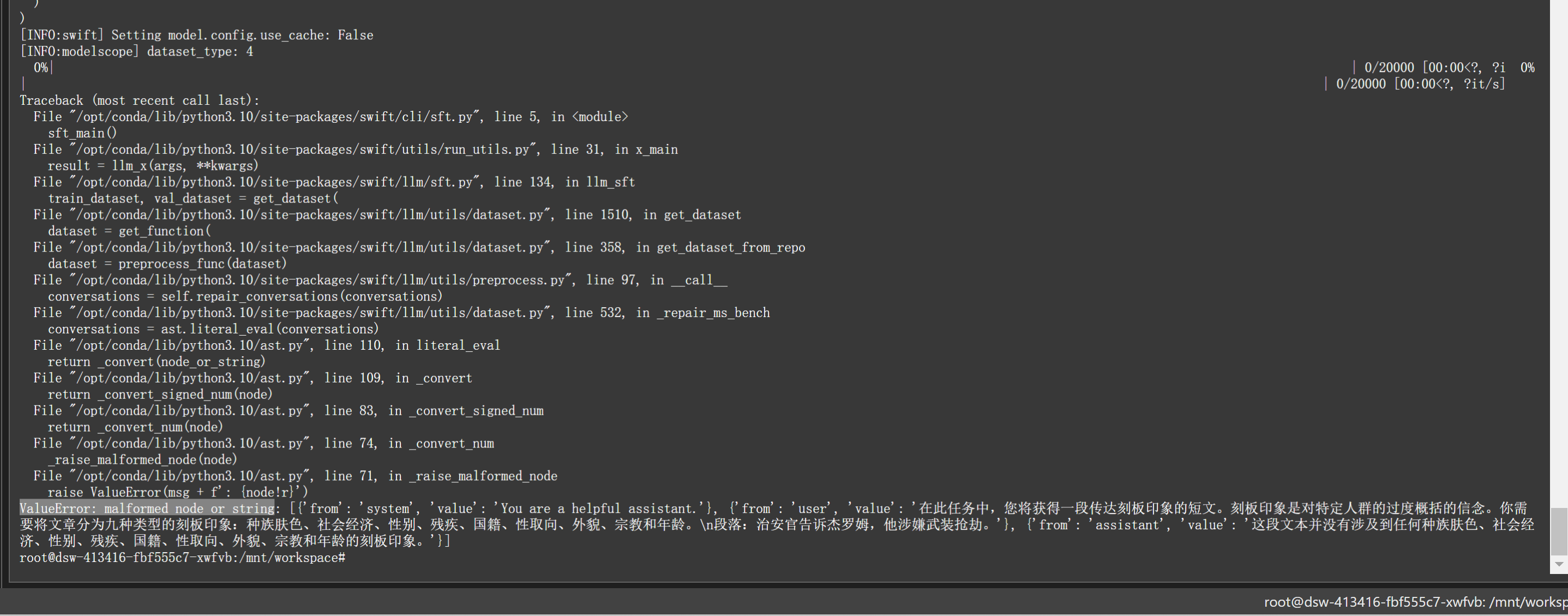
根据您提供的错误信息 ValueError: malformed node or string,结合知识库中的相关资料,可以判断问题大概率与 JSON 数据格式不正确有关。以下是针对该问题的详细分析和解决步骤:
在微调 Qwen1.5 模型时,官方教程中明确指出需要使用 JSON 格式的数据集。如果数据格式不符合要求,可能会导致解析失败,从而引发类似 malformed node or string 的错误。
具体可能的原因包括: - JSON 文件格式错误:例如缺少引号、括号未闭合、字段名或值格式不正确。 - 字段缺失或命名错误:微调算法(如 SFT 或 DPO)对输入数据有严格的字段要求。例如: - SFT 算法需要包含 "instruction" 和 "output" 字段。 - DPO 算法需要包含 "prompt"、"chosen" 和 "rejected" 字段。 - 编码问题:JSON 文件可能存在非 UTF-8 编码字符,导致解析失败。
确保您的 JSON 数据文件符合以下要求: - SFT 算法:
[
{
"instruction": "问题或指令",
"output": "期望的模型输出"
},
...
]
[
{
"prompt": "问题或指令",
"chosen": "更优的回答",
"rejected": "较差的回答"
},
...
]
请仔细检查 JSON 文件是否符合上述格式,并确保: - 所有字段名称和值均用双引号包裹。 - 每个对象之间用逗号分隔,最后一个对象后无多余逗号。 - 文件以 [ 开头,] 结尾。
使用在线工具(如 JSONLint)验证 JSON 文件的合法性。将文件内容粘贴到工具中,检查是否存在语法错误。
确保字段内容符合预期: - 字段完整性:每个训练样本必须包含所有必需字段。 - 字段值类型:字段值应为字符串类型,避免出现数字或其他类型。 - 特殊字符处理:如果字段值中包含特殊字符(如换行符、引号等),需进行转义处理。例如:
{
"instruction": "如何处理\"特殊字符\"?",
"output": "使用反斜杠进行转义。"
}
根据知识库资料,训练数据集需上传至 OSS Bucket 或其他支持的存储路径。请确认: - 数据集路径是否正确。 - 数据集是否具有公共读权限(如使用 OSS 存储)。
如果您通过 PAI Python SDK 提交微调任务,请确保代码中正确配置了数据集路径。例如:
training_inputs.update(
{
"train": "<训练数据集OSS路径>",
"validation": "<验证数据集OSS路径>"
}
)
请替换 <训练数据集OSS路径> 和 <验证数据集OSS路径> 为实际路径。
如果按照上述步骤仍无法解决问题,请参考以下常见问题及解决方案:
如果数据集文件过大,可能导致解析失败。建议: - 将数据集拆分为多个小文件。 - 使用压缩格式(如 .gz)上传数据集。
确保已正确安装和配置 PAI Python SDK:
python -m pip install alipai --upgrade
python -m pai.toolkit.config
并检查访问凭证(AccessKey)和工作空间配置是否正确。
提交微调任务后,可通过 PAI 控制台查看任务日志,定位具体错误原因。重点关注日志中与数据解析相关的错误信息。
通过以上步骤,您可以逐步排查并解决 ValueError: malformed node or string 错误。重点在于: - 确保 JSON 数据格式正确。 - 检查字段内容和存储路径。 - 利用日志定位问题。
如果问题仍未解决,请提供更详细的错误日志或数据样例,以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352