
Flink这个问题怎么解决?
Flink这个问题怎么解决?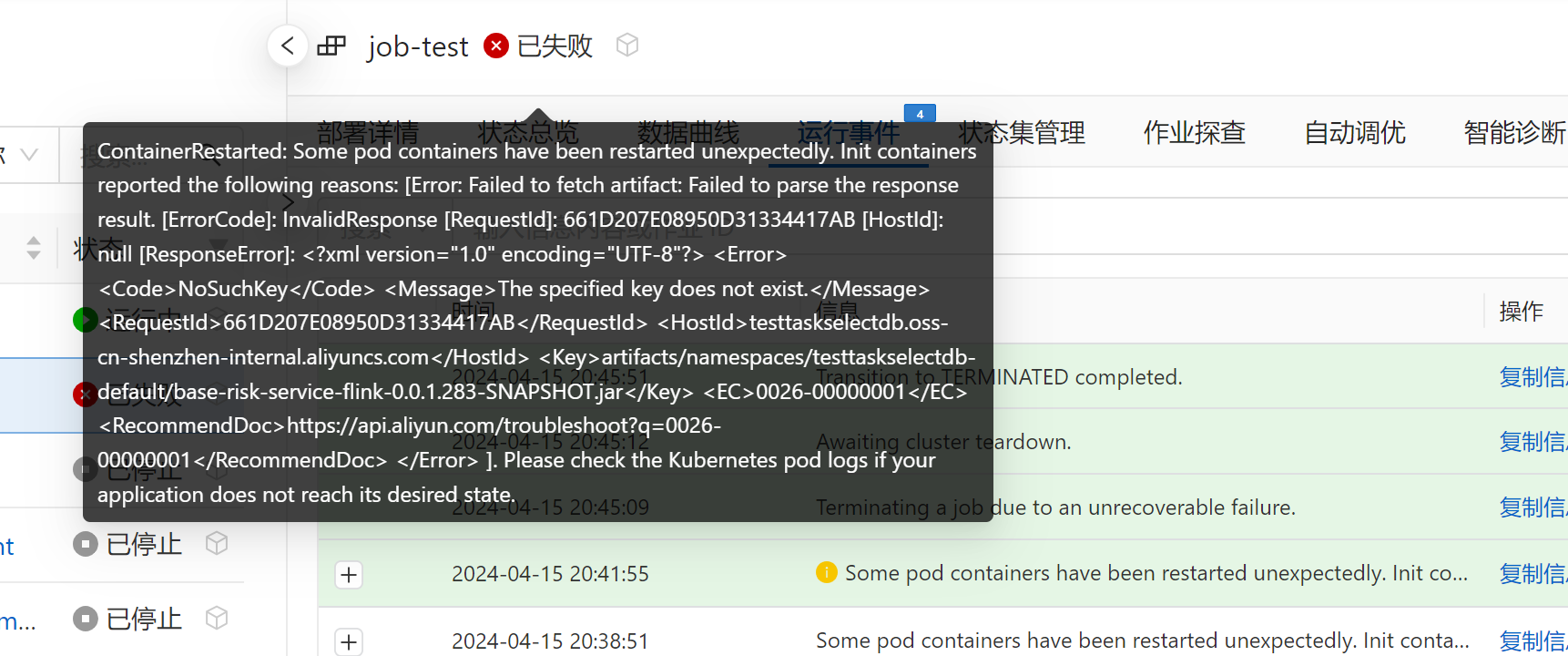
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要解决Flink相关问题,首先需要明确具体的问题场景和错误信息。根据您提供的知识库资料,我将针对一些常见的Flink问题提供详细的解决方案。如果您遇到的具体问题未包含在以下内容中,请进一步补充问题描述。
1. Flink依赖冲突问题
如果您的Flink作业出现依赖冲突问题,可以按照以下步骤解决:
解决方案:
-
核心依赖设置为
provided
对于Flink、Hadoop和log4j等核心依赖,建议将其scope设置为provided,以避免与运行时环境的依赖冲突。例如:<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> -
Connector依赖设置为
compile
对于作业所需的Connector(如Kafka Connector),需要将其scope设置为compile,以确保这些依赖被打包到作业JAR中:<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>${flink.version}</version> </dependency> -
排除间接依赖
如果作业存在间接依赖冲突,可以通过exclusion移除不必要的依赖。例如:<dependency> <groupId>foo</groupId> <artifactId>bar</artifactId> <exclusions> <exclusion> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> </exclusion> </exclusions> </dependency>
2. Flink与Kafka网络连通性问题
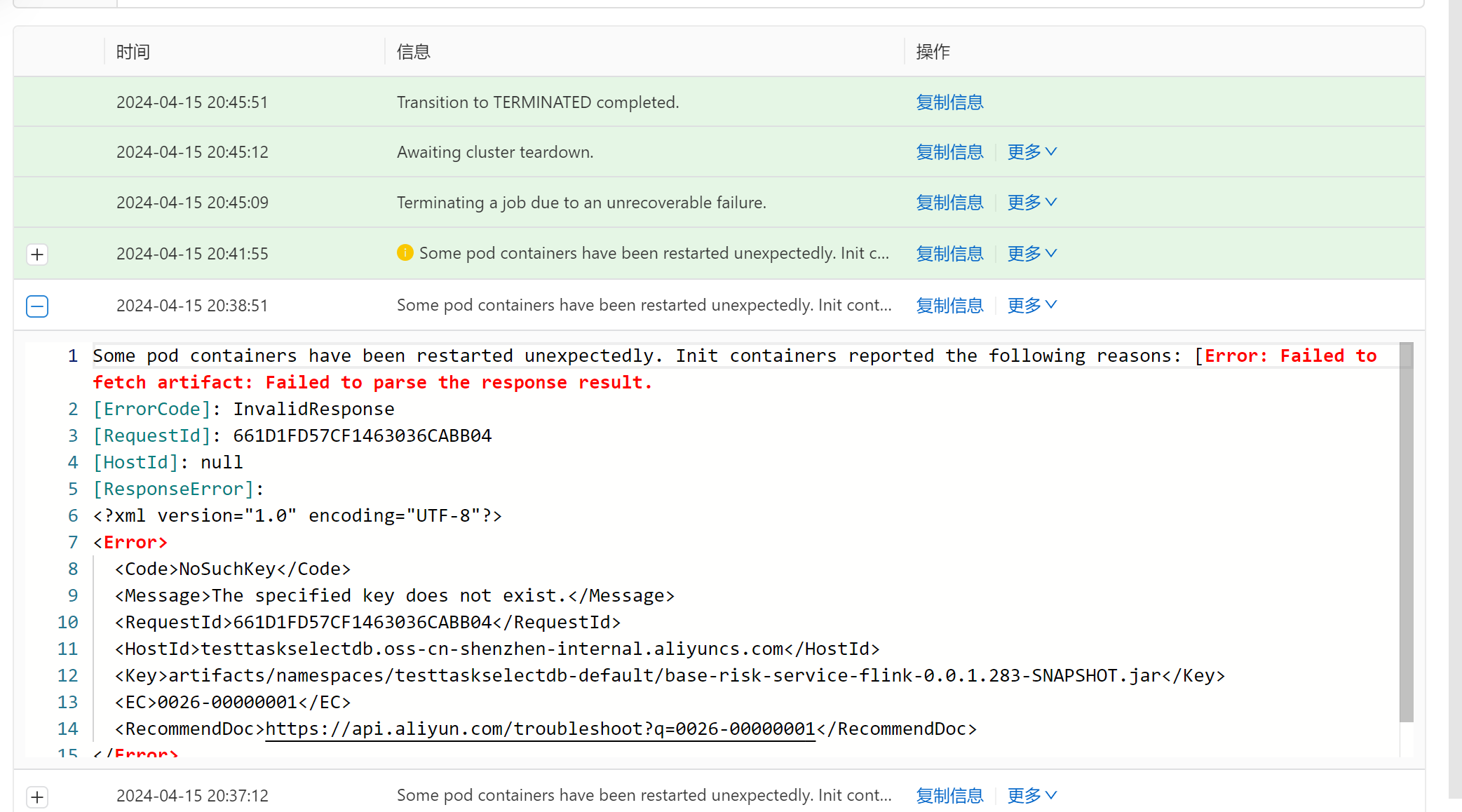
如果Flink与Kafka之间的网络连通性出现问题,即使网络是通的,仍可能出现timeout expired while fetching topic metadata的错误。
解决方案:
-
检查网络连通性
在Flink控制台使用网络探测功能,测试Flink作业与Kafka服务之间的连通性。确保输入的Endpoint或IP地址正确,并填写对应的端口号。 -
调整连接超时参数
如果网络延迟较高,可以在DDL的WITH参数中增加connect.timeout的值(默认为30秒)。例如:'connect.timeout' = '60s' -
跨VPC或公网访问配置
- 如果Kafka服务位于不同的VPC,需配置跨VPC访问。详情请参考如何访问跨VPC的其他服务。
- 如果Kafka服务通过公网访问,需使用NAT网关实现VPC与公网的连通。
-
域名解析问题
如果Kafka服务使用域名访问,确保Flink作业能够正确解析域名。可以通过自建DNS或阿里云PrivateZone进行域名解析配置。
3. Flink作业数据写入Kafka延迟问题
如果Flink作业写入Kafka的数据存在延迟,可能与EXACTLY_ONCE语义的事务机制有关。
解决方案:
-
理解延迟来源
- 在
EXACTLY_ONCE模式下,Flink Kafka Producer会使用事务写入Kafka。未完成的事务会阻塞Consumer读取数据,直到事务提交或中止。 - 数据延迟通常约为Checkpoint的平均间隔时间。
- 在
-
优化Checkpoint配置
- 调整Checkpoint间隔时间,减少事务未完成的时间窗口。例如:
execution.checkpointing.interval: 1min - 确保Producer池大小和最大并发Checkpoint数量匹配,避免因资源不足导致作业失败。
- 调整Checkpoint间隔时间,减少事务未完成的时间窗口。例如:
-
处理作业失败情况
- 如果Flink作业在第一个Checkpoint之前失败,重启后不会保留Producer池信息。因此,在第一个Checkpoint完成前,不建议缩减并行度。
4. Flink作业数据正确性问题
如果Flink作业产出结果不符合预期,可以使用算子探查功能排查数据正确性问题。
解决方案:
-
启用算子探查
- 登录实时计算控制台,进入目标作业的运维页面。
- 打开算子探查开关,选择需要探查的算子,并设置采样时间(1~30分钟)。
-
查看探查结果
- 探查过程中,可以在日志页面查看
inspect-taskmanager_0.out的日志,分析算子的输入输出数据。
- 探查过程中,可以在日志页面查看
-
停止探查
- 探查会在达到最大存储上限、采样时间结束或手动停止时终止。
5. 字段命名冲突问题
如果Flink表中存在字段命名冲突(如键和值字段同名),可以通过key.fields-prefix属性解决。
解决方案:
- 在创建Flink表时,为键字段添加前缀。例如:
CREATE TABLE kafka_table ( key_id INT, value_id INT, name STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'test_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json', 'key.format' = 'json', 'key.fields' = 'id', 'value.format' = 'json', 'value.fields' = 'id, name', 'key.fields-prefix' = 'key_' ); - 查询结果中,键字段会被命名为
key_id,与值字段value_id区分开。
6. 作业性能问题
如果Flink作业性能较低,可能存在反压或函数使用不当的问题。
解决方案:
-
优化内置函数使用
- 避免使用正则表达式(如
REGEXP),改用LIKE操作符。 - 注意
LIKE操作中的特殊字符(如下划线_)需要转义。例如:LIKE '%seller/_id%' ESCAPE '/'
- 避免使用正则表达式(如
-
解决反压问题
- 增加下游节点的并发数。
- 开启
minibatch等聚合优化参数。
-
分析线程性能
- 使用火焰图分析线程CPU占用情况,重点关注
RMI TCP Connection线程的性能表现。
- 使用火焰图分析线程CPU占用情况,重点关注
以上是针对常见Flink问题的详细解决方案。如果您遇到的具体问题未涵盖在上述内容中,请提供更详细的错误信息或场景描述,以便进一步协助解决。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。