
大数据计算MaxCompute数据库能连上为什么报这个错误?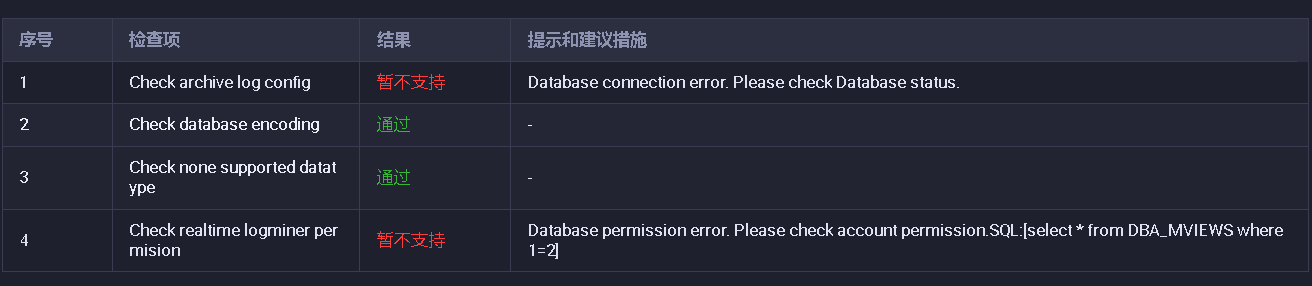
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的错误信息和知识库中的参考资料,以下是可能导致MaxCompute数据库连接成功但仍报错的原因及解决方法:
即使能够连接到MaxCompute项目,如果用户没有足够的权限访问特定表或执行某些操作,仍可能报错。例如: - 报错信息:get odps table error: can not load table schema.
- 可能原因: - 用户未被授予对目标表的describe和select权限。 - 如果MaxCompute项目开启了保护模式(set projectProtection=true),数据无法导出。 - 解决方法: 1. 确保用户已被授予对目标表的describe和select权限。可以通过以下命令授予权限: sql grant Describe, Select on table <table_name> to user <user_name>; 2. 检查是否启用了项目保护模式。如果启用,需在MaxCompute控制台中关闭该设置。
虽然连接成功,但如果Endpoint配置不正确,可能会导致后续操作失败。 - 报错信息:Test connection fail: connect timed out, the possible reason is that the endpoint '<endpoint>' is wrong.
- 可能原因: - 使用了错误的Endpoint(例如,外网环境使用了内网Endpoint)。 - 将Tunnel Endpoint误填为普通Endpoint。 - 解决方法: 1. 根据项目所属区域和网络环境,选择正确的Endpoint。参考Endpoint文档,确保配置的Endpoint与实际环境匹配。 2. 确保Tunnel服务和普通服务的Endpoint分开配置,避免混淆。
如果启用了查询加速功能但未正确配置,可能会导致查询失败。 - 可能原因: - 查询加速功能开关未正确设置。 - 解决方法: 1. 在连接URL后追加&interactiveMode=true以启用查询加速功能。 2. 确保查询加速功能已正确配置,并检查相关权限。
即使连接成功,任务可能因本地环境问题而中断。 - 报错信息:执行完成后结果表为空。
- 可能原因: - 任务在本地执行时,用户锁屏导致任务中断。 - 解决方法: 1. 避免在任务执行过程中锁屏。 2. 如果使用DataWorks,建议通过其界面提交任务,确保任务完整执行。
如果目标表是分区表,但指定的分区不存在,可能会导致报错。 - 报错信息:ErrorCode=NoSuchPartition, ErrorMessage=The specified partition does not exist.
- 解决方法: 1. 使用以下命令检查分区是否存在: sql show partitions <table_name>; 2. 如果分区不存在,创建对应的分区: sql alter table <table_name> add [if not exists] partition <partition_spec>;
如果外部表字段与源表字段不匹配,可能会导致报错。 - 报错信息:Column Mismatch
- 可能原因: - 数据源文件的行分隔符有问题,导致多条记录被当成一条记录。 - 解决方法: 1. 检查数据源文件的行分隔符设置,重新设置-rd参数。 2. 如果需要映射部分列,确保colmapping参数正确配置。例如: sql 'x: "map_B"'
You don't exist in project <project_name>.请根据具体的报错信息逐一排查上述问题。如果问题仍未解决,请联系阿里云售后技术支持,提供详细的报错日志以便进一步分析。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

