
 4000积分,折叠桌*6
4000积分,折叠桌*6
在数据库管理系统的世界中,每一条SQL语句的背后都隐藏着一个复杂而精细的执行过程,我们不可避免地会好奇,从键盘敲下的一条简单或复杂的SQL查询语句,到屏幕上展现的数据结果,这一过程中究竟发生了哪些错综复杂的操作?每一步都是如何协同工作以确保信息的准确无误?一条SQL语句的执行究竟经历了哪些过程?谈谈你的看法~
本期奖品:截止2024年6月18日24时,参与本期话题讨论,将会选出 3 个优质回答和 3 个幸运用户获得折叠桌。快来参加讨论吧~
幸运用户获奖规则:本次中奖楼层百分比为30%、60%、80%的有效留言用户可获得互动幸运奖。如:活动截止后,按照回答页面的时间排序,回复为100层,则获奖楼层为 100✖35%=35,依此类推,即第35位回答用户获奖。如遇非整数,则向后取整。 如:回复楼层为81层,则81✖35%=28.35,则第29楼获奖。
优质讨论获奖规则:不视字数多,结合自己的真实经历分享,非 AI 生成。
未获得实物礼品的参与者将有机会获得 10-100 积分的奖励。
注:楼层需为有效回答(符合互动主题),灌水/复制回答将自动顺延至下一层。如有复制抄袭、不当言论等回答将不予发奖。阿里云开发者社区有权对回答进行删除。获奖名单将于活动结束后5个工作日内公布,奖品将于7个工作日内进行发放,节假日顺延。
中奖用户:
截止到6月18日共收到120条有效回复,获奖用户如下
优质回答:GeminiMp、长银、你都不懂
幸运用户:huc_逆天、Kakarot96、py3284
恭喜以上用户!感谢大家对本话题的支持~
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
我对于sql语句的执行,认为有这些内容 包括解析与编译、查询优化和执行三个主要步骤。首先,SQL引擎解析语句并检查语法和权限,然后通过优化器选择最佳执行计划,最后执行该计划以访问和处理数据,并返回结果给客户端。整个过程确保查询高效、准确地完成,同时维护数据一致性和安全性。
这样一条sql就可以完整的执行拉..
以前就了解过这类内容。SQL的执行是比较简单的,其实。
首先是解析;当SQL语句提交给数据库时,数据库管理系统(DBMS)首先对其进行解析。解析过程包括检查SQL语句的语法是否正确,将SQL语句分解成数据库能够理解的更小的单元,如关键字、表名、字段名等
然后再编译BMS将SQL语句编译成可执行的代码。这个过程涉及到将SQL语句转换成内部表示形式,如查询树(query tree)或查询计划(query plan)。
最后就生成了:编译完成后,查询优化器(query optimizer)会分析生成的查询计划,并尝试找到执行该查询的最有效方式。这可能包括选择不同的索引、决定表连接的顺序、使用不同的查询算法等。
最近是数据库引擎开始执行SQL语句。这可能包括从磁盘读取数据、在内存中进行排序、执行连接操作等。然后就是返回结果
第⼀步:连接器
之后第二大步骤:查询缓存:解析出 SQL 语句的第⼀个字段,看看是什么类型的语句。如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )⾥查找缓存数据。 如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执⾏,等执⾏完后,查询的结果就会被存⼊查询缓存中。再然后就是解析SQL,执行SQL。这就是一个完整的过程了。
一条sql想要完整的执行起来,需要以下步骤: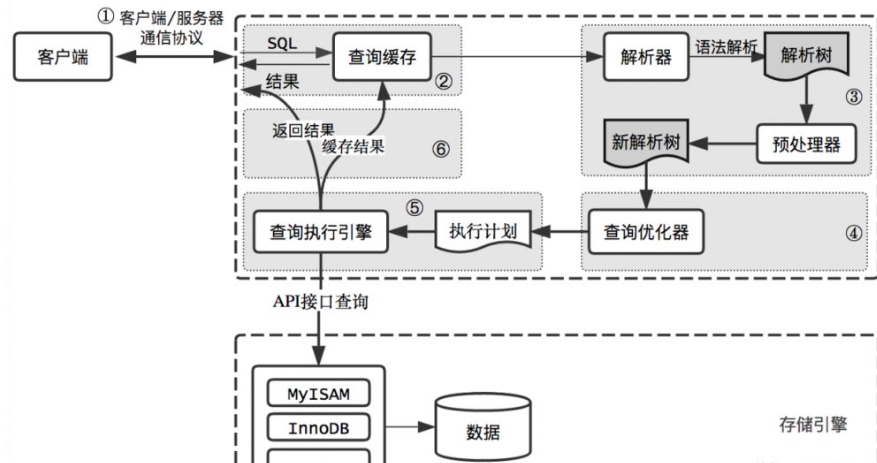
首先进行语法解析以确保语句的正确性,接着编译成可执行的内部表示,然后通过优化器选择最佳查询路径,生成具体的执行计划,随后数据库引擎根据执行计划检索并处理数据,最终将结果集返回给用户。这个过程是较为复杂的,设计数据库的人真是牛掰
比如mysql数据库,它会先进行词法分析:MySQL首先对SQL语句进行词法分析,将SQL语句分解成一个个token(关键字、标识符、运算符等),同时对token进行分类和解析,生成相应的数据结构。
然后MySQL对SQL语句进行语义分析,对语法树进行遍历,确定语句中表和列的信息,包括表名、列名、列类型等,同时检查语句的语义正确性。之后就是优化器处理:MySQL通过优化器对SQL语句进行处理和优化,包括执行计划的生成、索引的选择、连接方式的选择等。
最后才是 执行计划生成:MySQL通过执行计划生成器生成SQL语句的执行计划,即具体的执行方式,包括数据的访问方式、索引的使用方式、连接方式、排序方式等内容嘞
SQL语句的执行过程可以简化为以下几个关键步骤:
解析:检查语句的语法是否正确。
编译:将语句转换成内部形式。
优化:选择最有效的查询路径。
执行:按照计划检索数据。
返回结果:将查询结果展示给用户。
这个过程确保了数据的准确性和查询的效率。
主要是上面这些步骤进行处理我们写的SQL语句
sql语句执行的过程中经历了解析,编译,优化,执行,数据检索,数据缓存,结果生成,等内容,每一个步骤都是至关重要的。
第一步,在我们写好SQL语句时,数据库管理系统(DBMS)接收到SQL语句后,会对其进行解析。解析器会检查SQL语句的语法是否正确,包括关键字的使用、语句结构等,经过解析后,如果SQL语句没有语法错误,编译器会将其转换成执行计划。这个过程涉及到将SQL语句转换成一种内部表达形式,便于数据库引擎进一步处理。
然后在经过优化器进行优化,然后才开始执行的,再返回出结果;
另外如果SQL语句是在一个事务中执行的,数据库系统还需要处理事务的提交或回滚,确保数据的一致性和完整性。
对于SQL语句的执行过程,其主要步骤包括:
1.建立连接和权限认证
2.SQL语句的解析
3.执行计划的优化
4.执行查询和数据返回
此外,写操作如插入、更新和删除,还会涉及到更为复杂的事务处理机制,包括但不限于undo/redo日志的记录以及MVCC(多版本并发控制)的处理,以保证数据的一致性和操作的原子性。
一条SQL语句的执行究竟经历了哪些过程?
SQL执行涉及 Lexical Analysis, Syntax Analysis, Semantic Analysis, Query Optimization, Execution Plan Generation, Query Execution, Result Fetching, Transaction Management, 和 Resource Cleanup。系统解析SQL成标记,构建AST,验证语义,选择最优执行路径,生成执行计划,执行查询,返回结果,管理事务,并清理资源,确保效率、准确性和数据安全。
一条SQL语句的执行究竟经历了哪些过程?
一条SQL语句的执行究竟经历了哪些过程?
SQL执行流程概览:
语法解析检查语法规则,通过后进行查询优化选择最佳路径;
生成执行计划描述数据检索步骤;
执行数据操作、返回结果集,事务管理确保数据一致性,日志记录操作详情,更新统计信息优化未来查询。
一条SQL语句的执行究竟经历了哪些过程?
SQL执行过程概览:
一条SQL语句的执行究竟经历了哪些过程?
SQL执行涉及Parse(语法分析)、Optimization(选择执行计划)、Execution(执行操作)、Locking & Transaction Management(并发控制)及Result Retrieval(返回结果)和Error Handling(错误处理)。数据库确保语法正确后,优化器制定最佳执行策略,执行时处理数据并发与一致性,并在完成后返回结果或在出错时报告。
在数据库管理系统(DBMS)中,执行一条SQL语句的过程涉及多个步骤,这些步骤共同确保了查询的准确性和效率。以下是SQL语句执行的一般过程:
词法和语法分析:
当用户输入SQL语句后,DBMS首先进行词法分析,将输入的字符串分解成有意义的词素(tokens)。
接着进行语法分析,根据SQL语法规则将这些词素组合成一棵语法树(parse tree),表示查询的逻辑结构。
语义检查:
在生成语法树之后,DBMS会进行语义检查,确保查询语句在逻辑上是正确的。
这包括检查表名、列名是否存在,以及是否有访问权限等。
查询优化:
语法树形成后,DBMS的查询优化器会对查询计划进行评估和优化,以找到最有效的执行路径。
优化器会考虑索引的使用、数据的分布、连接顺序等因素,以减少数据检索和处理的时间。
生成执行计划:
优化器最终会生成一个详细的执行计划,这个计划描述了如何执行查询的具体步骤。
执行计划包括了对数据的读取、连接、排序、分组、过滤等操作。
执行计划:
生成执行计划后,DBMS的执行引擎开始按照计划执行查询。
这可能涉及到从磁盘读取数据到内存、对数据进行各种操作(如连接、聚合等),以及可能的I/O操作。
处理并发和事务:
在执行查询的过程中,DBMS还需要处理并发事务,确保数据的一致性和隔离性。
这可能涉及到锁定机制,以防止其他事务修改正在被查询的数据。
返回结果集:
一旦查询执行完毕,DBMS会将结果集返回给客户端。
结果集通常是一组行,每行包含查询结果的一组列。
清理和释放资源:
查询完成后,DBMS需要清理临时数据、释放锁定的资源,以及进行必要的内存管理。
这个过程是高度优化的,并且可以根据不同的DBMS和数据模型有所变化。例如,关系型数据库系统(RDBMS)和非关系型数据库系统(NoSQL)在执行SQL查询时可能会有不同的优化策略和资源管理方式。此外,现代DBMS还具备许多高级功能,如分布式查询、并行处理、自动索引管理等,这些都可能在查询执行过程中发挥作用。
在python中运行一个sql语句时,数据库会先做几件事情来确保它能正确理解并执行的指令:
解析:数据库会读一遍写的sql语句,就像拼图一样把关键字、表名、字段名等拼凑在一起,形成一个它能理解的结构。如果这一步发现有些地方不对劲,比如忘了写个括号或者逗号,它就会告诉哪里出了问题。
预处理:接下来,数据库会检查一下有没有权限做这个操作,以及要查询的表和字段是否存在。如果试图做一些不被允许的事情,或者引用了一些不存在的东西,这一步就会提醒。
优化:然后,数据库会想一下怎么最高效地完成的请求。这个过程可能会涉及到选择用哪个索引,或者决定以什么样的顺序连接表格。这一步是非常关键的,因为一个好的计划可以让查询跑得飞快。
执行:到了这一步,数据库就开始真正动手干活了。它会按照之前想好的计划,一步步执行的sql语句。
提取数据:如果的sql语句是查询数据的话,数据库会在执行完毕后从结果集中拿出需要的数据。
返回结果:最后,数据库会把提取出来的数据发回给的python程序,就可以把这些数据显示出来,或者用来做其他的事情了。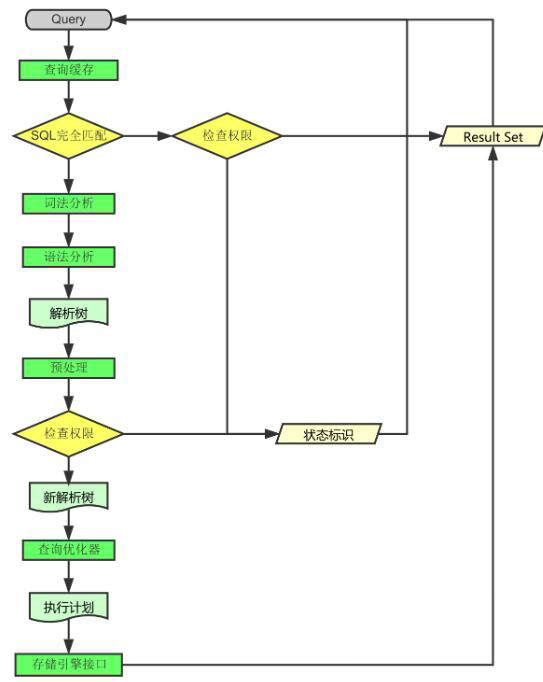
所以,虽然我们通常只需要写一条简单的sql语句,但数据库在背后其实做了很多工作来确保一切顺利进行。我们作为程序员,了解这些步骤可以帮助我们写出更高效的代码,避免一些常见的错误。
SQL语句的执行过程,涉及到数据库的很多内部机制。在键盘上敲下一条SQL查询语句,到屏幕上出现结果,这背后都发生了什么。
敲下一条SQL语句,数据库管理系统(DBMS)得先检查这语句对不对,这就像是检查作文的语法一样。如果语句有错,比如拼写错误或者缺少关键字,DBMS会抛出一个错误,告诉你哪儿写错了。
如果语法没问题,接下来DBMS会做语义分析,确保你的SQL语句在逻辑上是有意义的。比如,你查询的表或字段得是存在的,不能张冠李戴。
这一步,DBMS会决定怎么执行SQL语句最高效。它会生成一个执行计划,这就像是出行的路线图,告诉你怎么走最快。这个计划会考虑很多东西,比如数据的存储方式、索引的使用、表的连接顺序等。
生成的执行计划可能不是最优的,DBMS里头有个查询优化器,它的工作就是找到更快的执行方案。这个过程就像是在规划路线时,会考虑走高速还是普通道路。
执行计划确定后,DBMS就开始真正干活了。它会按照计划去访问数据,进行必要的计算和排序。这个过程可能会涉及到磁盘I/O操作,因为数据可能存储在磁盘上。
如果同时有多个人在操作数据库,DBMS还得处理并发问题,确保数据的一致性和完整性。这就像是交通指挥,得保证车辆有序通行,不发生事故。
最后,DBMS会把查询结果返回给你,这就像是在网上买东西,最后快递把包裹送到你手上。
很多DBMS还有缓存机制,如果之前查过的数据,可能就直接从缓存里拿,这样速度就快多了。
我觉得,虽然对用户来说,可能就是敲了一条SQL语句,但背后DBMS其实做了很多工作,这些工作都是为了保证数据的准确和查询的效率。作为开发者,了解这些原理挺重要的,有时候调优SQL或者设计数据库,这些知识都能派上用场。
SQL语句的执行过程就像是一趟数据之旅,从你的键盘出发,经过DBMS内部的一系列处理,最后把结果呈现在你的屏幕上。这一路上,DBMS得确保旅途顺利,数据安全到达。
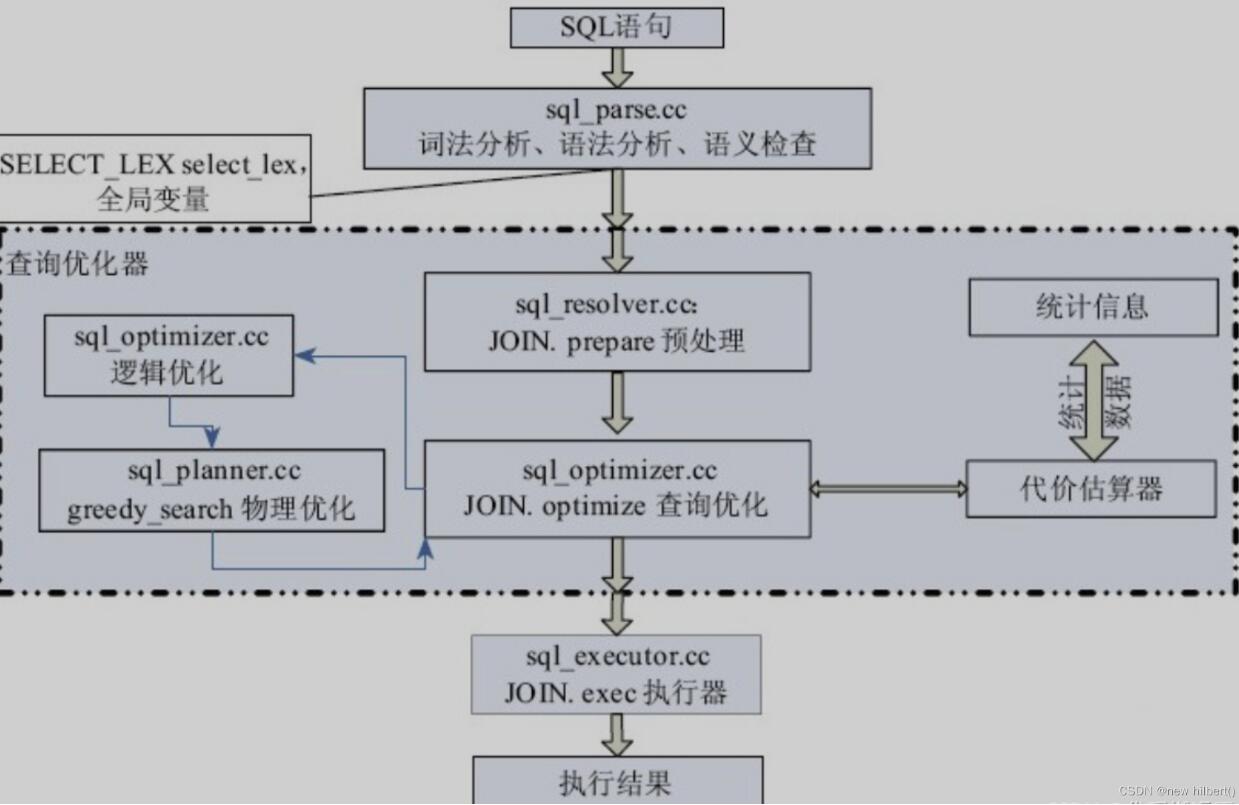
每一条SQL语句的执行背后确实隐藏着一个非常复杂的执行过程。这个过程涉及到数据库管理系统(DBMS)的多个组件协同工作,以确保查询的准确和高效执行。大致来说,一条SQL语句的执行过程可以分解为以下几个关键步骤:
在这一阶段,DBMS的解析器将检查SQL语句的语法是否正确。这包括验证语句中的关键字、数据类型、表达式语法等是否符合SQL语言规范。如果语法有误,解析器将返回错误。
解析过程还包括将SQL语句转换成数据库理解的内部格式,通常是一个解析树(parse tree)结构,此结构细致描述了SQL语句的组成部分及其关系。
这是SQL执行过程中至关重要的一步。在此阶段,查询优化器将评估可能的数据检索方案,选择最有效、最经济的查询计划。这涉及到考虑索引使用、表连接顺序和方法、数据分布统计信息等。
优化器在多个可能的执行计划中选择成本最低的那一个。成本评估基于多种因素,包括I/O操作次数、网络通讯量、内存使用量等。
根据优化器选定的执行计划,执行引擎将开始实际的数据操作。这可能包括读取数据、应用过滤和聚合函数、执行连接操作等。
执行过程可能涉及从磁盘到内存的数据移动,特别是当查询的数据量大于DBMS可用内存时。在这种情况下,DBMS会用到诸如外部排序或分区策略来处理数据。
完成所有数据处理操作后,最终的结果集将返回给客户端。这些结果通常以表格形式展示,但具体展示方式取决于使用的客户端。
整个过程中,多种缓存机制也被用来优化性能,包括SQL缓存、数据缓存、执行计划缓存等。如果一个查询先前已被执行且结果被缓存,DBMS可能直接返回缓存中的结果,避免重复执行相同的计算。
此外,现代数据库还可能进行更多的操作,包括并发控制和事务管理,以确保在多用户环境下数据的一致性和完整性。
从SQL语句的敲入到结果的返回,每一步都经过精心设计,以确保执行的准确性和效率。这个过程展现了数据库管理系统在软件工程、算法优化和系统架构方面的先进技术。
在数据库的世界里,SQL语句是用户与数据库交互的桥梁,也是核心。每当我们在数据库管理系统中键入一条SQL查询语句并按下回车键时,这条语句就会经历一系列复杂而精细的执行过程,便踏上了它在数据库内部的旅程,这个过程不仅复杂,而且精细,涉及多个阶段和组件的协同工作,确保数据的准确性和查询的高效性。那么本文就将详细介绍这些过程,以及每一步是如何协同工作以确保信息的准确无误,欢迎评论区留言交流。
接下来就来分享一下一条SQL语句的执行过程,从键入到查询,大概的流程步骤操作,如下所示。
当我们键入提交SQL语句后,数据库管理系统首先会接收这条语句,然后解析器会对SQL语句进行词法分析和语法分析,词法分析将SQL语句拆分成一个个的单词或符号,而语法分析则检查这些单词或符号是否按照SQL语言的语法规则进行排列。如果SQL语句存在语法错误,解析器会立即返回错误信息,阻止查询的进一步执行。
通过解析器的检查后,SQL语句会进入语义分析阶段,也就是语义检查阶段。在这一阶段,DBMS会检查SQL语句中的表、列和其他数据库对象是否存在,以及用户是否有足够的权限来执行这条语句。而且DBMS还会检查数据类型是否匹配,以及是否存在其他语义上的错误,如果语义检查失败,DBMS会返回相应的错误信息。
接下来是查询优化阶段,这是数据库管理系统的核心部分之一,查询优化是SQL语句执行过程中的关键步骤。在这个阶段,优化器会根据数据库的统计信息、表的存储结构、索引的使用情况等因素,对SQL语句进行多种可能的执行路径的分析和比较,然后选择出最优的执行计划。优化器的目标是找到最优的执行计划,以最小化查询的响应时间并最大化系统的吞吐量,这个优化过程可能涉及重写查询、选择索引、调整连接顺序等操作,旨在提高查询的执行效率。
在优化器确定了最优的执行计划后,也就是经过查询优化器的分析后,DBMS会生成一个执行计划树或执行计划图。这个执行计划详细描述了如何执行SQL语句,包括需要访问哪些表、使用哪些索引、如何进行数据的排序和聚合等。执行计划是DBMS执行SQL语句的依据,也是保证查询效率和准确性的关键。
根据生成的执行计划,DBMS开始执行SQL语句。这个过程可能涉及多个组件的协同工作,比如存储引擎、内存管理器等。在执行过程中,DBMS会读取数据、应用过滤器、进行连接操作、排序和聚合等,最终生成查询结果。而且DBMS还需要考虑并发控制和事务管理等因素,以确保多个用户可以同时访问数据库,而不会相互干扰或破坏数据的一致性。
当查询执行完成后,DBMS会将结果返回给用户。这个结果可能是表格形式的数据、聚合值、计算结果等。在返回结果之前,DBMS还会对结果进行校验和格式化,以确保结果的准确性和可读性,而且DBMS还会将结果缓存起来,以便后续相同的查询可以快速返回结果。
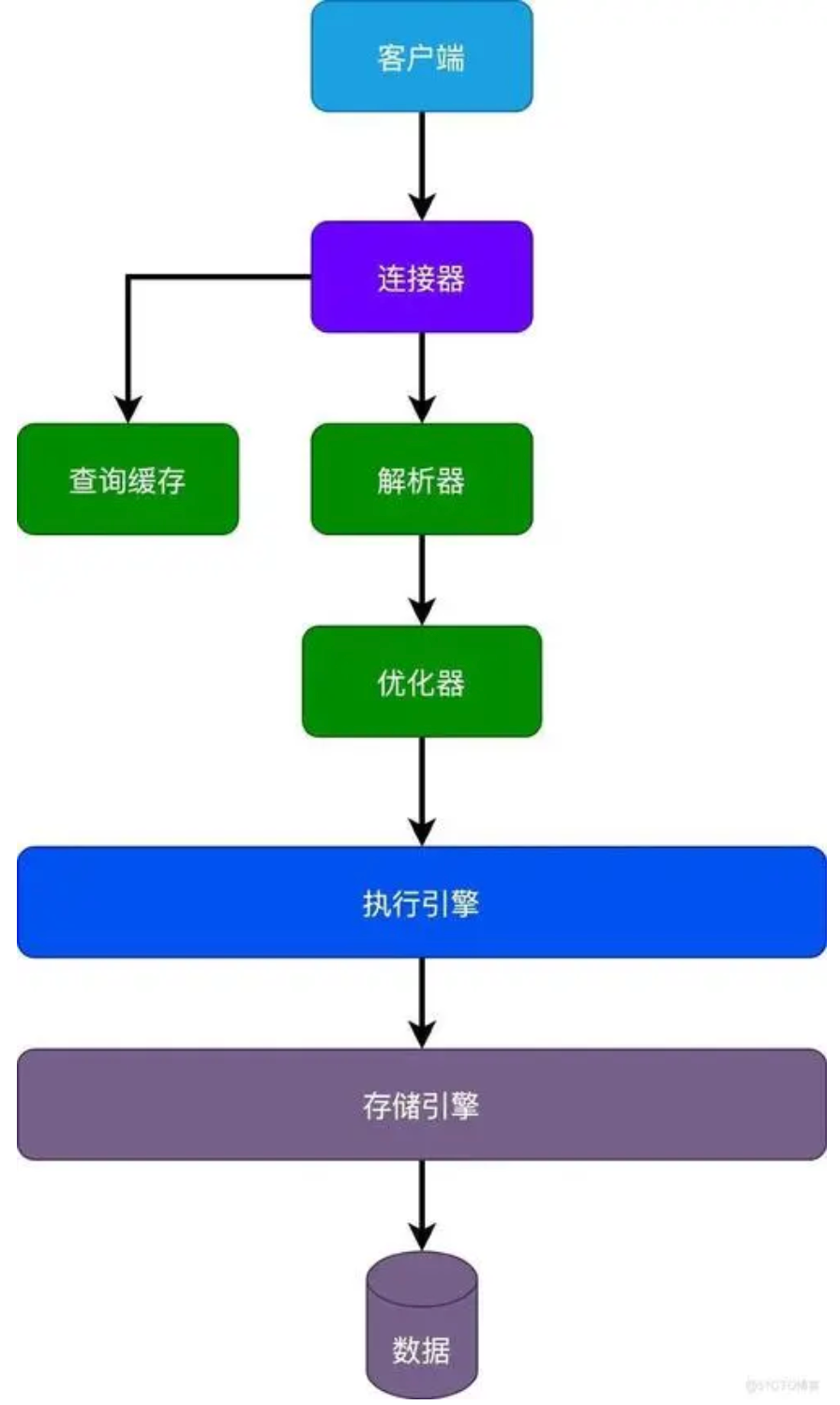
除了上述的基本过程外,一条SQL语句的执行还可能涉及其他一些复杂的操作和机制,比如锁管理、并发控制、事务管理等,这些操作和机制确保了多个用户可以同时访问数据库,而不会相互干扰或破坏数据的一致性,这才算是一条SQL语句的执行的全部过程。
通过本文的分享,大家想必都知道了一条SQL语句的执行是一个复杂而精细的过程,涉及多个阶段和组件的协同工作。一条SQL语句的执行经历了接收与解析、语义检查、查询优化、执行计划生成、查询执行和结果返回等多个过程,这些过程不仅复杂而且精细,需要DBMS的各个组件协同工作才能确保信息的准确无误和查询的高效执行。正是这些组件的精确协作和高效执行,才使得我们能够快速、准确地从数据库中获取所需的信息。随着现在大家对数据安全的重视,我们也需要注意保护数据库的安全性和完整性,避免恶意攻击和数据泄露等风险。
当一条SQL语句提交给数据库管理系统(DBMS)执行时,它通常要经历以下官方定义的过程:
1解析(Parsing):
SQL语句首先被解析器分析,检查语法是否正确。
如果语句中有任何语法错误,DBMS会返回错误信息。
解析器还会将SQL语句转换成内部表示形式,通常是解析树。
2绑定(Binding):
在这一步,系统会确定SQL语句中的变量和参数的值。
绑定过程还会检查引用的表和列是否存在,并确定用户是否有权限执行该操作。
3优化(Optimization):
优化器会生成多种可能的执行计划,并选择成本最低的执行计划。
这个过程考虑了索引的利用、查询的连接顺序、表访问的方式等因素。
4执行(Execution):
根据优化器选择的执行计划,数据库的执行引擎开始执行SQL语句。
执行引擎与存储引擎交互,从磁盘获取数据,进行必要的计算和过滤。
5返回结果(Result Return):
执行完成后,结果集被返回给用户或应用。
如果是查询语句,返回的是数据;如果是数据修改语句(如INSERT、UPDATE或DELETE),返回的是受影响的行数。
解析(Parsing):首先,数据库需要理解你提交的SQL语句是什么意思。这个过程就像是翻译,数据库会检查你的语句语法是否正确,如果不正确,它会报错并告诉你哪里有问题。如果语句没问题,数据库就会将其分解成更小的部分进行进一步处理。
分析(Analysis):接下来,数据库会分析这条SQL语句想要做什么,比如是查询数据、插入数据还是删除数据等。同时,它还会检查你是否有权限执行这个操作,比如你能不能查看某个表的数据。
优化(Optimization):为了高效地执行SQL语句,数据库会尝试找到执行任务的最佳方式。这一步就像是规划路线,数据库会考虑不同的执行计划,选择最快或者资源消耗最少的方式来执行你的查询。
执行计划生成(Execution Plan Generation):基于优化阶段的结果,数据库会产生一个详细的执行计划,这个计划详细说明了如何一步步获取到你需要的数据。想象一下,这就像是一份详细的烹饪食谱,告诉你先放什么后放什么,以最快做出美味的菜肴。
执行(Execution):现在到了实际行动的时候,数据库开始按照执行计划去读取或修改数据。如果是一个查询请求,数据库会从存储在磁盘上的数据文件中查找相关数据,可能还会用到索引来加速查找过程。查找到的数据会被临时存储起来准备返回给你。
获取结果(Fetch Results):最后,数据库把查询到的数据整理好,按照你要求的格式(比如表格形式),通过网络发送回你的电脑或者应用程序。这时,你就能看到查询结果了。
作为一位深度使用过多个云厂商AI服务的开发者,我近期关注了百炼的最新动态;核心感受是阿里云正通过清晰的技术栈和切实的降本增效,为我们个人开发者从原型验证走向生产部署铺平道路,但最后一公里的精细化体验仍有提升空间。 以下是我的具体体验与思考: 我利用通义系列模型快速构建了一个面向内部技术文档的问答系统。整体部署流程,特别是通过ROS的一键部署,体验确实高效,显著降低了从零搭建RAG系统的工程门...
🎁嘿,大家好!👋 ,今天跟大家聊聊AI技术如何助力短剧领域的创新发展。随着AI技术的飞速发展,短剧创作迎来了前所未有的变革。这不仅仅是技术的进步,更是创意和效率的双重提升。🚀 AI助力短剧领域的创新 智能编剧辅助 创意生成:AI可以基于大数据分析,生成多种剧情梗概和创意点子。这对于编剧来说,就像是一个无穷无尽的创意宝库,可以激发更多的灵感。💡 剧本优化:AI还可以帮助编剧优化剧本,检...
P人出游,你是否需要一个懂你更懂规划的AI导游呢? LLaMA Factory是一款低代码大模型微调框架,集成了百余种开源大模型的高效微调能力,使您无需深入理解复杂算法即可轻松进行模型微调。阿里云的人工智能平台PAI提供一站式机器学习服务,覆盖从数据预处理到预测的全流程,并支持多种深度学习框架与自动化建模,大幅降低了使用难度。通过结合PAI与LLaMA Factory,用户能够充分发挥二者优...
建议:将通义灵码直接接入到阿里云函数计算,让更多的普罗大众可以使用自然语言实现自己的编程需求,例如自动获取招考公告等。 在当今数字化时代,编程不再是专业人士的专属技能。随着人工智能技术的发展,越来越多的普通人也开始尝试通过自然语言来实现自己的编程需求。通义灵码作为一种创新的自然语言处理工具,能够帮助用户更加便捷地完成各种编程任务,比如自动获取招考公告等。为了进一步推广这一技术,建议将通义灵码...
送我,我是学生!!!

