
当我在下载youku-mplug数据集的时候我遇到问题
使用原作者的代码: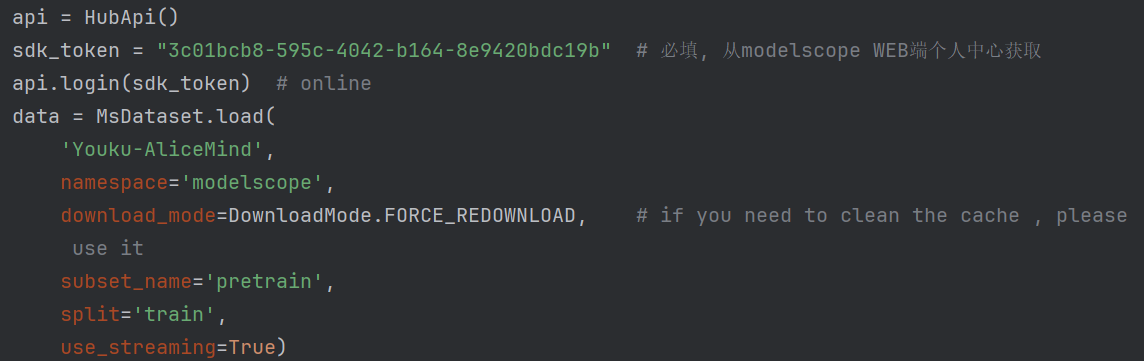
会发生这样的报错UnicodeEncodeError: 'gbk' codec can't encode character '\U0001f604'请问该如何下载,并且我想分批次下载,因为电脑的空间没有那么多
根据您提供的报错信息 UnicodeEncodeError: 'gbk' codec can't encode character '\U0001f604',以及分批次下载的需求,以下是详细的解决方案:
1. 报错原因分析
该错误表明代码在尝试将包含特殊字符(如表情符号 \U0001f604)的字符串写入文件时,使用了 gbk 编码,而 gbk 编码无法处理这些特殊字符。
解决方向: - 确保数据在写入文件时使用支持更广泛字符集的编码格式(如 utf-8)。 - 如果数据来源是 MaxCompute 表或其他存储服务,需确保数据本身符合 UTF-8 编码。
2. 解决方案
2.1 修改代码以支持 UTF-8 编码
在 Python 中,可以通过以下方式修改代码,确保写入文件时使用 UTF-8 编码:
# 示例代码:将数据写入文件时指定 UTF-8 编码
with open('output_file.txt', 'w', encoding='utf-8') as f:
f.write(data)
如果数据来源于 MaxCompute 表,请确保表中的字符串字段为 UTF-8 编码。如果存在非 UTF-8 数据,可以使用 is_encoding 函数过滤掉不符合要求的数据:
SELECT py_udf(input_col)
FROM example_table
WHERE is_encoding(input_col, 'utf-8', 'utf-8') = true;
2.2 分批次下载数据
由于您的电脑空间有限,建议采用分批次下载的方式。以下是具体步骤:
2.2.1 使用 MaxCompute Tunnel 分批次导出数据
MaxCompute 提供了 Tunnel 功能,支持分批次导出数据。以下是操作步骤: 1. 创建 Upload/Download Session
使用 MaxCompute Tunnel 创建一个 Download Session,并指定需要下载的分区或范围。
tunnel download -fd "start_offset,count" project_name.table_name output_file
start_offset:起始偏移量,必须大于等于 0。-
count:下载的行数,必须大于 0。 -
分批次导出数据
根据数据总量和可用磁盘空间,合理设置每次下载的行数。例如:
# 第一批次:下载前 10000 行
tunnel download -fd "0,10000" project_name.table_name batch1.txt
# 第二批次:下载第 10001 到 20000 行
tunnel download -fd "10000,10000" project_name.table_name batch2.txt
- 合并小文件(可选)
如果下载后生成了大量小文件,可以通过 MaxCompute 的INSERT INTO或MERGE操作合并小文件。
2.3 避免编码问题的其他措施
- 检查数据源编码:如果数据源中存在非 UTF-8 编码的字符串,建议在写入 MaxCompute 表之前将其转换为 UTF-8 编码。例如:
ret.decode('gbk').encode('utf-8') - 修改函数签名:如果调用的是 Python 3 UDF,可以将输入参数类型从
STRING修改为BINARY,并在 SQL 中将列转换为BINARY类型:SELECT py_udf(CAST(input_col AS BINARY)) FROM example_table;
3. 注意事项
- 确保磁盘空间充足:在分批次下载时,请提前计算每批次数据的大小,避免因磁盘空间不足导致下载失败。
- 检查网络连接:如果下载过程中出现网络中断,Tunnel Session 可能会失效。超过 24 小时未完成的 Session 会被自动关闭,需重新创建。
- 验证数据完整性:下载完成后,建议对数据进行校验,确保没有丢失或损坏。
通过以上方法,您可以有效解决 UnicodeEncodeError 报错问题,并实现分批次下载数据的需求。如果仍有疑问,请提供更多上下文信息以便进一步协助!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352