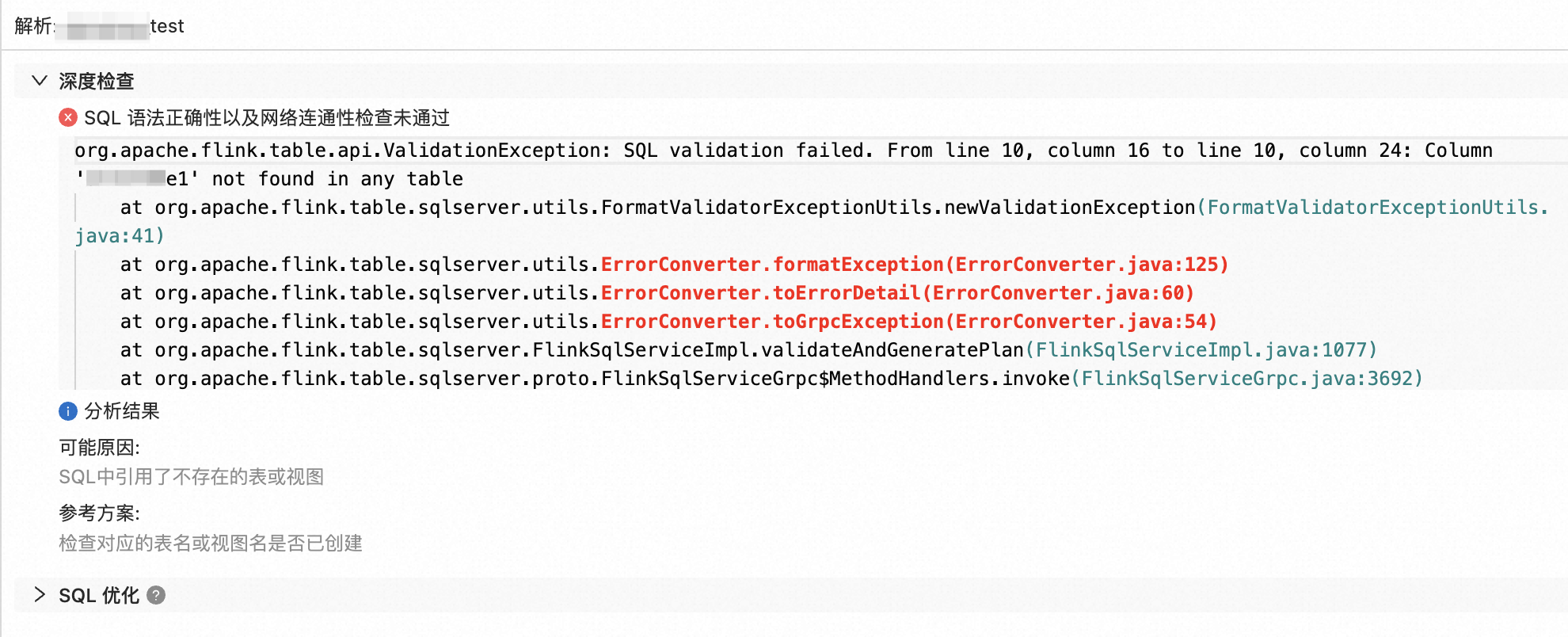
实时计算Flink平台vvr上如何针对实时流作业创建其伴生的周期性的数据质量检查跑批作业?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在实时计算 Flink 平台上,针对实时流作业创建伴生的周期性数据质量检查跑批作业,通常可以通过以下步骤实现:
首先,需要定义数据质量检查的逻辑。这通常包括:
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env, settings);
// 注册输入表
tEnv.executeSql("CREATE TABLE input_table (...) WITH (...)");
// 注册输出表,用于记录检查结果
tEnv.executeSql("CREATE TABLE output_table (...) WITH (...)");
// 定义数据质量检查的查询
String dataQualityCheckQuery = "SELECT ..., COUNT(*) as cnt FROM input_table GROUP BY ... HAVING cnt > 1";
// 执行查询并将结果写入输出表
tEnv.executeSql(dataQualityCheckQuery).insertInto("output_table");
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: flink-data-quality-check
spec:
schedule: "0 */6 * * *" # 每6小时运行一次
jobTemplate:
spec:
template:
spec:
containers:
- name: flink-job
image: my-flink-image:latest
args: ["--job-classname", "com.example.DataQualityJob"]
restartPolicy: OnFailure
在实时计算Flink平台vvr上,针对实时流作业创建其伴生的周期性的数据质量检查跑批作业,通常涉及以下几个步骤。由于直接针对“vvr”这一特定平台的具体操作细节可能不在公开资料中详细列出,以下步骤将基于一般性的Flink操作原理和最佳实践进行说明:
定义数据质量检查规则
首先,需要明确数据质量检查的具体规则,这些规则可能包括数据的准确性、一致性、完整性、实时性等方面的校验。例如,可以检查数据是否在规定的时间范围内到达、数据格式是否符合预期、数据字段是否完整等。
配置Flink作业
在Flink中,可以通过编写Flink程序来配置数据质量检查作业。这通常涉及到以下几个方面的配置:
数据源配置:指定需要检查的实时流数据源。
窗口配置:根据数据质量检查的需求,配置合适的窗口(如滑动窗口、翻滚窗口)以及窗口的大小和滑动/翻滚间隔。这些配置决定了数据质量检查的频率和范围。
处理逻辑:在窗口中实现数据质量检查的具体逻辑,如比较数据值、验证数据格式等。
结果输出:配置检查结果的输出方式,如将检查结果写入日志、数据库或发送报警通知等。
使用Flink的定时器:在Flink程序中设置定时器,定时触发数据质量检查作业的执行。
集成调度系统:将Flink作业集成到现有的调度系统中(如Apache Airflow、Apache DolphinScheduler等),通过调度系统来定时触发作业的执行。
平台内置功能:如果vvr平台提供了内置的作业调度功能,可以直接利用这些功能来配置周期性任务。
实时监控:通过Flink的监控工具(如Flink Dashboard、Grafana等)实时监控数据质量检查作业的执行情况和结果。
设置报警阈值:为数据质量检查的关键指标设置报警阈值,一旦指标超过阈值,则触发报警通知。
报警通知:配置报警通知的方式(如邮件、短信、Slack等),确保相关人员能够及时收到报警信息。
请注意,由于“vvr”可能是一个特定于某个组织或产品的平台名称,因此上述步骤中的具体操作细节可能需要参考该平台的官方文档或联系技术支持获取。
进入阿里云实时计算控制台,选择目标工作空间。
上传数据质量检查脚本:
在工作空间的操作列下,点击“控制台”。
导航至“资源管理”,点击“上传资源”。
上传您的数据质量检查Python脚本或相关依赖文件。确保文件路径符合要求,如使用OSS Bucket存储,则路径为oss:///artifacts/namespaces/<项目空间名称>/;如果是全托管存储,则路径为oss://flink-fullymanaged-<工作空间ID>/artifacts/namespaces/<项目空间名称>/
创建周期性跑批作业
选择作业类型为“Python”,部署模式依据需求可选“流模式”或“批模式”(数据质量检查通常更适合批处理模式)。
填写作业名称,如data-quality-check-batch。
选择合适的Flink引擎版本,如vvr-8.0.7-flink-1.17。
指定已上传的数据质量检查Python文件地址。
如果脚本为.py文件,无需填写Entry Module;若是.zip文件,则需指定Entry Module。
设置Entry Point Main Arguments,指向数据质量检查的输入数据或配置文件路径。
添加任何必要的第三方Python库到Python Libraries中,以支持数据质量检查逻辑。
在作业配置中寻找“调度”或“触发器”设置,虽然基础步骤未直接提及,但通常在高级设置中允许设置Cron表达式或定时触发规则,以定义作业的周期性执行计划。例如,设置每天凌晨执行一次的Cron表达式为0 0 0 ?。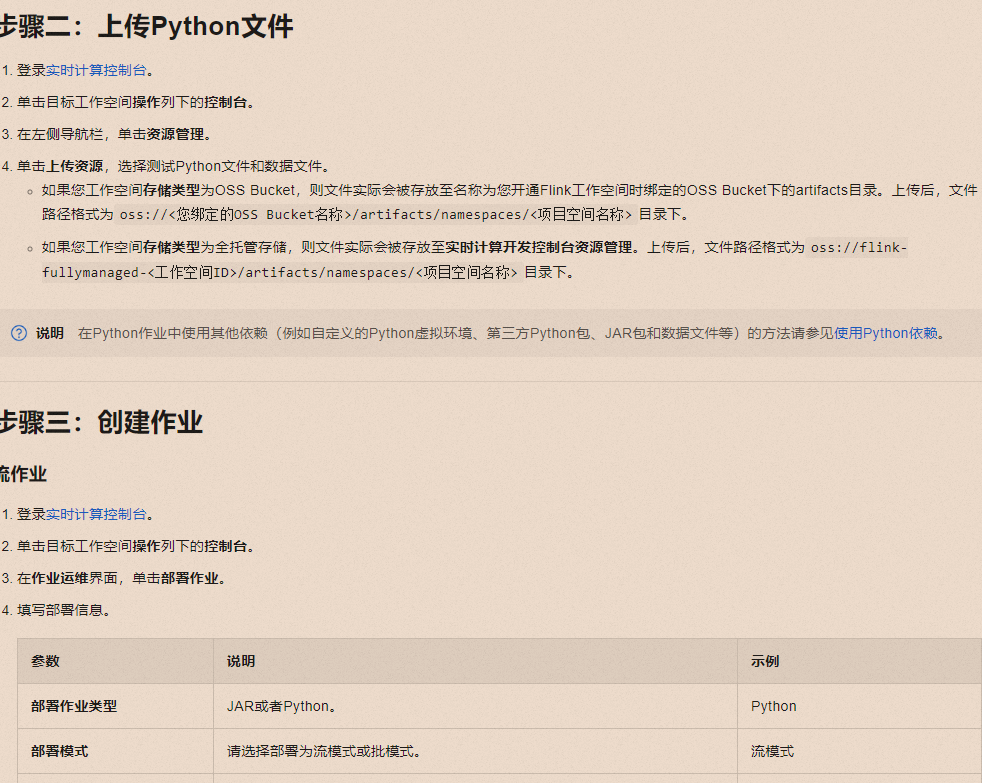
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。