
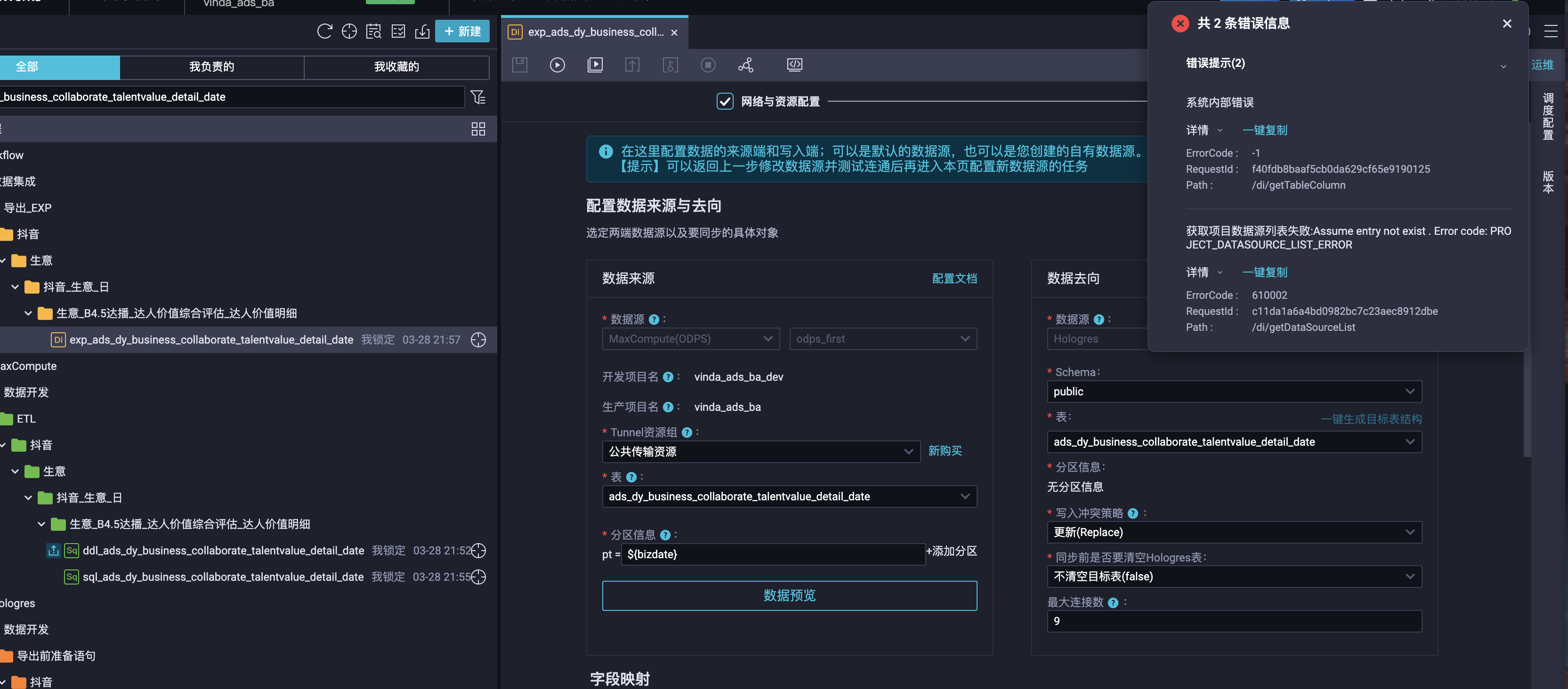
dataworks报错 麻烦看一下?
dataworks报错 麻烦看一下?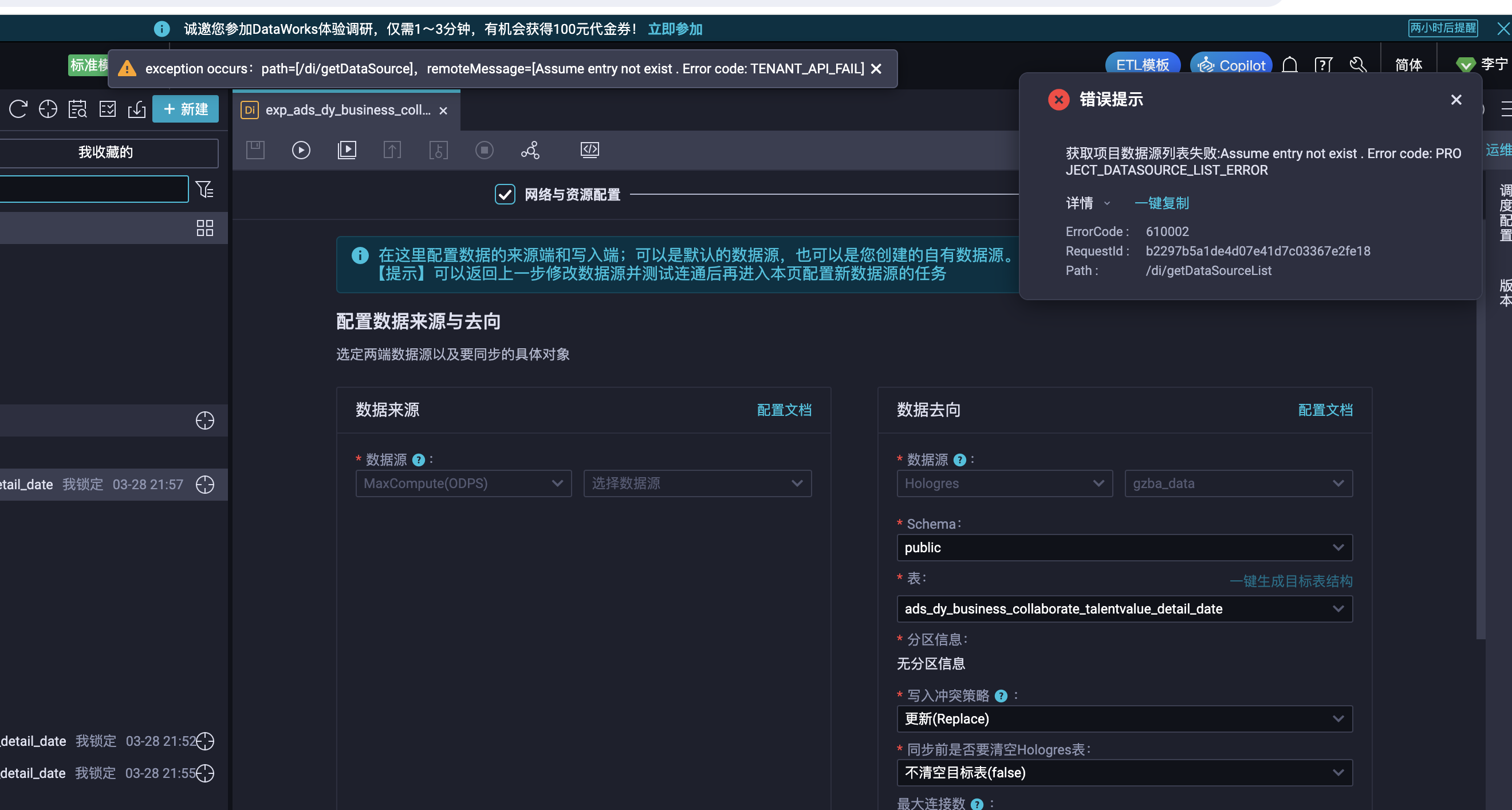
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的报错信息“dataworks报错”,结合知识库中的相关资料,以下是可能的原因及解决方案,请根据实际情况进行排查和处理:
1. 运行超时报错
如果报错内容类似于MongoDBReader$Task - operation exceeded time limit,可能是由于数据同步任务运行时间过长导致的。
可能原因:
- 数据量过大,全量拉取耗时较长。
- 前置语句(如
preSql)或后置语句(如postSql)执行时间过长。 - 未合理配置切分键(
splitPk),导致任务运行缓慢。
解决方案:
- 加大并发:增加任务的并发数以提高效率。
- 减小BatchSize:调整批量处理的数据量大小。
- 增加
cursorTimeoutInMs配置:在Reader端参数中添加cursorTimeoutInMs,例如设置为3600000ms。 - 优化SQL语句:确保前置或后置语句使用了索引字段进行过滤。
- 合理配置切分键:
- 推荐使用表主键作为切分键,因为主键通常分布均匀。
- 切分键仅支持整型数据,不支持字符串、浮点和日期类型。
- 如果未配置切分键,任务将使用单通道同步。
2. 资源不足导致的任务等待
如果日志显示任务长时间处于WAIT状态,可能是当前资源组的并发数不足。
解决方案:
- 切换资源组:
- 在DataStudio中修改数据集成任务调试所用的资源组。
- 在运维中心修改任务调度时使用的数据集成任务执行资源组。
- 新增独享资源组:参考文档新增和使用独享数据集成资源组,确保任务有足够的资源运行。
3. 脏数据问题
如果任务因脏数据超出限制而失败,可能是数据质量问题导致的。
报错现象:
- 当脏数据数量超出限制时,任务会立即停止,此前传输的数据量取决于任务运行到报错时的状态。
解决方案:
- 检查日志:
- 进入日志详情页,点击
Detail log url查看具体日志和脏数据信息。
- 进入日志详情页,点击
- 处理乱码问题:
- 确保原始数据无乱码。
- 统一数据库、客户端和浏览器的编码格式,推荐使用
utf8mb4。 - 修改JDBC连接字符串,例如:
jdbc:mysql://xxx.x.x.x:3306/database?com.mysql.jdbc.faultInjection.serverCharsetIndex=45。 - 在RDS控制台修改数据库编码格式为
utf8mb4。
4. SSRF攻击问题
如果报错提示任务存在SSRF攻击(Task have SSRF attacks),可能是数据源配置问题导致的。
解决方案:
- 更换资源组:对于基于数据库内网的数据源,请使用独享数据集成资源组运行任务。
5. FTP Check节点任务报错
如果报错内容为The current time has exceeded the end-check time point!或File not Exists or exceeded the end-check time point!,可能是FTP Check节点的检测策略配置不合理。
解决方案:
- 重新配置Check停止时间:
- 根据业务需求,为FTP Check节点任务设置合理的Check停止时间。
- 确认Done文件是否存在:
- 检查FTP数据源中是否存在所需的Done文件。
6. MySQL节点任务报错
如果报错信息为sql execute failed! 暂不支持的jdbc驱动,可能是数据源创建模式选择错误导致的。
解决方案:
- 重新选择数据源模式:
- 使用连接串模式创建MySQL数据源。
- 在数据源管理页面编辑目标数据源,确认其创建模式。
7. 实时同步任务重复报错
如果实时同步任务重复报错,可能是源端DDL变更导致的。
解决方案:
- 手动处理DDL变更:
- 在目标端数据库手动执行相应的DDL变更。
- 调整DDL消息处理策略:
- 启动任务时将DDL消息处理策略由“出错”改为“忽略”。
- 停止任务后再次将策略还原为“出错”,并重启任务。
8. 其他常见问题
如果报错信息为no available machine resources under the task resource group,说明当前资源组没有可用资源。
解决方案:
- 在运维中心页面,修改任务执行使用的调度资源组。
总结
请根据实际报错信息和任务场景,逐一排查上述可能原因,并按照对应的解决方案进行处理。如果问题仍未解决,请提供更详细的报错日志或上下文信息,以便进一步分析和定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。