
大数据计算MaxCompute这个问题帮忙看下,好像是python环境问题引起的?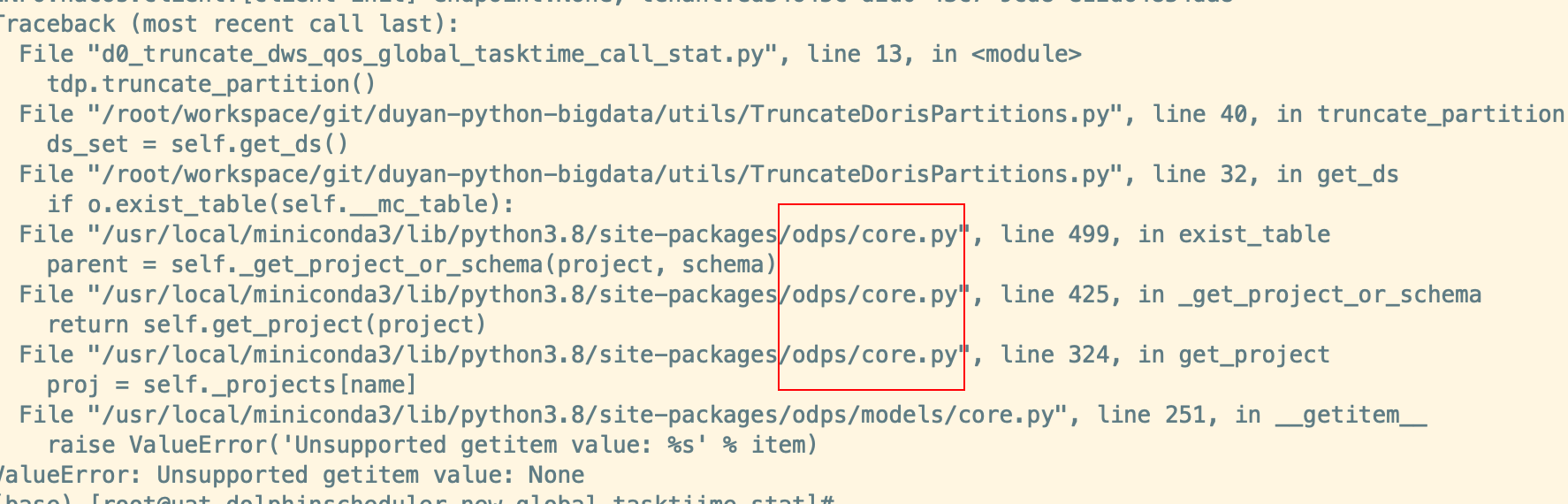
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述,MaxCompute中出现的错误可能与Python环境相关。以下是针对该问题的详细分析和解决方法:
您提到的问题可能是由于Python环境配置不当引起的。常见的现象包括: - 运行报错:例如function 'xxx' cannot be resolved或failed to get Udf info from xxx.py。 - 编码问题:当Python代码中存在非ASCII字符时,可能会导致运行失败。
MaxCompute默认使用Python 2运行作业。如果您的代码中包含Python 3特有的语法或非ASCII字符,可能会导致运行失败。
解决措施: - 确保代码兼容Python 2。如果必须使用Python 3,请在提交任务时明确指定Python 3环境。 - 如果代码中包含非ASCII字符(如中文),请在文件头部添加以下声明以指定编码格式:
# -*- coding: utf-8 -*-
MaxCompute UDF依赖的第三方库或资源可能未正确上传,或者上传的资源版本与代码需求不匹配。
解决措施: - 检查依赖资源是否已正确上传至MaxCompute项目。例如,对于包含二进制代码的包(如scipy),需要以archive方式上传,并将.whl后缀改为.zip。 - 示例上传命令:
odps.create_resource('scipy.zip', 'archive', file_obj=open('scipy-0.19.0-cp27-cp27m-manylinux1_x86_64.whl', 'rb'))
import操作,以避免因操作系统差异导致的执行错误。通过DataWorks上传的资源可能存在同步延迟,导致MaxCompute项目中使用的资源不是最新版本。
解决措施: - 确保资源已成功同步至MaxCompute项目。可以通过以下命令检查资源是否存在:
desc resource <resource_name>;
add file <file_name>;
如果UDTF或UDAF代码中基类的导入方式不正确,可能会导致failed to get Udf info from xxx.py错误。
解决措施: - 修改基类导入方式为正确的形式。例如:
from odps.udf import BaseUDTF
from odps.udf import BaseUDAF
如果问题并非由Python环境引起,而是由于性能问题导致的超时错误(如kInstanceMonitorTimeout),可以参考以下解决措施:
sys.stdout.write('your log')
sys.stdout.flush()
print('your log', flush=True)
set odps.function.timeout=3600;
set odps.sql.executionengine.batch.rowcount=512;
如果您的代码尝试访问外网,可能会导致运行失败,因为MaxCompute UDF默认不支持外网访问。
解决措施: - 提交网络连接申请表单,联系MaxCompute技术支持团队开通外网访问权限。
sourceIP is not in the white list,说明MaxCompute项目启用了IP白名单保护。请联系项目所有者将设备IP添加至白名单。ODPSError: ODPS entrance should be provided,说明未找到全局的MaxCompute对象入口。可以通过以下方式解决:
%enter配置全局入口。to_global方法设置全局入口。persist方法时显式传入odps对象。根据上述分析,您可以按照以下步骤逐步排查和解决问题: 1. 检查Python版本是否正确,并确保代码兼容性。 2. 确认依赖资源已正确上传且为最新版本。 3. 检查基类导入方式是否正确。 4. 如果涉及性能问题,增加日志并调整相关参数。 5. 确保网络访问权限和IP白名单配置无误。
如果问题仍未解决,请提供具体的错误信息和代码片段,以便进一步分析。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

