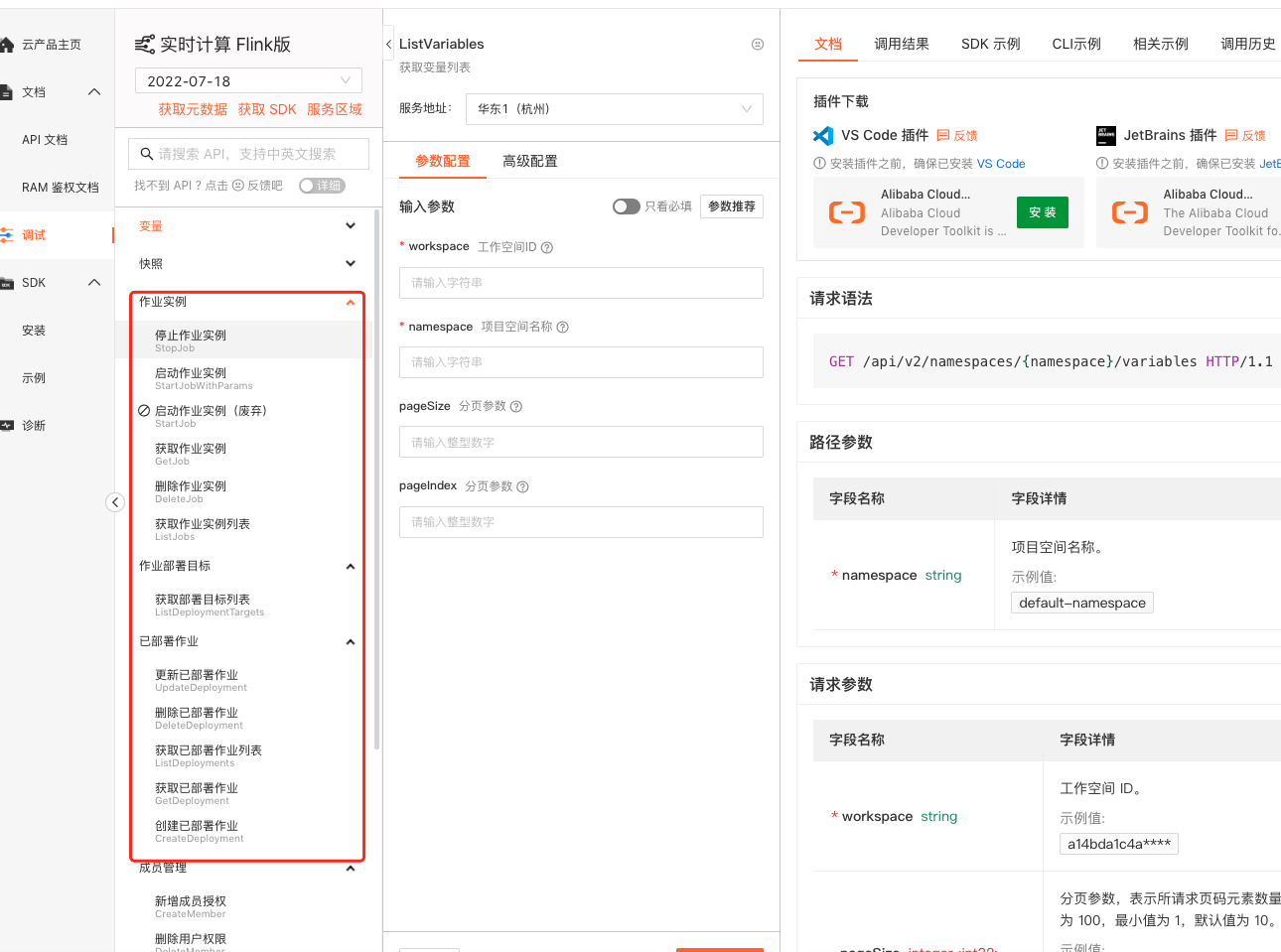
实时计算平台上的flink作业血缘这块有对外暴露OpenAPI进行查询么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是的,实时计算平台上的Flink作业血缘功能支持通过OpenAPI进行查询。> 虽然具体的API调用细节和示例未直接在提供的文档中展示,但提到了OpenAPI的存在以及其签名机制遵循RPC风格,并且指出已有为开发者封装的常见编程语言SDK可直接调用以访问血缘信息,无需直接处理底层技术细节。如果默认提供的SDK不满足需求,用户也可在一定的技术指导下自建签名对接服务。
这意味着用户可以通过调用实时计算服务的API来获取Flink作业的表级别和字段级别的血缘关系,进而实现自动化管理和分析数据流动、依赖关系等,提升数据管理和故障排查的效率。为了使用API,用户需要准备身份账号及访问密钥(AccessKey
请注意,实际应用中应查阅最新的API文档以获取准确的调用方法、参数说明及任何更新的限制条件。
相关链接
查看血缘关系 背景信息 https://help.aliyun.com/zh/flink/user-guide/view-data-lineage
Flink本身并没有直接提供关于作业血缘的OpenAPI接口。作业血缘通常指的是数据在处理过程中的流转路径,包括数据源、转换操作以及目标数据接收方等。然而你可以通过以下几种方式来获取相关信息:
Flink REST API:
Flink提供了REST API来监控和管理运行中的作业。这些API可以让你查询作业的状态、度量指标等信息,但默认情况下并不提供血缘信息。你可能需要根据这些API返回的数据自行构建血缘图。
扩展Flink:
如果你的实时计算平台是基于Flink构建的,并且有定制化的需求,那么可以考虑扩展Flink的REST API或者实现自定义的服务来支持血缘查询。这通常涉及到对Flink源码的理解和修改。
使用外部工具或服务:
有些第三方工具和服务可能会提供与Flink集成的功能,用于追踪作业血缘。例如,Apache Airflow、Apache Nifi等数据管道工具可以通过与Flink集成来追踪数据流。
自建服务:
可以自己开发一个服务来解析Flink的作业配置和运行时状态,然后构建出作业血缘图。这可能涉及读取Flink的检查点信息、作业图等。
Flink 本身并没有直接提供血缘(lineage)查询的 OpenAPI。血缘是指数据流从源头到目标之间的流动路径和转换过程。在实时计算平台上,血缘信息通常用于追踪数据的来源和流向,这对于数据治理、审计和问题排查非常有用。
虽然 Flink 本身没有内置血缘查询 API,但您可以采取一些措施来实现血缘查询功能:
使用 Flink 的 MetaData API:
使用 Flink Web UI:
自定义实现:
使用外部工具和服务:
集成到现有的数据治理平台:
收集血缘信息:
存储血缘信息:
提供查询接口:
前端展示:
集成到现有平台:
如果您需要具体的代码示例或更详细的实现指南,请提供更多信息,比如您使用的实时计算平台的详细情况以及您希望集成的系统类型,这样我可以为您提供更具体的建议。
没有找到具体的官网文档说明一定有,
你需要去控制台里面看看你的参数
地址
https://realtime-compute.console.aliyun.com/console/cell?spm=a2c6h.13066369.aillm.1.464dfc0eFUSlUI#/region/cn-shanghai/resource/all/dashboard
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。