
flink sql打的jar在服务器运行的问题,如何解决?各个依赖包都OK在的,但是运行时候就是报这个问题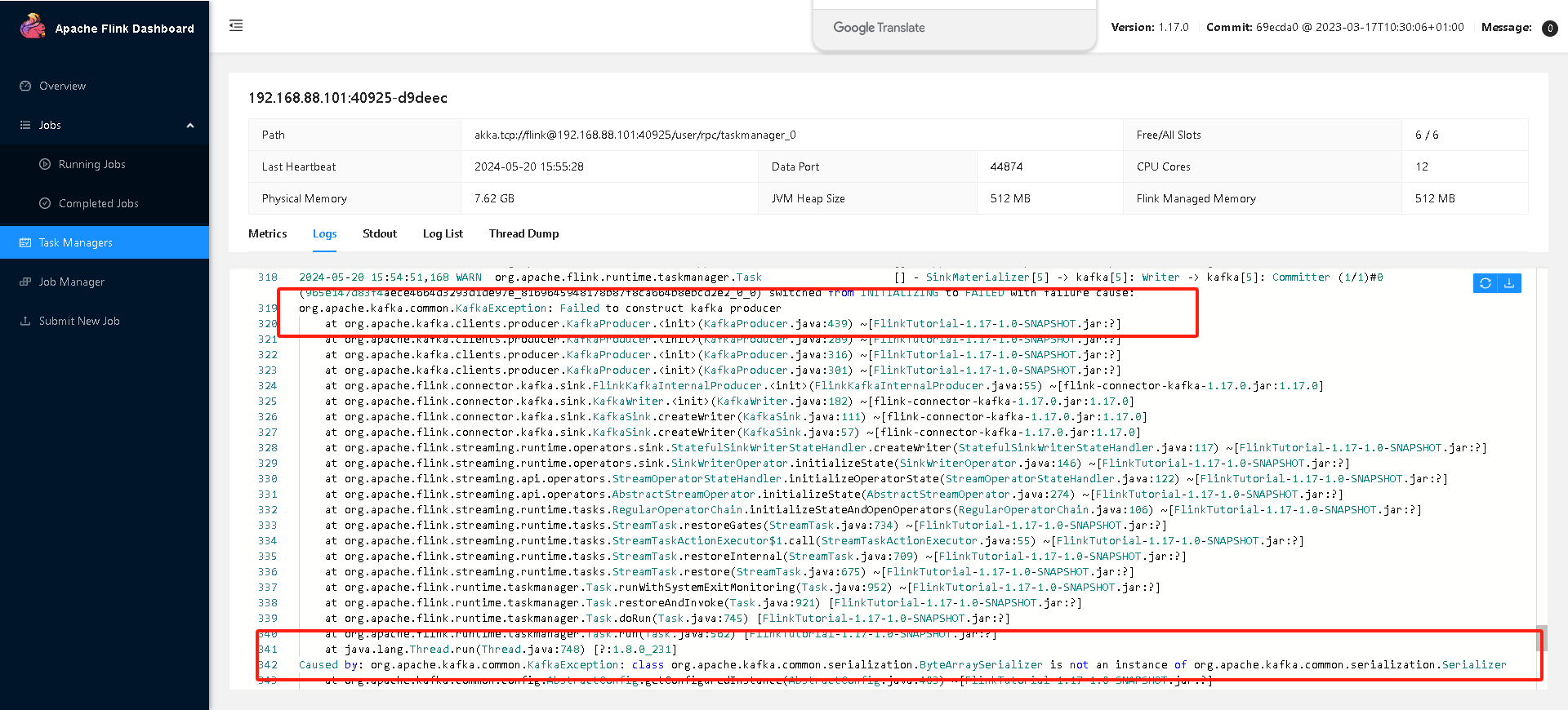
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到这个异常信息“Caused by: org.apache.kafka.common.KafkaException: class org.apache.kafka.common.serialization.ByteArraySerializer is not an instance of org.apache.kafka.common.serialization.Serializer”,通常意味着Flink作业在尝试使用Kafka时,遇到了序列化类加载的问题。这可能是由于类加载冲突或不正确的类版本导致的。以下是一些可能的解决方法:
检查依赖版本:确保你的项目中使用的Kafka客户端版本与Flink所依赖的Kafka版本兼容。不一致的版本可能导致类加载问题。检查pom.xml或build.gradle文件中的Kafka依赖,并确保它们是最新的且相互兼容。
排除冲突依赖:如果你的项目中同时依赖了多个可能包含Kafka客户端的库(比如直接依赖了Kafka客户端,而Flink的某些依赖也间接包含了Kafka客户端),可能会导致类加载冲突。可以尝试在Flink或相关库的依赖声明中使用<exclusions>标签来排除冲突的Kafka依赖。
例如,在Maven中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
然后单独指定一个兼容的Kafka客户端版本。
类加载策略:在Flink的配置中调整类加载策略。Flink允许通过配置自定义类加载行为,以解决潜在的类冲突问题。可以在flink-conf.yaml中设置如下配置:
classloader.resolve-order: parent-first # 或者尝试使用 child-first
parent-first表示先从父类加载器加载类,而child-first(也称为“沙箱模式”)则优先从应用程序类加载器加载类,这有助于避免与系统类加载器中的类冲突。
检查序列化类的使用:确认你在Flink SQL或代码中使用Kafka Serializer的方式是否正确。确保你没有误用了类名或错误地实例化了序列化器。
如果以上方法都不能解决问题,建议查看详细的堆栈跟踪信息,以确定问题的具体来源。此外,也可以考虑在Flink或Kafka的社区论坛提问,提供更详细的问题描述和环境信息,以便获得更专业的帮助。
问题似乎与Apache Flink应用程序中的Kafka连接器有关。错误消息表明无法构造Kafka producer,并且引发了org.apache.kafka.common.KafkaException。这可能是因为Flink程序中使用的Kafka序列化器不是有效的Serializer类。尝试以下解决: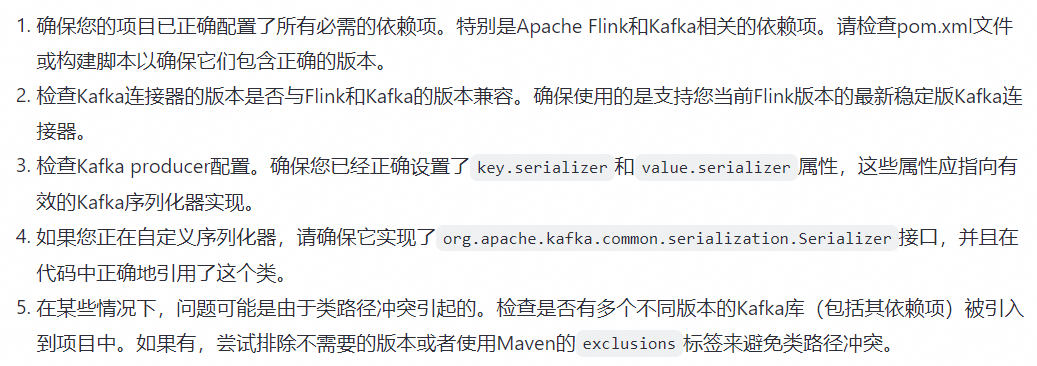
Flink与Kafka集成时遇到的数据序列化错误问题,通常是由于序列化器(Serializer)配置不当或数据类型不匹配导致的。以下是一些可能的原因及解决方案:
一、常见原因
序列化器不匹配:
Kafka和Flink使用的序列化器不一致,导致数据在传输过程中无法正确解析。
数据类型问题:
Flink处理的数据类型不符合Kafka序列化器的要求,例如,Kafka期望的是String类型,但Flink发送的是自定义对象。
配置错误:
Flink或Kafka的配置文件中,关于序列化器的配置项设置错误或遗漏。
依赖问题:
如果使用了第三方的序列化库(如Avro、Protobuf等),可能存在依赖项未正确添加或版本冲突的问题。
版本兼容性:
Flink和Kafka的版本之间可能存在序列化兼容性问题。
二、解决方案
检查并配置正确的序列化器:
确保Kafka和Flink都使用了正确的序列化器。在Flink中,可以通过设置FlinkKafkaProducer的serializationSchema属性来指定序列化器。
如果使用自定义数据类型,确保该类型已经实现了相应的序列化接口,或者在Flink中配置了自定义的序列化器。
检查数据类型:
验证Flink处理的数据类型是否符合Kafka序列化器的要求。如果不符合,需要进行类型转换或使用合适的序列化器。
检查配置文件:
仔细检查Flink和Kafka的配置文件,确保所有关于序列化器的配置项都已正确设置。
解决依赖问题:
如果使用了第三方的序列化库,请确保相关依赖项已正确添加到项目中,并且没有版本冲突。
考虑版本兼容性:
如果遇到版本兼容性问题,可以尝试升级或降级Kafka或Flink的版本,或者查找是否有相关的补丁或解决方案。
Caused by: org.apache.kafka.common.KafkaException: class org.apache.kafka.common.serialization.ByteArraySerializer is not an instance of org.apache.kafka.common.serialization.Serializer
这表明在构建Kafka生产者时,遇到了序列化器(Serializer)的问题。具体来说,ByteArraySerializer类没有被正确地识别为Serializer类型的实例
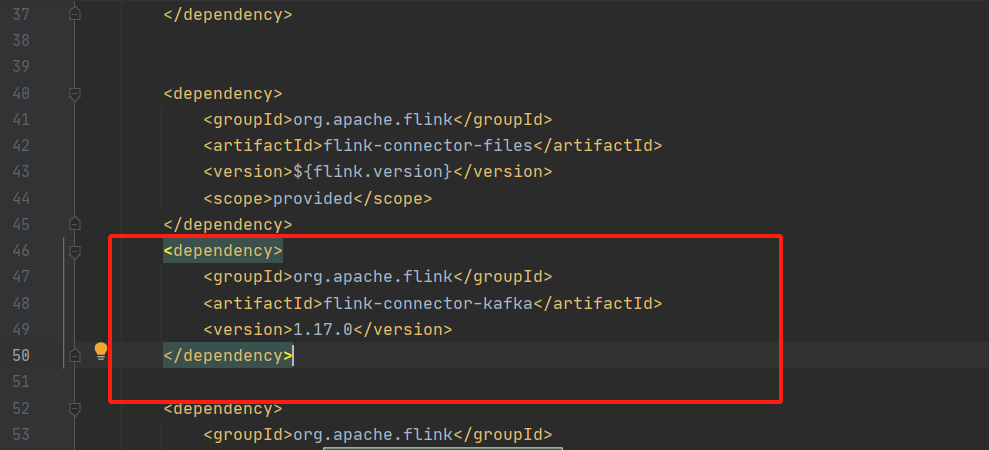
看看你的依赖有没有问题 特别是flink-connector-kafka和kafka-clients的版本。在您的依赖配置中,flink-connector-kafka的版本是1.17.0,这应该与Flink版本相匹配
正常的序列器:
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.sink.KafkaSinkBuilder;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaSinkConnector;
import java.util.Properties;
public class KafkaSinkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
KafkaSinkBuilder<String> sinkBuilder = KafkaSink.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopic("test")
.setSerializer(new ByteArraySerializer()); // 确保这里使用的是正确的序列化器
DataStream<String> stream = env.fromElements("message1", "message2", "message3");
stream.sinkTo(sinkBuilder.build());
env.execute("Kafka Sink Example");
}
}
Flink kafka 数据序列化错误问题
解决方案如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <artifactId>kafka-clients</artifactId>-->
<!-- <groupId>org.apache.kafka</groupId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
</dependency>
——参考链接。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


