
根据咱们指导 我把flink CDC 升级到 2.4.2 版本 还是报这个错误 有其他的办法吗?每天5点准时报这个错误。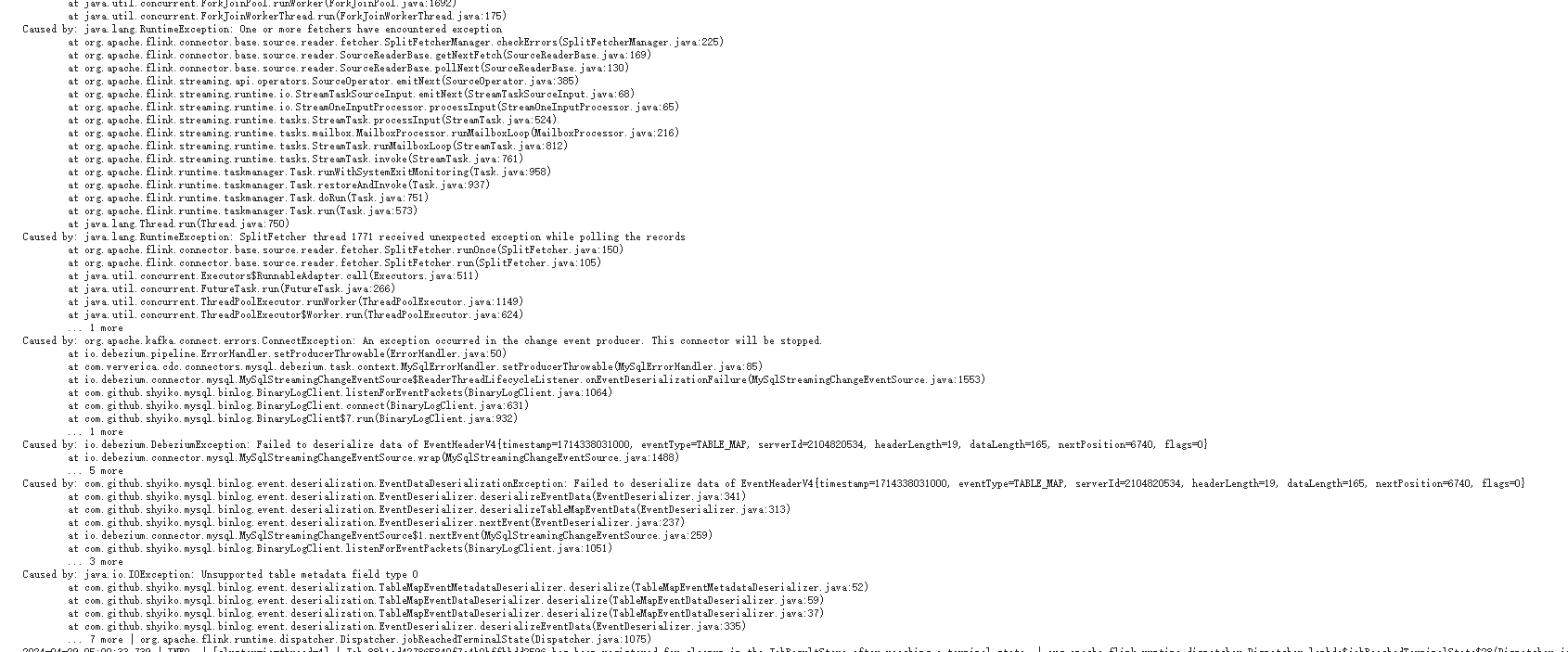
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC 升级到 2.4.2 版本后仍然每天凌晨 5 点报错,这可能与多种因素相关,例如数据源的变更、作业配置问题或资源不足等。以下是针对该问题的详细分析和解决建议:
首先需要明确报错的具体内容,例如: - 是否是 finish split response timeout 异常? - 是否与表结构变更(DDL)相关? - 是否涉及数据重复消费或解析失败?
如果错误信息未明确,请检查 Flink 作业日志中的堆栈信息,定位具体的异常类型。
如果错误是 finish split response timeout,通常是因为 TaskManager 的 CPU 或内存资源不足,无法及时响应 Coordinator 的 RPC 请求。
解决方法: - 增加 TaskManager 的资源:在资源配置页面中,适当增加 TaskManager 的 CPU 核心数或内存大小。 - 优化作业并行度:检查作业的并行度设置是否过高,导致资源分配不足。可以尝试降低并行度以缓解资源压力。 - 监控资源使用情况:通过阿里云实时计算控制台的监控功能,查看作业运行期间的 CPU 和内存使用率,确保资源充足。
如果错误与表结构变更相关(例如 DDL 操作),可能会导致下游表结构不同步或作业报错。
解决方法: - 检查表结构变更策略:Flink CDC 不会自动同步 DDL 变更,仅捕获前后两条数据之间的 Schema 变化。如果上游表发生了 DDL 变更但无新增数据,则不会触发下游的同步。 - 操作建议:手动停止作业,删除下游表,并重新启动作业以无状态方式同步。 - 避免不兼容的表结构变更:在同步期间,避免对表进行不支持的修改(如删除主键列)。否则可能导致作业重启后仍然报错。
如果错误与数据重复消费或解析失败相关(例如 Debezium、Canal 或 Maxwell 投递重复事件),可能是由于故障恢复时的 at-least-once 语义导致。
解决方法: - 启用去重机制: - 在作业参数中设置 table.exec.source.cdc-events-duplicate=true。 - 在源表上定义 PRIMARY KEY,以便 Flink 使用有状态算子对变更事件去重。 - 检查数据源配置: - 如果使用 Debezium PostgreSQL Connector,请确保被监控表的 REPLICA IDENTITY 已配置为 FULL。否则,更新和删除事件可能无法正确解析。 sql ALTER TABLE <your-table-name> REPLICA IDENTITY FULL;
如果错误每天凌晨 5 点准时发生,可能与以下因素有关: - 定时任务干扰:检查是否有其他定时任务(如数据库备份、ETL 作业)在凌晨 5 点运行,导致数据源负载增加或网络延迟。 - Kafka 分区重平衡:如果使用 Kafka 作为消息队列,凌晨 5 点可能发生分区重平衡,导致消费延迟或超时。
解决方法: - 调整定时任务时间:将可能干扰的任务调整到非高峰时段。 - 优化 Kafka 配置:增加 Kafka 的分区数或消费者并发度,减少分区重平衡的影响。
根据知识库资料,Flink CDC 3.0 已经正式发布,并提供了更强大的流式 ETL 数据摄取能力。建议您考虑升级到最新版本,以获得更好的性能和稳定性。
升级步骤: 1. 登录实时计算控制台,进入目标工作空间。 2. 检查当前灰度升级计划,确保您的账号已包含最新版本。 3. 提交工单申请尽快升级至最新版本。
scan.incremental.snapshot.enabled=true),以提高全量阶段的并发读取能力。slot.name 参数,避免出现 replication slot is active for PID 报错。根据上述分析,您可以按照以下优先级逐步排查和解决问题: 1. 检查资源使用情况,确保 TaskManager 的 CPU 和内存充足。 2. 确认表结构变更策略,避免不兼容的修改。 3. 启用去重机制,处理重复事件。 4. 排查定时任务或外部依赖的影响。 5. 考虑升级到最新版本以获得更好的支持。
如果问题仍未解决,请提供具体的错误日志信息,以便进一步分析和定位问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
