
Flink 读取hologres 做窗口计算,怎么设置水位,有无java 代码?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Apache Flink中,当你使用Flink连接Hologres进行窗口计算时,水位线(Watermark)是用来处理事件时间(Event Time)数据中的延迟数据或者顺序问题的。Flink通过Watermark机制来保证数据的处理顺序,并且可以处理延迟到达的数据。
设置水位线的方法通常有两种:
自定义水位线生成器(Assigner):你可以实现AssignerWithPunctuatedWatermarks或AssignerWithPeriodicWatermarks接口来自定义水位线的生成策略。
使用Flink提供的预定义水位线策略:例如,使用AscendingTimestampExtractor或BoundedOutOfOrdernessTimestampExtractor。
以下是一个简单的Java代码示例,演示如何为Flink读取Hologres的数据并设置水位线:
在这个例子中,我们使用了Hologres连接器来定义数据源,并且在创建表的时候指定了水位线的策略。在窗口SQL查询中,我们使用了TUMBLE窗口分配函数和GROUP BY子句来对数
Flink 读取Hologres数据进行窗口计算时,如果使用的是Flink的实时消费模式(非批模式),8.0以下版本的Hologres CDC源表暂不支持直接定义Watermark。您可以采用非窗口聚合的方式实现类似的需求。对于Flink的Watermark设置,通常会在数据源定义时进行,例如:
在上述代码中,BoundedOutOfOrdernessTimestampExtractor用来设置水位线,Time.seconds(1)定义了最大延迟时间。请确保Hologres的事件时间戳字段与Flink中extractTimestamp方法对应。
在Apache Flink中进行窗口计算并设置水位线(Watermark)以处理乱序事件时,您需要遵循以下步骤和原则,特别是当您从Hologres读取数据并进行处理时。虽然提供的参考资料没有直接展示设置水位线的Java代码示例,但我将基于Flink的标准实践为您提供指导。
水位线的作用:水位线机制用于处理事件乱序到达的情况,它是一个不断递增的时间戳,表示到目前为止所有小于或等于该时间戳的事件都已到达Flink系统。这在窗口计算中至关重要,尤其是当窗口基于事件时间时。
如何设置水位线:在数据源处设置水位线,通常是通过自定义SourceFunction或利用支持水位线传递的数据源实现。对于Hologres,虽然它本身不直接产生水位线,但您可以通过Flink的数据流编程接口来配置。
在Flink中读取Hologres数据并进行窗口计算时,设置水位线(Watermark)是确保事件时间(Event Time)窗口准确性的关键。水位线用于标记数据流中的进度,告知Flink系统到目前为止哪些事件时间的数据应该已经全部到达。以下是使用Java代码设置水位线并进行窗口计算的基本示例:
首先,确保你的数据源支持生成水位线。如果你的数据源本身不直接提供水位线信息,你可能需要基于数据中的时间戳字段手动生成水位线。以下是一个简化的示例,展示了如何在读取Hologres数据后,对数据流应用水位线策略,并进行一个简单的滚动窗口聚合计算:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.jdbc.JdbcInputFormat;
import org.apache.flink.streaming.connectors.jdbc.JdbcOutputFormat;
import org.apache.flink.streaming.connectors.jdbc.JdbcConnectionOptions;
public class FlinkReadHologresWindowExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置Hologres连接参数
JdbcConnectionOptions jdbcOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:hologres://yourEndpoint:80/yourDatabaseName")
.withUsername("yourUserName")
.withPassword("yourPassword")
.build();
// 设置Hologres数据源
JdbcInputFormat jdbcInputFormat = JdbcInputFormat.buildJdbcInputFormat()
.setDrivername("org.postgresql.Driver")
.setDBUrl(jdbcOptions.getUrl())
.setUsername(jdbcOptions.getUsername())
.setPassword(jdbcOptions.getPassword())
.setQuery("SELECT a, b, timestamp_column FROM yourTableName") // 假设timestamp_column为你的时间戳字段
.setRowTypeInfo(new RowTypeInfo(Types.INT, Types.STRING, Types.SQL_TIMESTAMP)) // 根据实际表结构调整
.finish();
// 读取数据并分配时间戳及生成水位线
DataStream<Tuple2<Integer, String>> inputStream = env.createInput(jdbcInputFormat)
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<Integer, String>>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<Integer, String>>() {
@Override
public long extractTimestamp(Tuple2<Integer, String> element, long recordTimestamp) {
return element.f2.getTime(); // 假设timestamp_column是第三个字段,转换为毫秒时间戳
}
}));
// 应用窗口计算,例如基于事件时间的滚动窗口,窗口大小为1分钟
DataStream<Tuple2<String, Integer>> result = inputStream
.keyBy(0) // 假设按第一个字段分组
.window(Time.minutes(1))
.sum(1); // 对第二个字段求和
// 输出结果到控制台或其他sink
result.print();
env.execute("Flink Read Hologres Window Calculation");
}
}
这段代码演示了如何:
JdbcInputFormat从Hologres读取数据。timestamp_column是数据中的时间戳字段,并允许最多5秒的数据乱序。请注意,实际应用中需要根据你的具体需求调整表结构、字段类型、时间戳字段以及窗口大小等参数。

Flink实时消费Hologres作为源表时,8.0以下版本的Hologres CDC模式暂不支持定义Watermark。您可以采用非窗口聚合的方式来处理。若需要使用窗口功能,建议参考实时计算Flink版实时消费Hologres文档,升级到支持Watermark的Flink版本。对于Java代码示例,通常会涉及到Flink的SourceFunction或SourceConnector的自定义,这需要结合具体的业务逻辑来编写
水位线(watermark)是确保事件时间(event time)处理语义的关键。水位线用于处理乱序事件,它是一个不断递增的时间戳,表示到目前为止可能已经处理了所有小于该时间戳的事件
所以需要在java设置的话,这样来
在Flink的数据流(DataStream)中,通常在定义数据源之后立即设置水位线生成器(WatermarkStrategy)。这有助于Flink基于事件时间进行窗口聚合等操作。
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 初始化Flink执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 假设你已经通过Catalog读取到了Hologres表的数据流,这里简化为一个示例数据流
DataStream inputStream = ...; // 从Hologres Catalog读取数据的逻辑
// 设置水位线策略,例如允许最大延迟时间为5秒
WatermarkStrategy watermarkStrategy = WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(YourEventClass element, long recordTimestamp) {
// 根据你的事件类定义如何提取时间戳
return element.getEventTime(); // 假设YourEventClass有一个getEventTime方法返回事件时间戳
}
});
// 应用水位线策略到数据流
DataStream dataStreamWithWatermarks = inputStream.assignTimestampsAndWatermarks(watermarkStrategy);
// 接下来,你可以在这个dataStreamWithWatermarks上应用窗
进行窗口计算
应用水位线后,你可以在数据流上定义窗口操作来进行聚合计算。例如,使用keyBy进行分组,然后应用timeWindow进行滚动窗口计算:
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
DataStream result = dataStreamWithWatermarks
.keyBy(event -> event.getKey()) // 基于某个键进行分组
.timeWindow(Time.seconds(10)) // 定义一个10秒的滚动窗口
.process(new YourProcessWindowFunction()); // 自定义窗口处理函数
// 实现自定义窗口处理函数
public static class YourProcessWindowFunction extends ProcessWindowFunction {
@Override
public void process(KeyType key, Context context, Iterable elements, Collector out) throws Exception {
// 在此方法内实现你的窗口内聚合逻辑
}
然后就可以了
完美的水位线是“绝对正确”的,也就是一个水位线一旦出现,就表示这个时间之前的数据已经全部到齐、之后再也不会出现了。不过如果要保证绝对正确,就必须等足够长的时间,这会带来更高的延迟。
如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下,可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。当然,如果我们对准确性完全不考虑、一味地追求处理速度,可以直接使用处理时间语义,这在理论上可以得到最低的延迟。
所以Flink中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。
public class WatermarkOutOfOrdermessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("localhost", 7777)
.map(new WaterSensorMapFunction());
//todo 定制水位线策略
WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy
*******
forMonotonousTimestamps() //有序流
forBoundedOutOfOrderness(等待时间) //乱序流
*******
.<WaterSensor>forMonotonousTimestamps()
//指定时间戳分配器
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor waterSensor, long l) {
System.out.println("数据=" + waterSensor + ",recordTS=" + l);
return waterSensor.getTs() * 1000L;
}
});
SingleOutputStreamOperator<WaterSensor> sensorWithWaterMark = sensorDS
.assignTimestampsAndWatermarks(watermarkStrategy);
sensorWithWaterMark
.keyBy(value -> value.getId())
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(
new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<WaterSensor> iterable, Collector<String> collector) throws Exception {
//使用上下文获取窗口信息
long start = context.window().getStart(); //获取窗口开始时间
long end = context.window().getEnd(); //获取窗口结束时间
String windowStart = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long amount = iterable.spliterator().estimateSize();//获取数据条数
collector.collect("key="+s+"的窗口["+windowStart+"-"+windowEnd+")包含"
+amount+"条数据==>"+iterable.toString());
}
}
).print();
env.execute();
}
}
备注:使用水位线要求窗口为事件窗口,不能使用时间窗口。
——参考链接。
在 Apache Flink 中,水位(watermark)是处理乱序事件流时非常重要的一个概念,用于确定事件时间窗口的结束点。在使用 Flink 读取 Hologres(一种兼容 PostgreSQL 的实时分析数据库)进行窗口计算时,首先需要确保 Flink 作业能够处理来自 Hologres 的数据流,并且正确设置时间属性和水位。
然而,需要注意的是,Flink 通常不直接从数据库(如 Hologres)中读取数据流,而是通过例如 Flink CDC (Change Data Capture) 连接器、JDBC Source 或自定义 Source Connector 来读取数据。这里我们假设你已经有了一个从 Hologres 读取数据的 Flink Source。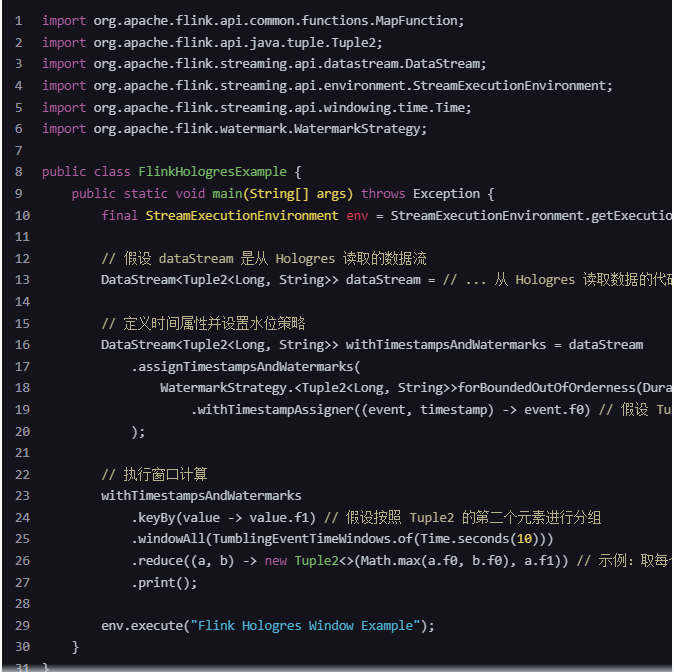
Flink 在处理有界和无界数据流时,使用“水位线”(Watermarks)来处理事件时间和窗口计算。在 Flink 中,水位线是一种机制,用于跟踪事件时间的进度,这对于基于时间的窗口操作至关重要。当从 Hologres(阿里云的数据仓库服务)读取数据时,你可能需要基于事件时间进行窗口聚合。Hologres 本身并不直接生成水位线,但 Flink 可以根据接收到的数据中的时间戳推断水位线。以下是一个简单的 Java 代码示例,展示了如何在 Flink DataStream API 中配置水位线策略: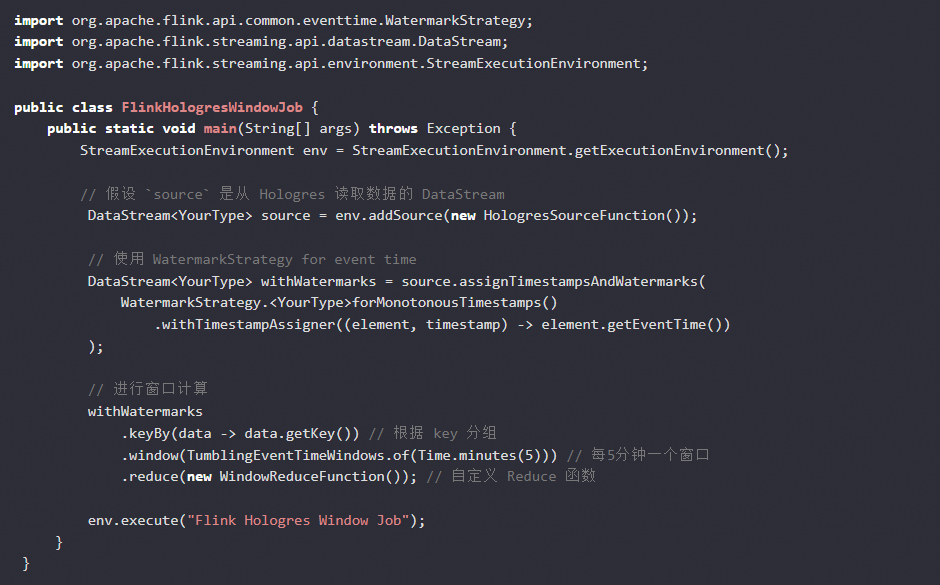
在这个例子中,我们使用了单调递增的时间戳策略 forMonotonousTimestamps(),这通常适用于没有乱序事件的情况。如果你的数据有可能出现乱序,那么你可能需要使用更复杂的策略,例如 forBoundedOutOfOrderness(Duration zeroLateness)。你需要替换 YourType、HologresSourceFunction 和 WindowReduceFunction 为实际的类型和函数实现。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


