
我们在使用flinkcdc 进行 tidb数据同步时,遇到内存增量超大问题,望大神帮忙看看什么问题
tidb版本 6.5.2,
flink-connector-tidb-cdc-3.0.1
flink-sql-connector-tidb-cdc-3.0.1,
flink版本 1.19.0
flink使用Standalone模式 部署了三台节点
1台jobmanager 1,taskmanager 2台
flink参数配置
taskmanager 内存16384m
parallelism 12
numberOfTaskSlots: 4
问题现象就是tidb 一个表数量超过一千万后,内存急剧增长,同步很慢,fullgc频繁发生,cpu消耗沾满,同步停顿,即使完成同步后 也不会释放jvm内存
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的情况,Flink CDC在同步TiDB表数据时遇到内存暴增、Full GC频繁以及CPU高消耗的问题,结合我所掌握的知识库信息,以下是一些可能的原因分析及解决方案建议:
数据处理速率与资源不匹配
Checkpoint配置不当
Flink作业或连接器配置问题
parallelism)、Task Slot数量与实际数据处理需求不匹配,可能导致资源分配不合理,影响性能。TiDB CDC数据特性
增加并行度:提高parallelism,减少每个TaskManager的任务槽numberOfTaskSlots,使得每个并行实例处理的数据量减少。
调整Flink配置:
buffer.size:增加缓冲区大小,减少网络传输的次数。
state.backend.fs滚动策略:增加状态检查点的间隔或减少状态大小。
优化Flink作业:检查SQL查询是否有优化空间,比如减少中间结果的大小。
限制数据速率:使用速率限制连接器,避免数据过快导致内存积压。
可能是您的Flink作业设置的并发度是否过高
建议降低作业并发数,降低连接池Size大小或优化sql逻辑是否可以使用CDAS来复用连接。
另外看看Flink作业Checkpoint间隔时间是否设置得当。如果Checkpoint间隔过长,可能会导致大量状态数据积累在内存中,增加内存使用。应根据业务需求合理设置Checkpoint间隔时间,避免长时间等待导致内存暴增
可能的原因
状态后端配置不当:
Flink CDC 连接器需要维护大量的状态来跟踪 TiDB 的变更数据,如果状态后端配置不当,可能会导致内存使用过多。
任务并行度配置:
并行度设置过高或过低都可能导致内存问题。过高的并行度可能导致数据倾斜和内存碎片化问题。
JVM 参数配置:
默认的 JVM 参数可能不适合您的应用场景,尤其是当处理大量数据时。
数据倾斜:
如果数据分布不均匀,某些 TaskManager 可能会处理更多的数据,从而导致内存压力过大。
流式处理的水位线延迟:
如果水位线延迟较高,可能会导致状态后端中存储的数据量增加。
解决方案
优化状态后端配置:
考虑使用 RocksDB 状态后端来提高性能和减少内存使用。
如果您已经在使用 RocksDB 状态后端,考虑调整其配置以优化内存使用,例如 state.backend.rocksdb.memory-allocator 和 state.backend.rocksdb.compaction-filter。
调整并行度:
根据实际数据量和机器资源,适当调整并行度。可以尝试降低并行度以减少数据倾斜和内存碎片化问题。
优化 JVM 参数:
增加堆内存大小,例如 -Xmx 和 -Xms。
调整年轻代和老年代的比例,例如使用 -XX:NewRatio。
启用并配置 CMS 或 G1 GC,以减少 Full GC 的频率。
考虑使用 -XX:+UseG1GC 和 -XX:MaxGCPauseMillis=200 来优化 GC 暂停时间。
监控和诊断:
使用 Flink 的 Web UI 或其他监控工具来监控内存使用情况和 GC 活动。
使用 JMX 或类似工具来监控 JVM 的性能指标。
使用 Flink 的 Checkpointing 功能来定期保存应用的状态,以便在失败时快速恢复。
数据倾斜问题:
检查数据分布,如果存在数据倾斜,可以尝试重新分区或调整分区键。
使用 REPARTITION 或 REDISTRIBUTE 来重新分配数据。
调整水位线策略:
考虑调整水位线生成策略,以减少延迟。例如,可以调整 watermark.strategy.delay 和 watermark.strategy.period。
检查 Flink CDC 连接器配置:
确保 Flink CDC 连接器配置正确无误,例如 scan.startup.mode 应该设置为 initial 或 latest-offset。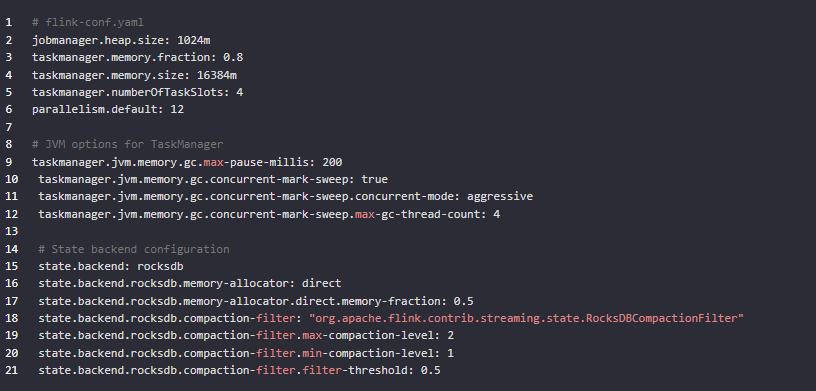
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。




