
Nacos server 2.0.3, sdk 1.4.2 k8s部署, 偶尔会出现连接超时, 有人遇到过吗?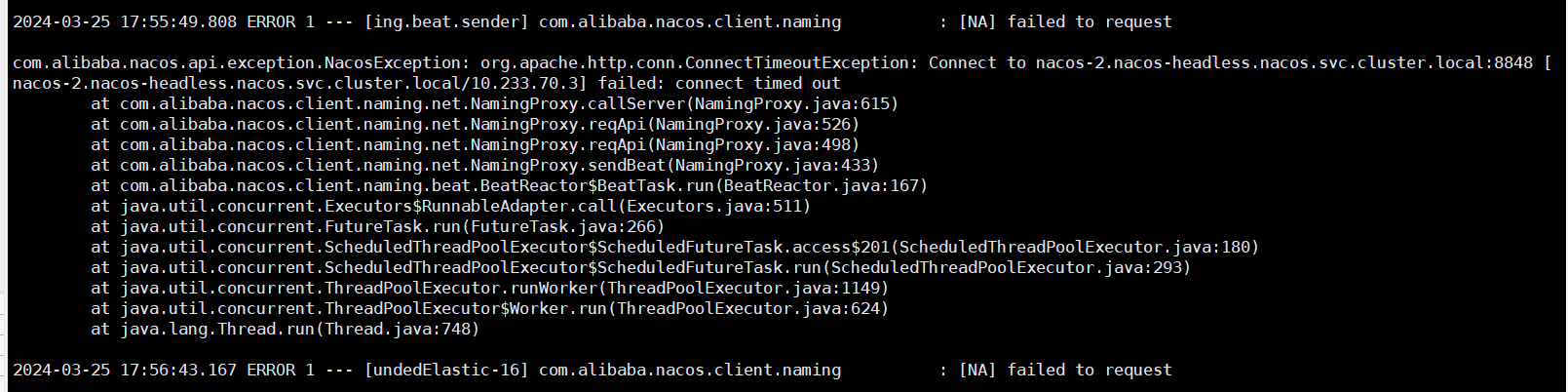
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的情况,Nacos Server版本为2.0.3,SDK版本为1.4.2,部署在Kubernetes(k8s)环境中,偶尔会出现连接超时的问题。结合知识库中的相关资料,此类问题可能由以下原因导致:
使用ping或telnet命令检查客户端与Nacos服务端之间的网络连通性:
ping <nacos-server-ip>
telnet <nacos-server-ip> <port>
如果网络不通,请检查防火墙规则或路由配置,确保客户端能够正常访问Nacos服务端。
如果网络不稳定,建议优化网络环境或延长客户端的超时时间。
由于您使用的是Nacos SDK 1.4.2版本,可以通过JVM参数调整超时时间:
-Dcom.alibaba.nacos.client.naming.ctimeout=5000 # 注册中心连接超时时间,默认3000ms
-Dcom.alibaba.nacos.client.naming.rtimeout=60000 # 注册中心请求超时时间,默认50000ms
-DNACOS.CONNECT.TIMEOUT=2000 # 配置中心连接超时时间,默认1000ms
说明:适当增加超时时间可以缓解因网络延迟或服务端响应慢导致的超时问题。
登录MSE控制台,查看Nacos服务端的监控数据: - 每秒查询数(QPS)和每秒操作数(OPS):确认是否超过实例的TPS限制。 - 连接数监控:检查长链路数量是否接近或超过连接数上限。 - JVM监控:查看是否存在频繁的Full GC现象。 - 资源监控:确认内存和CPU使用率是否接近或超过100%。
如果发现服务端性能瓶颈,建议升级实例规格以提升处理能力。
确认客户端是否存在Full GC、OOM或CPU争抢等问题。可以通过以下方式排查:
jstat或jstack工具分析客户端JVM状态。如果客户端运行在Kubernetes环境中,还需检查Pod的资源限制(如CPU和内存)是否合理。如果资源不足,可能导致客户端无法及时处理服务端返回的数据包。
当前使用的Nacos SDK版本为1.4.2,可能存在已知问题或兼容性风险。建议升级至更高版本(如2.1.2及以上),并根据新版本的文档调整超时参数:
-Dnacos.remote.client.grpc.timeout=5000 # 请求超时时间,默认3000ms
-Dnacos.remote.client.grpc.server.check.timeout=5000 # 服务端健康检测超时时间,默认3000ms
-Dnacos.remote.client.grpc.health.timeout=5000 # 连接健康检测超时时间,默认3000ms
如果Nacos服务端使用了域名访问,需确认客户端能够正确解析域名。如果出现UnknownHostException或Unable to resolve host等错误,请检查DNS配置或直接使用IP地址访问服务端。
${user_home}/logs/nacos/config.log),定位潜在的异常信息。通过上述步骤,您可以逐步排查并解决Nacos连接超时的问题。重点包括优化网络环境、调整超时时间、升级SDK版本以及监控服务端性能。如果问题仍未解决,建议联系阿里云技术支持团队,提供详细的日志和监控数据以便进一步分析。
