
PolarDB这个问题怎么处理?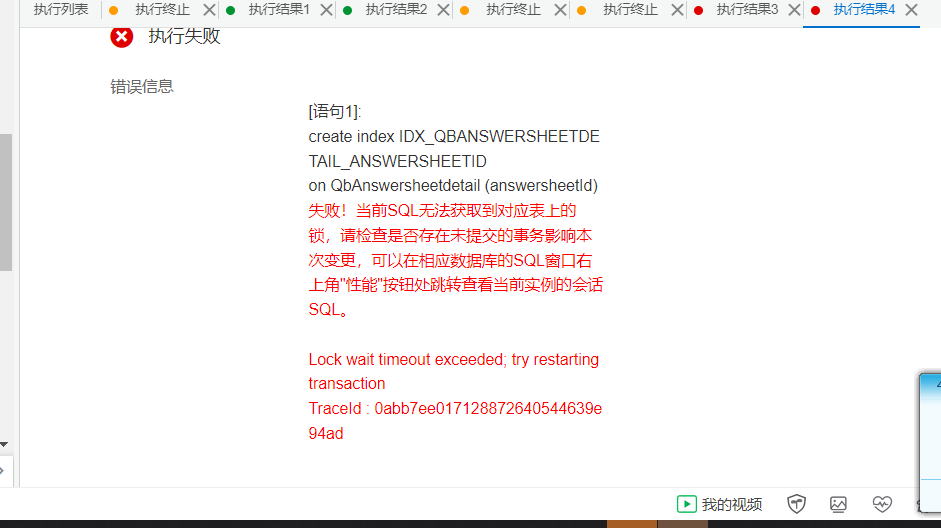
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您的问题提到“PolarDB这个问题”,但未具体说明是哪一类问题或具体的错误场景。根据知识库中的参考资料,我将针对PolarDB常见问题的处理方式进行分类总结,并提供详细的解决方法。您可以根据实际问题场景选择对应的解决方案。
如果在DMS中执行SQL时出现锁等待超时的报错,可能是由于未提交的事务阻塞了当前会话。
解决方法:
- 重新登录DMS控制台,新建连接会话,再次执行SQL命令。 - 检查是否有长时间未提交的事务,及时提交或回滚事务以释放锁资源。
删除数据库后,仍然占用较多空间的原因是Redo日志文件占用了存储空间(通常为2 GB~11 GB)。
解决方法:
- 缓冲池内的Redo日志文件数量由参数loose_innodb_polar_log_file_max_reuse控制,默认值为8。可以通过调整该参数减少日志空间占用量,但需要注意,在高压力情况下,性能可能会出现周期性的小幅波动。
当只读节点负载过高或复制延迟增高时,可能会少量增加主节点的内存消耗。
解决方法:
- 监控只读节点的负载情况,优化查询语句以降低负载。 - 如果复制延迟较高,检查是否存在大事务或网络延迟问题,并进行优化。
开启Binlog不会影响查询(SELECT)性能,但会对写入更新(INSERT、UPDATE、DELETE)性能产生一定影响。
影响范围:
- 在读写均衡的数据库中,开启Binlog后对性能的影响通常不超过10%。
如果使用并行查询后性能提升不明显,可能的原因包括以下几点:
- 查询的数据量较少,无法拆分为足够的子任务。 - 部分算子无法下推到worker线程执行,导致单线程瓶颈。 - 集群资源负载不稳定,导致并行查询被限制回退为串行执行。
解决方法:
- 使用EXPLAIN查看执行计划,确认是否使用了并行查询(如Parallel scan字段)。 - 调整并行度参数,建议初始值设置为集群CPU核数的1/4。例如,16核规格的集群,初始并行度可设置为4。 - 确保查询能够命中同一个索引,避免因索引不同导致查询结果不稳定。
原因可能是统计信息不准确。
解决方法:
- 升级到PolarDB MySQL版8.0.2版本,该版本已针对分区级别统计信息进行了优化。
目前仅支持库表级的恢复,不支持分区级的数据恢复。
预防措施:
- 定期备份数据,避免误操作导致数据丢失。
原因可能是分区表上存在大事务。
解决方法:
- 升级到PolarDB MySQL版8.0.2版本,该版本支持分区粒度的MDL锁,只会阻塞正在添加分区的DML操作,最大限度减少对业务的影响。
如果PolarDB数据库连接数异常,可能是由于空闲连接未及时释放或异常用户连接过多。
解决方法:
- 执行SHOW PROCESSLIST命令查看活跃会话,定位异常用户。 - 使用ALTER USER xxx@'%' WITH MAX_USER_CONNCTIONS 4;命令限制异常用户的连接数。 - 调整wait_timeout和interactive_timeout参数值,加速空闲连接的释放。
原因可能是存在大事务或频繁的I/O操作。
解决方法:
- 检查是否存在大事务,并优化相关SQL语句。 - 使用性能洞察功能评估数据库负载情况,找出导致IOPS高的根本原因。
如果直接在RDS中写入的数据主键值不是PolarDB生成的Sequence值,可能会导致主键冲突。
解决方法:
1. 使用SHOW SEQUENCES;命令查看现有Sequence。 2. 获取表的最大主键值,例如:SELECT MAX(id) FROM xkv_t_item;。 3. 更新Sequence值,使其大于已存在的最大主键值。例如:ALTER SEQUENCE AUTO_SEQ_xkv_t_item START WITH 9000;。
PolarDB外网连接的带宽上限为10 Gbit/s。如果需要更高的带宽,请考虑使用内网连接或升级集群配置。
如果您遇到的具体问题不在上述范围内,请进一步描述问题场景或错误信息,我将为您提供更精确的解答。
阿里云关系型数据库主要有以下几种:RDS MySQL版、RDS PostgreSQL 版、RDS SQL Server 版、PolarDB MySQL版、PolarDB PostgreSQL 版、PolarDB分布式版 。

