热门
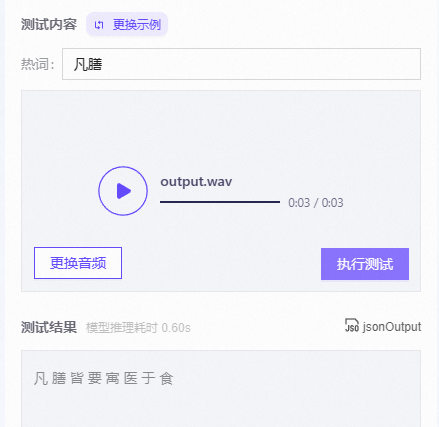
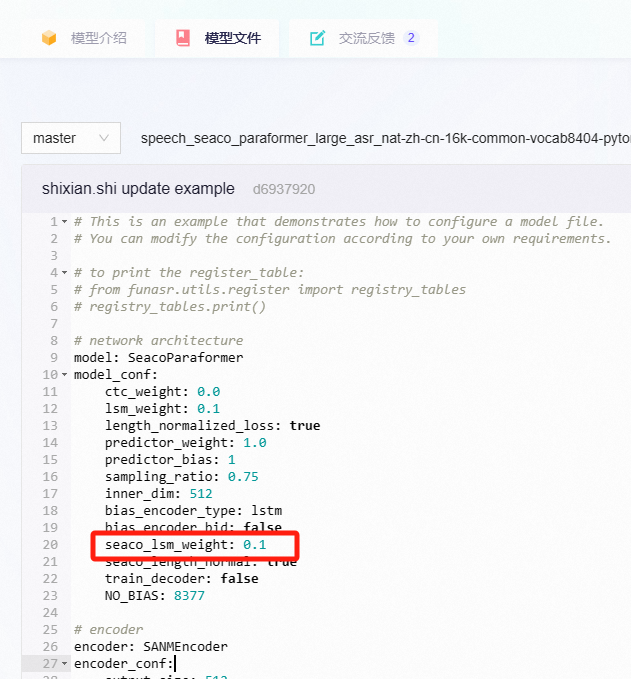
modelscope-funasr中, iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch模型,热词的长度和个数都影响结果的正确性,请问有没有办法提高热词的重呢,会不会是这个值呢?
不是哈,这个是训练过程中的热词loss label smoothing,不影响推理的。热词模型的召回率也不是百分之百,可以尝试拆开热词之类的多试一试。此回答整理自钉群“modelscope-funasr社区交流”
包含命名实体识别、文本分类、分词、关系抽取、问答、推理、文本摘要、情感分析、机器翻译等多个领域