Flink有没有全局监控?客户端所有提交的任务,都能监控到,比如提交一个sql,可以获取提交的ddl 和dml 
这种机制有实现的吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink 是一个分布式流处理框架,因此,作业不仅可以在具有跨多个抽象层(虚拟化、Kubernetes 等)的大量不同环境的多台机器上以高并行度运行,而且还可以在不同的部署模式(应用程序、每个作业、会话模式)中运行. 较大的工作通常会给监控和解释底层发生的事情带来一些挑战。
除此之外,Flink 作业运行具有自定义业务逻辑的任意用户代码,并且应用程序行为的巨大差异可能会影响底层资源并暴露不同的瓶颈。
flink webui界面给出来很多的指标,但并没有地方可以配置监控,也没有可以定制化展示某些我们关心的关键指标,为了方便监控flink实时任务的内部状态详情我们需要使用更直观的方式展示出我们关心的指标,并配置上告警
这里选择使用prometheus+pushgateway+alermanager+自定义dingding-web-hook的方式,架构图如下面
架构图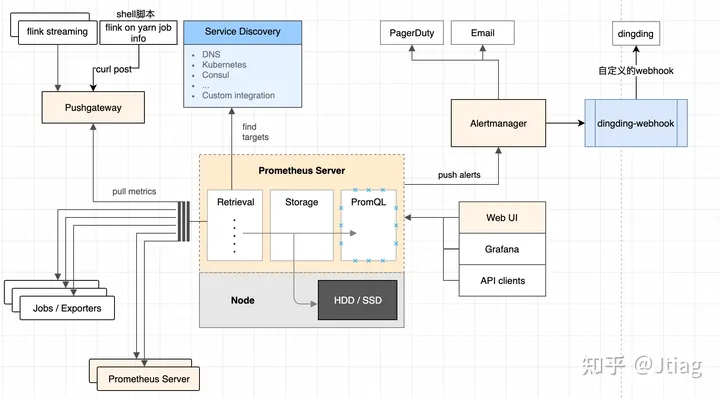
shell 脚本信息主要获取flink on yarn相关的信息,如yarn中flink的任务名 flink任务状态、applicationId、jobId、背压百分比、异常信息等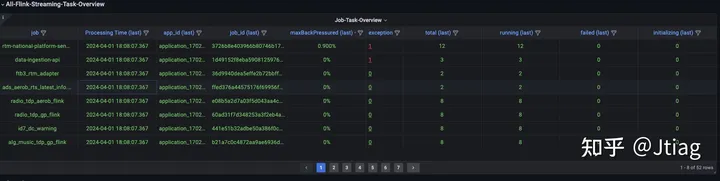
dingding-wdbhook主要用来自定义推送到钉钉的信息,从数据库获取对应告警任务的负责人,指定@运维人员+业务负责人;自定义发送的告警内容等
主要监控指标
概览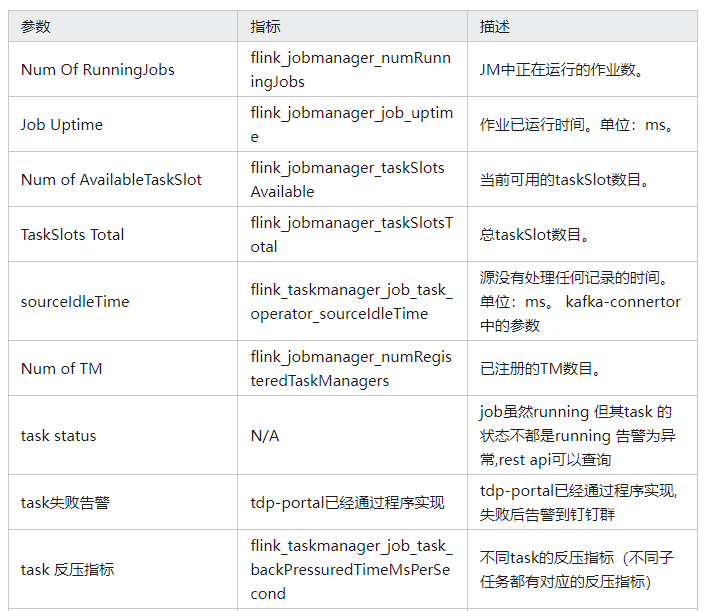
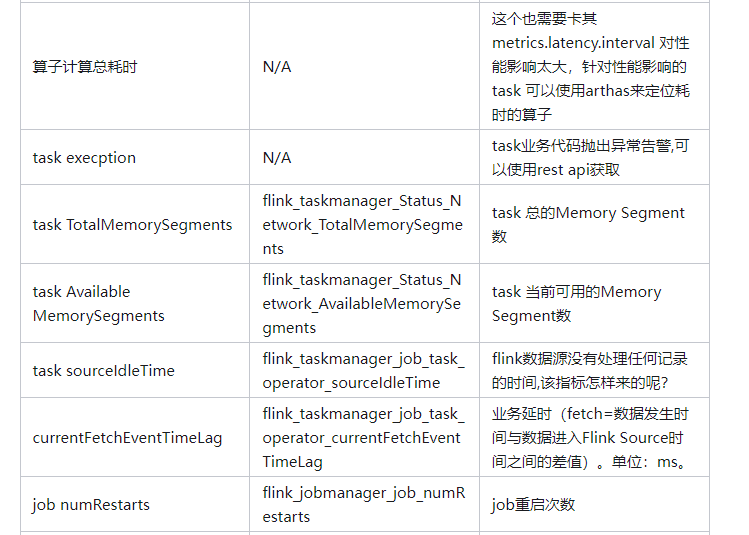
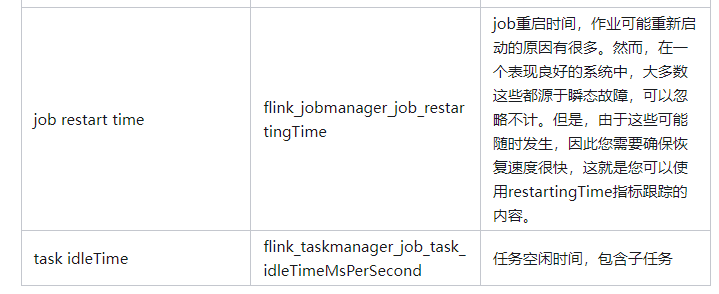
应用程序运行状况
link 应用程序需要注意的明显事项是它是否仍在运行(正常运行时间)或它不运行/重新启动的频率(numRestarts)。您应该为每一个设置适当的警报。
作业可能重新启动的原因有很多。然而,在一个表现良好的系统中,大多数这些都源于瞬态故障,可以忽略不计。但是,由于这些可能随时发生,因此您需要确保恢复速度很快,这就是您可以使用restartingTime指标跟踪的内容。
如果restartingTime很高并且您有一个延迟关键的工作,您可能需要在这方面对其进行调整。
flink运行状态、及背压、checkpoint概览信息
延迟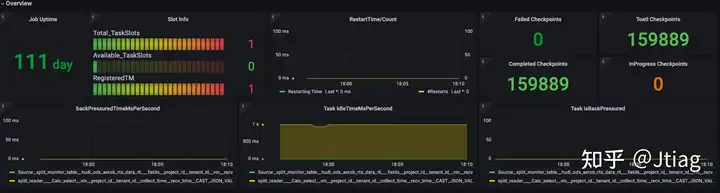
对于使用事件时间处理的应用程序,水印继续前进很重要。通过观察当前时间戳和水印之间的差异,可以很好地监控对时间敏感的操作符(例如过程函数和窗口)的水印。如果此事件时间偏差 或事件时间滞后异常高,则表明 (1) 您正在处理较旧的事件,可能是在从中断中恢复期间,或者 (2) 上游的某些东西很长时间没有发送水印时间,例如,源变得空闲。在后一种情况下,您需要找到解决方法或修复您的代码。
要从内置指标中获取事件时间延迟,我们可以绘制收集currentOutputWatermark指标值与实际值的时间戳,并设置适当的警报。
我们可以在不同的层次上这样做,例如,
为了收集有关事件时间如何在整个作业图中取得进展的信息,我们可以按作业的不同运算符进行分组;或者
如果我们想检查子任务之间的事件时间偏差,那么我们绘制特定运算符的每个子任务,如图所示。
然而,内置度量方法的一个缺点是处理时间时间戳,至少在 Prometheus 中,只有第二个精度。对于非常低延迟的用例,这可能还不够……
内置-Flink 监控:Event-time lag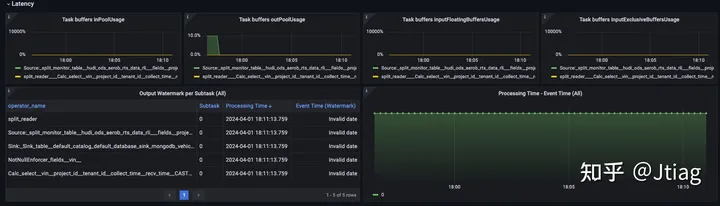
一般来说,上面的事件时间滞后定义运行良好,但它还包括事件在外部系统中等待时所花费的时间(在 Flink 之外,例如,在您的 Kafka 主题中,甚至在写入它之前) )。如果您想要更细粒度的分辨率,只查看在 Flink 中花费的时间,或者监控不同风格的处理延迟,例如,通过从异步 I/O、延迟事件处理等中排除延迟,或者想要要包括在端到端完全一次模式下运行时来自事务接收器的延迟,您将需要自己的自定义指标来反映您的定义。
例如,在我们的training exercises中,我们创建了自己的自定义eventTimeLag指标,每当窗口触发时我们都会更新该指标。由于我们使用直方图,我们还可以轻松绘制可能对 SLA 管理有用的百分位数。
或者,您也可以查看 Flink 的内置延迟标记,但它们更像是一个调试工具,并且在定义上有点特殊。

自定义-Flink 监控:Event-time lag
最后但同样重要的是,我想强调一些特定于连接器的指标,以表明我们是否跟上外部系统的步伐。例如,从 Kafka 或 Kinesis 读取时,records-lag-max和millisBehindLatest分别指示消费者(组)在消息队列头部之后的距离。为方便起见,Flink 将这些连接器指标转发到 Flink 的指标系统中。
records-lag-max 显示任何分区的记录数方面的最大滞后。随着时间的推移,价值的增加是消费者群体跟不上生产者步伐的最好迹象。
millisBehindLatest 显示消费者落后于流头部的毫秒数。对于任何消费者和 Kinesis 分片,这表明它落后于当前时间多远。
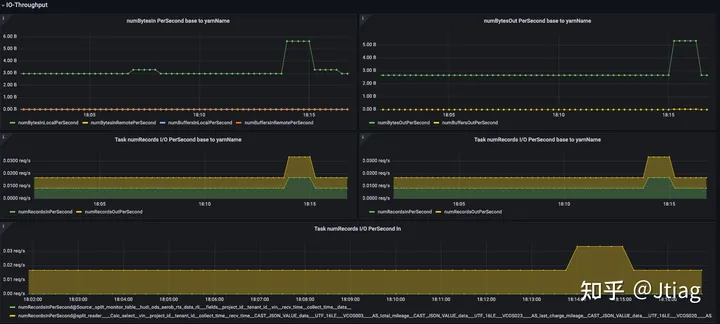
吞吐量
Flink 为每个子任务提供了numRecords(In|Out)PerSecond或numRecords(In|Out)等指标。尽管这些可用于您工作中的所有任务,但由于在 Flink 中向上游传播的背压,通常监控源输出的吞吐量并在该源上配置警报就足够了。每个任务和/或子任务的其他详细信息可能会在故障排除和性能调整期间为您提供帮助。
JVM指标(一):持续监控
任何Status.JVM.Memory.*指标都将帮助您密切关注 JVM 内存及其组件。
请参阅Metrics以获取 Flink 提供的系统指标的完整列表。可以在 Flink 之外为底层系统组件收集更多指标。
JVM指标(二):故障排除
作业管理器
JobManager 通常不会出什么问题,除了在以下情况之一中资源配置不足。如果要维护的 TaskManager 的数量很高,JM 需要更多内存来维护内部数据结构,但最重要的是,需要更多 CPU 来处理由检查点协调器协调的各种保活消息和检查点消息和数据。作业管理器。同样,如果您有许多作业要维护(在会话集群中)或检查点频率很高,您可能还希望增加可用(峰值)CPU 时间。说到检查点,根据您的作业大小和state.storage.fs.memory-threshold的配置,您的 JM 可能需要更多资源来构建内联检查点数据并将其写入_元数据文件。如果您在应用程序模式下部署,JM 还将执行用户代码,并且可能需要额外的 CPU、内存……为此,具体取决于您的业务逻辑。
对于所有这些,您可以检查诸如来自 Kubernetes 的系统级指标之类的指标,或诸如Status.JVM.CPU.、Status.JVM.Memory.或Status.JVM.GarbageCollector.*等 Flink 指标。如下所示的仪表板。它们将帮助您识别上述情况,然后进行相应调整。
任务管理器
在 TaskManager 上,可以使用相同的系统级指标来识别实际数据处理的问题,例如负载不平衡、内存泄漏、有问题的 TM 等。虽然您可能想设置 TM 的 CPU 使用警报,这可能太窄了。监控应用程序的吞吐量是一个更好的瓶颈指标,因为它包括所有资源,例如磁盘、网络等。但是,在进行故障排除时,您可能希望确定Status.JVM.CPU.Load和其他资源所在的具体资源瓶颈又有用了。还记得像这样的负载测量可能会产生误导,因为例如,0.021 的值可能已经意味着 48 核机器上具有 1 个 CPU 的 TM 容器的 100% 负载。
CPU 和内存概览
根据您的状态后端,您可能需要关注不同的指标。
例如,对于基于堆的状态后端,最重要的部分是监控每个 TM 的Status.JVM.Memory.Heap.Used,它是该 TM 上状态大小的指标。它不应超过您设置的限制,并且您应该在达到它们之前进行扩展(为此设置警报可能会有所帮助!)。堆/状态大小的增长可能来自于你的task正在做的工作的合法增加,例如,更多的实体要处理导致越来越多的键,或者来自 Flink 由于事件时间偏差增加而为你缓冲更多数据在不同的流之间或未能清理状态(在您的代码中!)。所涉及的每个任务的附加指标,例如numRecordsIn/Out将帮助您估计工作的负载特征。
由于涉及堆内存,垃圾收集(GC)显然也可能存在问题。有一些 JVM 级别的统计信息可以帮助您跟踪这些信息,例如Status.JVM.GarbageCollector..[Count|Time] 和更多详细信息也可以在需要单独启用的 JVM 的 GC 日志中获得。由于这不是 Flink 特有的,所以我将在这方面遵循常见的文献。
即使 Flink 的 RocksDB 状态后端是在堆外运行的,你仍然应该留意内存和 GC。这是由于一个不幸的事实,即使 RocksDB 升级了 Flink 1.14(到 RocksDB 6.20.3),尽管 Flink 尽力而为,但无法完全控制 RocksDB 如何使用其内存。在某些情况下,RocksDB 想要使用比分配更多的内存可能会失败。为了尽早得到通知,即在 TM 在达到分配的内存限制后被杀死之前,您应该设置有关已使用内存与可用内存和最佳使用系统级指标的警报,例如container_memory_working_set_bytes和container_spec_memory_limit_bytes来自 Kubernetes,其中包括您的作业获取的所有类型的内存,包括 JVM 无法跟踪的内存。如果您发现自己的task接近极限,对于 RocksDB,您可以调整框架/任务堆外内存或TaskManager 内存布局的 JVM 开销部分。
即使没有基于堆的状态后端,您也应该注意垃圾收集,因为高垃圾收集压力会导致其他问题!使用 RocksDB,这应该只源自 Flink 本身或您的用户代码。
RocksDB
RocksDB 收集了大量低级指标,您可以在阅读其内部结构并研究其调优指南后查看并理解这些指标。我们将尝试为您提供几个关键指标的 TL;DR 版本。您可以在Flink 文档中找到完整的 RocksDB 原生指标集,其中解释了如何启用它们并指出可能对性能产生负面影响的指标。启用后,指标将在..rocksdb范围内公开,我们在下面的指标标识符中省略了该范围。
RocksDB 是一个日志结构的合并树,它使用磁盘上的不可变文件。
删除的数据会在后续文件中标记为已删除;
同样,更新的数据将被写入后续文件以隐藏任何以前的版本。
估计实时数据大小可帮助您识别没有陈旧数据的实际状态大小。
如果这个大小远小于磁盘上的占用大小(空间放大),您可能需要考虑让 RocksDB 更频繁地压缩以清理陈旧数据。
还有total-sst-files-size指标,但如果文件太多,这可能会减慢查询速度。
或者,您也可以使用前面提到的检查点大小指标作为估计,但它们还将包括operator状态(通常很小)和内存中的任何其他内容,例如堆上计时器或用户管理的状态。
background-errors指标表示 RocksDB 内部的低级故障。如果您看到这些,您可能需要检查RocksDB 的日志文件。
RocksDB 写操作首先被添加到内存表中,当它满时,将排队等待刷新(和重新组织)到磁盘。
这个队列的大小是有限的,因此如果刷新没有足够快地完成,它会在 RocksDB 内部产生背压。
实际延迟写入速率 指标显示了这些可能由慢速磁盘引起的写入停顿
在这些情况下,通过更改state.backend.rocksdb.thread.num的配置值来调整每个有状态操作符的后台作业(刷新和压缩)的线程数通常很有帮助,这将在这里增加更多的并发性。
Flink 故障排除:RocksDB 数据大小、错误和写入停滞
压缩是通过将文件合并在一起并仅保留每个数据项的最新版本来从磁盘中删除陈旧数据的过程。
这对于读取性能至关重要,可以通过查看诸如估计等待压缩字节数、 运行压缩数、压缩挂起等指示压缩过程中的瓶颈的指标来检查。
这些可能来自慢速磁盘或未使可用磁盘饱和的低并发。
与停止的写入操作类似,调整state.backend.rocksdb.thread.num可能有助于提高并发性。
与上面的延迟写入速率类似,您可以通过查看is-write-stopped、num-running-flushes和mem-table-flush-pending来进一步排除将内存表刷新到磁盘的过程。
这些指标指示写入繁重的作业,并与系统级 I/O 统计信息一起,允许您微调磁盘性能,例如,通过如上所述的state.backend.rocksdb.thread.num增加并发性。
所有上述指标都有助于解释RocksDB内部发生的情况,并帮助您识别围绕RocksDB调优三角形(空间、写入和读取放大)的参数。实际上,识别后者是有一定挑战的,但如果您发现您的作业不是写入密集型(或者至少没有在写入操作上出现停滞),而且在执行过程中花费大部分时间在RocksDB读取操作中,例如通过状态访问延迟跟踪或使用分析器或Flink自身的火焰图,这是读取放大(和/或磁盘瓶颈)的很好指标。增加压缩工作可能有所帮助,但通常更适合启用布隆过滤器以减少要扫描的数据量。
state access latency tracking
flame graphs
enabling bloom filters
Tip: Check How to manage your RocksDB memory size in Apache Flink
其他指标待续........
参考
Flink 任务实时监控最佳实践
Flink Metrics监控指标和性能优化
美团指标监控
火焰图
监控大型flink任务,监控指标,持续监控
prometheus查询语法
prometheus常用查询
常用函数
常用函数2
yarn rest api
Grafana面板(panel):报警功能(alerts),grafana告警配置
flink 实时程序的日志是否考虑推到日志易 推送级别设置为WARN、ERROR及以上
腾讯云flink监控指标
阿里云flink监控指标
阿里云flink查看监控指标
flink-metrics
metric_reporters
通过flink和Prometheus整合来提供监控,如果某些指标获取不到可以通过flink rest api来获取
flink TM使用的是 Parallel GC
https://zhuanlan.zhihu.com/p/690203247
Apache Flink 提供了全局监控的能力,但是这种监控通常需要通过 Flink 的管理界面(如 Flink Web UI)来实现。Flink Web UI 提供了对集群中所有作业的概览,包括作业的名称、状态、提交时间等信息。
对于 SQL 作业,您可以通过 Flink Web UI 查看提交的 SQL 语句,但是这通常是在作业提交后,通过作业管理器(JobManager)的日志来获取的。如果您想要监控客户端提交的所有任务,包括 DDL(Data Definition Language,数据定义语言)语句,您需要确保客户端在提交任务时将 DDL 语句记录在日志中,并且这些日志可以被 Flink Web UI 或其他监控工具访问。
此外,Flink 还支持将监控数据输出到外部系统,如 Prometheus 或 Grafana,这样您可以从外部系统监控 Flink 集群中的所有作业,包括 DDL 语句。
总的来说,Flink 本身提供了监控集群中所有作业的能力,但是监控 DDL 语句可能需要额外的配置和日志记录。如果您有更具体的监控需求,建议查阅 Flink 的官方文档或社区资源以获取详细的指导。
在Flink中,你可以使用JobManager来监控所有的任务。JobManager是Flink集群的主节点,负责协调任务调度、资源分配以及状态恢复等操作。通过访问JobManager的Web UI(默认端口为8081),你可以在浏览器中查看正在运行的任务、历史任务的状态、任务执行图、系统指标等信息。对于SQL作业,如果你使用的是Flink SQL,那么这些任务也会被JobManager监控。你可以通过Web UI查看每个SQL作业的DDL和DML语句,以及其他相关信息。此外Flink还支持JMX接口,可以通过JMX工具进行更详细的监控和管理
Flink 的 Web UI 提供了作业的实时监控,包括任务运行状态、检查点信息、配置详情等。但它主要关注的是已经提交并正在执行的作业。
通过日志聚合工具(如 ELK Stack、Graylog 等),可以收集和搜索 Flink 作业的日志信息。你可以配置 Flink 以输出更详细的日志,包括客户端提交的 SQL 语句。
Flink提供了全局监控功能。Flink作为一个开源的流处理框架,提供了丰富的监控和日志功能,以便用户可以更好地理解和调试他们的应用程序。Flink的Web UI界面提供了许多指标,虽然它没有提供配置监控的地方,也没有定制化展示关键指标的功能,但用户可以通过集成Prometheus+Pushgateway+Alertmanager+自定义Dingding Webhook的方式,以更直观的方式展示关心的指标并配置告警1。此外,Flink还提供了REST API,通过这些API可以获取到许多重要的监控信息,这对于搭建一个基本的监控系统非常有用2。
Flink的监控系统可以帮助用户了解Flink集群的资源使用情况,包括TaskManager的数量、总槽位(Task Slots)数量、可用槽位数量、正在运行的作业数量以及作业的运行状态等。通过Flink的UI界面或通过API获取的数据,用户可以获得关于集群健康状况的详细信息,这对于及时发现和解决潜在问题非常关键23。
总的来说,Flink通过其内置的Web UI界面和提供的REST API,为用户提供了一种全面的监控解决方案,帮助用户更好地管理和优化他们的Flink作业和集群。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。