
Flink CDC里使用Flink Stream Load 导入数据 为什么会有找不到事务的错误?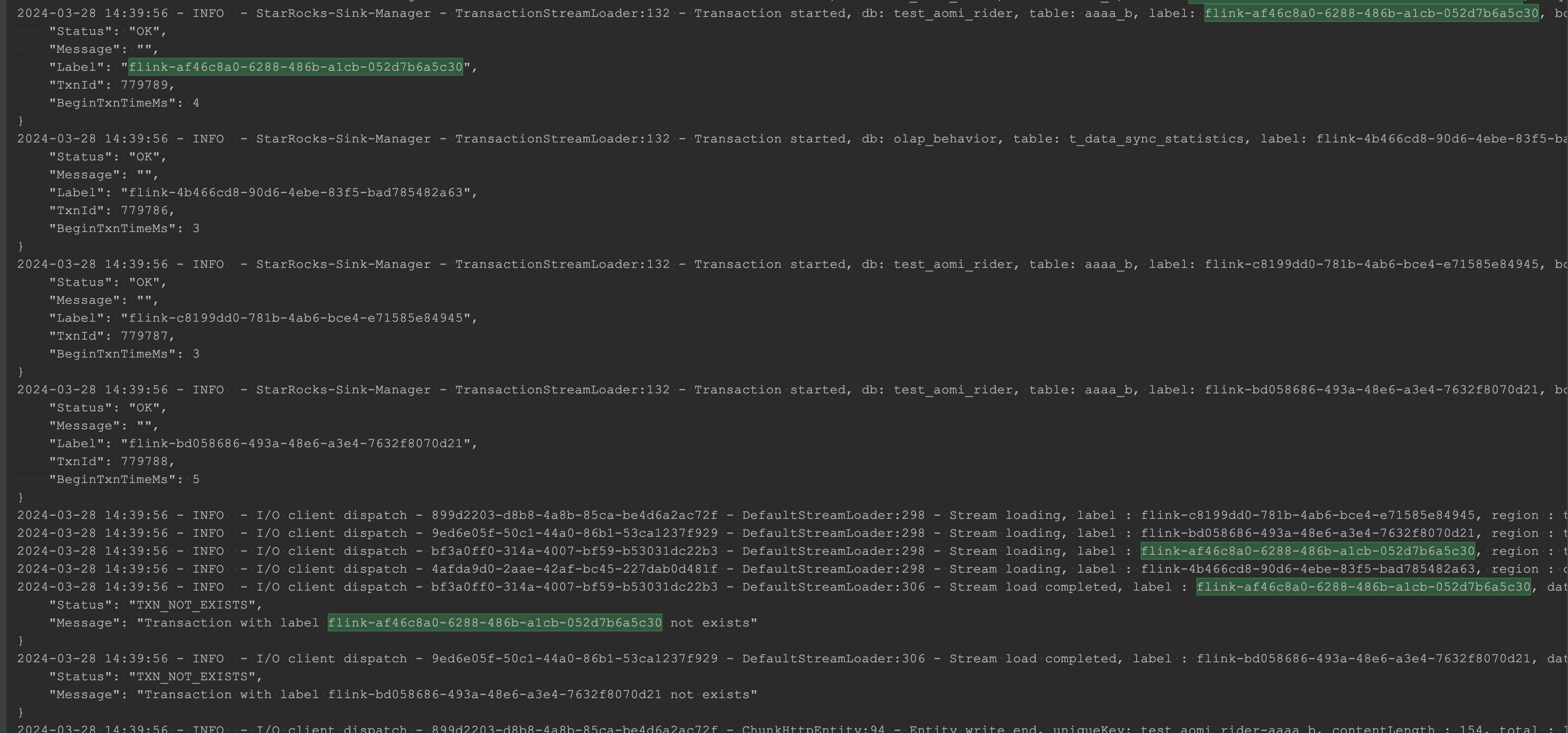
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 和 Flink Stream Load 导入数据时,出现“找不到事务”的错误可能与以下原因和配置相关:
Flink Stream Load 在导入数据时,默认会使用两阶段提交(2PC)来保证 Exactly-Once 语义。如果事务机制未正确启用或配置不当,可能会导致找不到事务的错误。
确保在 Sink 配置中启用了两阶段提交(2PC)。可以通过以下参数进行配置:
sink.enable-2pc=true
此参数默认值为 true,但如果被显式关闭(设置为 false),则可能导致事务无法正常创建或提交。
在 Stream Load 中,每个导入任务需要一个唯一的 label 标识。如果 sink.label-prefix 参数未正确设置,可能会导致事务标识冲突或无法找到事务。
确保在 Sink 配置中设置了全局唯一的 sink.label-prefix 参数:
sink.label-prefix=your_unique_prefix
注意: 在 2PC 场景下,sink.label-prefix 必须全局唯一,否则可能导致事务冲突或丢失。
Stream Load 默认通过 FE(Frontend)节点写入数据。如果未开启请求重定向,可能会导致 BE(Backend)节点无法正确处理事务。
确保在 Sink 配置中启用了请求重定向功能:
auto-redirect=true
此参数默认值为 true,但如果被关闭,可能会导致事务无法正确路由到后端节点。
Stream Load 的事务可能会因为超时而被系统自动清理,从而导致找不到事务的错误。
检查并调整以下超时相关参数: - FE 配置:
stream_load_default_timeout_second=600
此参数定义了 Stream Load 的默认超时时间,默认值为 600 秒。如果导入任务耗时较长,可以适当增加该值。
doris.request.read.timeout=60s
doris.request.connect.timeout=30s
确保连接和读取超时时间足够长,以避免因网络延迟或任务耗时过长导致的超时问题。
如果数据写入频率过高,可能会导致表级别的死锁,进而引发事务无法正常创建或提交。
降低数据写入频率,对数据进行批量处理。例如,调整以下参数以控制写入频率:
sink.buffer-size=1048576
sink.buffer-count=3
同时,确保批量写入的数据量适中,避免单次写入过大或过小。
如果 Flink 和目标数据库之间的网络连通性存在问题,可能会导致事务请求失败或超时。
如果使用 Maxwell 或 Canal 作为 CDC 数据源,在故障恢复时可能会投递重复的变更事件,导致 Flink 在处理这些事件时出现事务冲突。
在 Flink 作业中启用去重机制:
table.exec.source.cdc-events-duplicate=true
同时,在源表上定义主键(PRIMARY KEY),以便 Flink 使用主键对重复事件进行去重。
通过以上分析,建议按照以下步骤排查和解决问题: 1. 确保启用了两阶段提交(2PC)并设置了全局唯一的 sink.label-prefix。 2. 检查并调整超时时间配置,避免因超时导致事务丢失。 3. 优化数据写入频率,避免表死锁。 4. 检查网络连通性,确保 Flink 和目标数据库之间的通信正常。 5. 如果使用 Maxwell 或 Canal,启用去重机制以避免重复事件导致的事务冲突。
通过以上措施,可以有效解决“找不到事务”的问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

