
flink tidbcdc 报这个错为啥?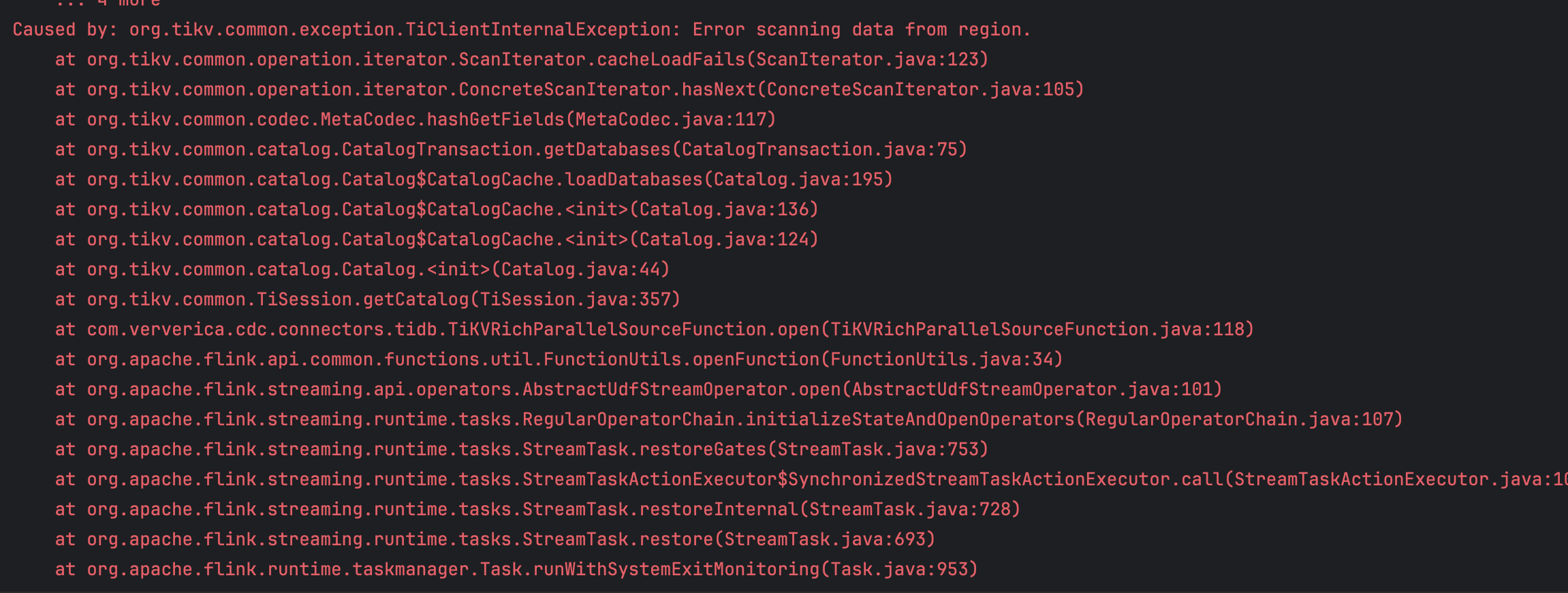
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的错误信息和知识库中的相关资料,以下是可能导致 Flink 使用 TiDB CDC 时出现报错的原因及解决方案:
Flink 在使用 TiDB CDC 时,可能会因为以下原因导致作业异常: - Task 退出超时:如果作业在 Failover 或退出过程中,某些 Task 长时间未完成退出操作,Flink 会触发 Task did not exit gracefully within 180 + seconds 的报错。这通常是因为自定义函数(如 close 方法)中存在阻塞逻辑,或者计算方法长时间未返回结果。 - Checkpoint 失败:如果 Checkpoint 过程中频繁失败,可能会导致作业触发 Failover。例如,Kafka Sink 的 Checkpoint 超时或失败次数超过容忍阈值,会引发类似 Too many ongoing snapshots 或 Exceeded checkpoint tolerable failure threshold 的报错。 - 网络连通性问题:如果 Flink 和 TiDB CDC 之间的网络延迟较高,或者域名解析失败,可能会导致作业运行异常。例如,UnknownHostException 或 JobManager heartbeat timeout 等报错。 - 磁盘空间不足:如果 TaskManager 的本地磁盘空间耗尽,可能会导致 No space left on device 的报错。
针对上述可能的原因,您可以按照以下步骤逐一排查并解决问题:
close 方法中是否存在阻塞逻辑。task.cancellation.timeout 参数设置为 0,以避免超时中断。
task.cancellation.timeout: 0
task.cancellation.timeout 参数仅用于调试,请勿在生产环境中长期使用该配置。Cancelling 状态的 Task 栈信息,定位具体问题根因。execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 3
JobManager heartbeat timeout 报错,可以在作业中关闭对 TaskManager 的域名解析:
jobmanager.retrieve-taskmanager-hostname: false
No space left on device 的报错。通过以上步骤,您可以逐步排查并解决 Flink 使用 TiDB CDC 时的报错问题。如果问题仍未解决,请提供更详细的报错日志,以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
