的配置选项会对同步效率产生显著影响。例如,实时同步任务Checkpoint时间间隔、任务并发度、 Bucket Assign并行度 以及 单表写入并发度 等高级参数配置
。如果这些参数在HDFS同步任务中设置得当,能够充分利用资源,提高同步效率;而到本地机器的同步任务可能未进行优化配置,导致处理速度慢。
如果您在使用DataWorks处理数据并写入HDFS时发现某个3.5GB的数据表只需要20分钟就能完成,这通常意味着您的数据处理和写入流程效率非常高。然而,如果您对这个性能感到意外或者有其他问题(比如资源使用过高、成本考虑等),我们可以探讨一下可能的原因以及如何调整。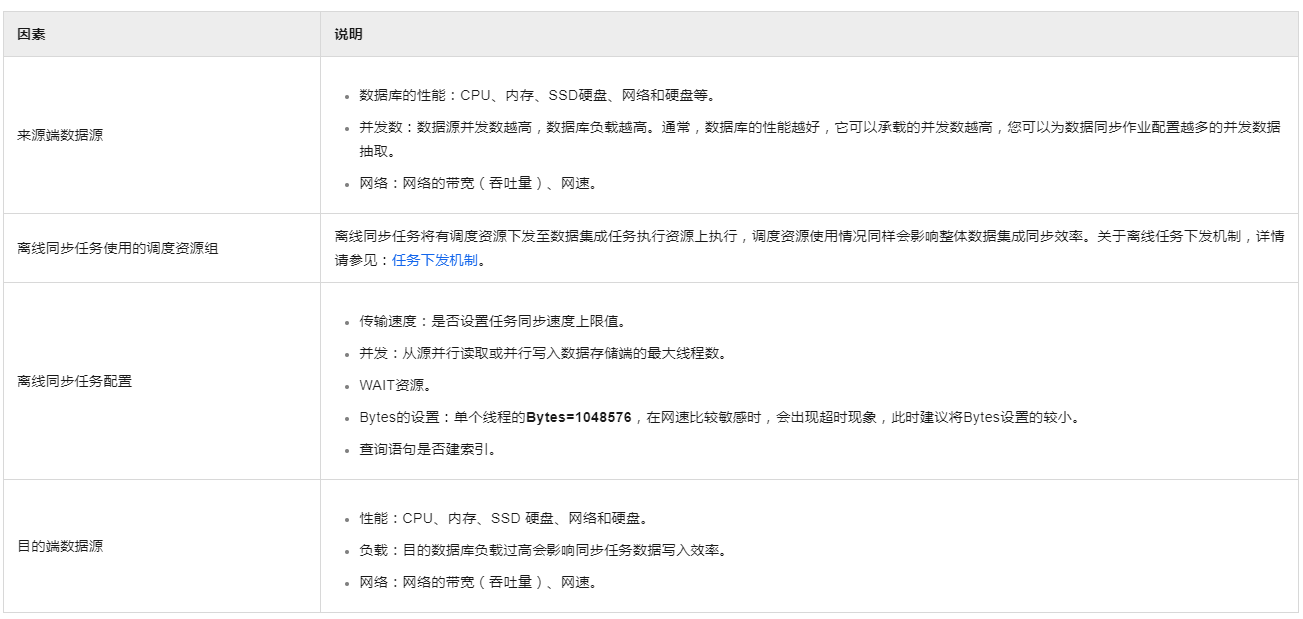
如果您希望减慢处理速度以节省资源或出于其他原因,可以考虑以下几点:
确保监控您的作业和集群资源使用情况,以确定是否有资源浪费或瓶颈存在。您可以使用Hadoop自带的监控工具(如YARN ResourceManager UI)或第三方工具来监控集群状态。
。
系统调优
限速配置:考虑到过高的同步速度可能会对数据库造成过大的压力,影响生产环境的稳定性,可以通过调整DataWorks的限速选项来控制数据的写入速率。这能确保在不超负荷的情况下稳定运行。
资源分配:检查并优化Hadoop集群的资源分配,如内存和CPU的配置,以提升数据处理的速度及并行度。
需要检查你两个同步任务的具体配置,包括但不限于同步类型、资源组配置、并发度设置等。确保针对HDFS的目标同步任务配置了合适的资源和优化参数,比如是否启用了足够的并发度、是否正确设置了Checkpoint时间间隔等
。资源组配置对任务执行效率有直接影响,独享数据集成资源组对HDFS写入有特定要求
网络和硬件、带宽性能不一样。
数据集成包括离线同步、实时同步和全增量同步任务三个功能模块,您可以根据各模块对数据源的支持情况,选择对应的功能模块进行同步任务的配置。
DataWorks离线同步为您提供数据读取(Reader)和写入插件(Writer)实现对数据源的读写操作。
DataWorks实时同步支持您将多种输入及输出数据源搭配组成同步链路进行单表或整库数据的实时增量同步。
DataWorks还为您提供多种数据源之间进行不同数据同步场景(整库离线同步、全增量实时同步)的同步。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/supported-data-source-types-and-read-and-write-operations?spm=a2c4g.11186623.0.i232
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。