
云数据仓库ADB_mysql的分区不能想hive那样使用吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
云数据仓库AnalyticDB MySQL版(简称ADB MySQL)的分区功能与Hive的分区机制存在一定的差异,但两者在设计目标上都旨在优化查询性能和管理大规模数据。以下从几个关键方面对比ADB MySQL与Hive的分区使用方式,并解答您的问题。
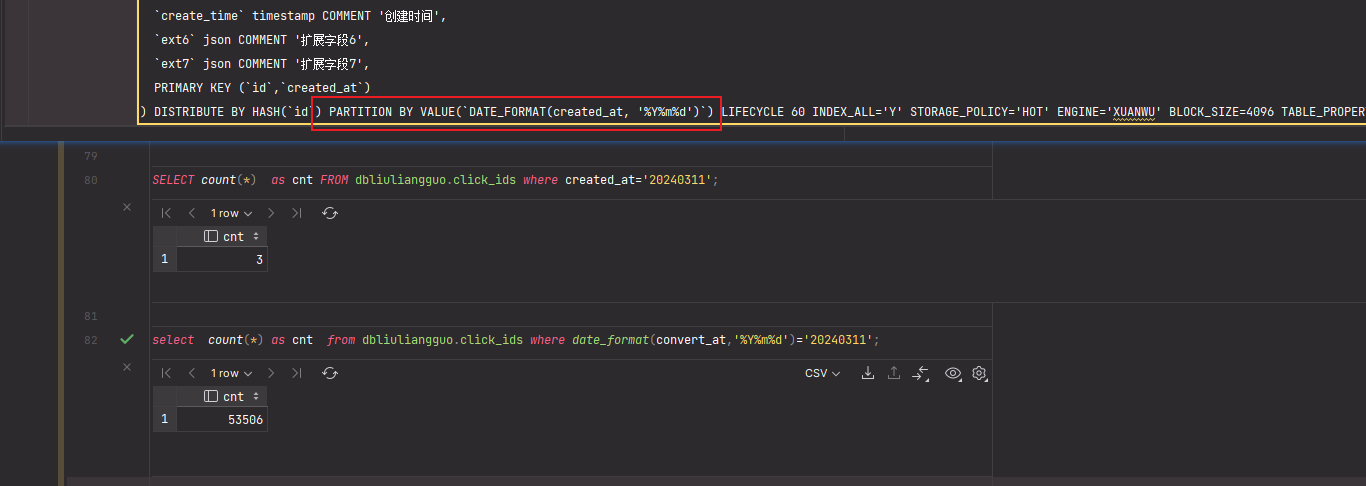
ADB MySQL的分区键定义方式与Hive有所不同: - ADB MySQL支持的分区键类型包括数值类型、日期时间类型或表示数字的字符串类型。如果写入数据时分区键值不符合这些类型要求,可能会导致partition format function error错误。 - Hive的分区键通常基于目录结构,支持更灵活的分区字段类型,例如字符串、日期等。
此外,ADB MySQL对分区键的定义方法有严格限制,仅支持以下三种方式: 1. PARTITION BY VALUE(column) 2. PARTITION BY VALUE(DATE_FORMAT(column,'format')) 3. PARTITION BY VALUE(FROM_UNIXTIME(column,'format'))
重要提示:ADB MySQL不支持使用除DATE_FORMAT和FROM_UNIXTIME以外的其他函数定义分区键。这与Hive中可以通过自定义函数灵活定义分区的方式存在显著差异。
在查询分区表时,ADB MySQL和Hive的行为也有所不同: - ADB MySQL:虽然查询时不要求过滤条件中必须包含分区键,但如果将分区键作为过滤条件,可以显著加速查询性能,因为只需扫描相关分区,而无需遍历整个表。 - Hive:同样推荐在查询时指定分区键以优化性能,但由于Hive的分区是基于文件系统目录结构实现的,其查询优化器对分区剪枝的支持更为成熟。
ADB MySQL提供了生命周期(LIFECYCLE)功能,用于自动清理过期分区数据。然而,其行为与Hive的TTL(Time To Live)机制存在一定差异: - 在ADB MySQL中,超过生命周期的分区数据不会被立即清理,而是需要等待表的BUILD任务完成后才会删除。这意味着即使设置了LIFECYCLE为30天,仍可能查询到超过30天的数据。 - Hive:通常通过手动或调度工具(如Apache Oozie)实现分区数据的清理,灵活性更高。
如果您希望将Hive中的分区数据迁移到ADB MySQL,可以通过Hive数据迁移功能实现。具体步骤包括: 1. 创建Hive数据源。 2. 新建数据迁移任务,配置源端和目标端参数。 3. 启动迁移任务,将Hive元数据和数据迁移到OSS,并通过元数据发现功能导入至ADB MySQL。
需要注意的是,迁移过程中可能会因分区键定义方式的不同而导致兼容性问题。因此,在迁移前建议检查Hive表的分区字段是否符合ADB MySQL的分区键要求。
ADB MySQL支持冷热数据分层功能,可以根据数据访问频率将数据存储在不同的存储介质上(如热数据存储在高性能存储中,冷数据存储在低成本存储中)。这一功能在一定程度上弥补了Hive中需要手动管理冷热数据的不足。
ADB MySQL的分区功能虽然在某些方面不如Hive灵活(如分区键定义方式和生命周期管理),但在查询性能优化和冷热数据分层方面提供了独特的支持。如果您希望在ADB MySQL中实现类似Hive的分区使用方式,建议: 1. 确保分区键的定义符合ADB MySQL的要求。 2. 在查询时尽量使用分区键作为过滤条件以提升性能。 3. 利用Hive数据迁移功能将Hive分区数据迁移到ADB MySQL,并根据需求调整分区策略。
如有进一步疑问,请随时联系!
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。

