
请教一个问题 flink sql ?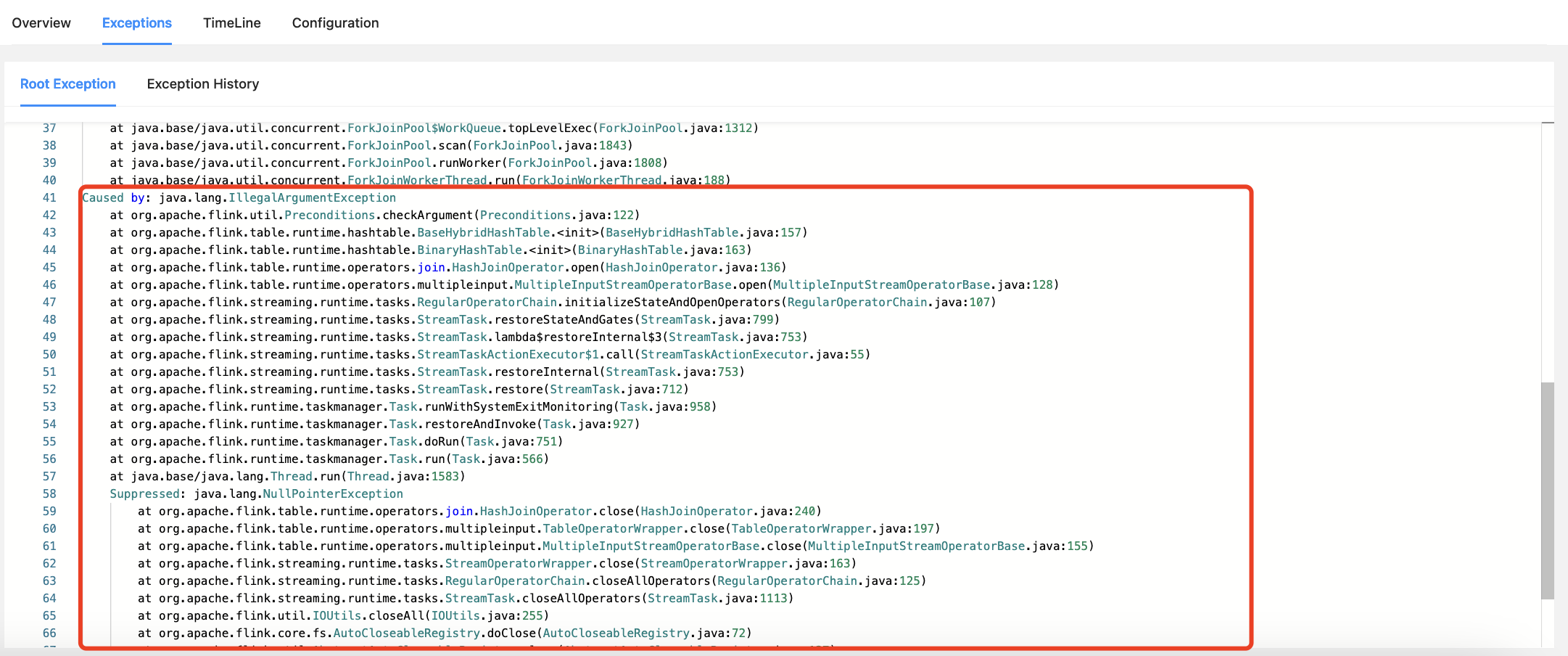

sql 中 left join 的很多次 ,Flink 1.19 开始了报错?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink SQL 中,LEFT JOIN 的多次使用可能会导致报错,尤其是在 Flink 1.19 及之后的版本中。这种问题通常与优化器的行为变化、资源限制或数据倾斜有关。以下是可能导致问题的原因及解决方案:
在 Flink 1.19 中,优化器对 JOIN 操作的处理更加严格,尤其是当存在数据倾斜时,可能会触发错误。
使用 SKEW 提示来优化数据倾斜问题:
SELECT /*+ SKEW(src) */
FROM src AS T
LEFT JOIN dim1 FOR SYSTEM_TIME AS OF PROCTIME() AS D1
ON T.a = D1.a;
SKEW 提示会触发 Replicated Shuffle Hash 策略,从而缓解数据倾斜问题。SKEW 提示只能用于主表,不能用于维表。如果 SKEW 提示无法解决问题,可以尝试手动调整 JOIN 的分区策略,例如通过 REPLICATED_SHUFFLE_HASH 提示:
SELECT /*+ REPLICATED_SHUFFLE_HASH(dim1) */
FROM src AS T
LEFT JOIN dim1 FOR SYSTEM_TIME AS OF PROCTIME() AS D1
ON T.a = D1.a;
Flink 在执行 LEFT JOIN 时,尤其是涉及多个维表的场景,可能会因为内存不足或资源分配不合理而报错。
ALL 缓存策略时,维表数据会被加载到内存中。如果维表数据量较大,可能会导致内存溢出(OOM)。LEFT JOIN 会增加中间结果集的大小,进一步加剧内存压力。调整缓存策略:
ALL 缓存策略以提高性能。LRU 或 TTL 缓存策略,并设置较短的 TTL 时间(如几秒至几十秒)。CREATE TEMPORARY TABLE rds_dim (
a INT,
b VARCHAR,
c VARCHAR
) WITH (
'connector' = 'rds',
'password' = '<yourPassword>',
'tableName' = '<yourTableName>',
'url' = 'jdbc:mysql://xxx',
'userName' = '<yourUsername>',
'lookup.cache' = 'LRU',
'lookup.cache.ttl' = '10s'
);
增加 TaskManager 内存:
taskmanager.memory.process.size 参数来增加 TaskManager 的内存。Flink 对维表 JOIN 有一些特定的限制,这些限制可能会导致在多次 LEFT JOIN 时出现问题。
JOIN 仅支持当前时刻的快照关联,不支持历史数据的回溯。ON 条件中不能使用类型转换函数(如 CAST),否则可能会导致查询失败。确保连接条件正确:
ON 条件中必须包含维表中支持随机查找的字段的等值条件。避免过多的维表 JOIN:
JOIN 次数。Flink 1.19 对 SQL 优化器进行了改进,这可能导致某些之前能够运行的查询在新版本中报错。
JOIN 的执行计划生成更加严格,可能会暴露之前隐藏的问题。检查 SQL 语法和提示:
REPLICATED_SHUFFLE_HASH 和 SKEW)符合 Flink 1.19 的规范。升级文档参考:
多语句问题:
multi-statement be found,可能是由于 JDBC 驱动版本与数据库配置不兼容导致的。allowMultiQueries=true 参数。索引问题:
JOIN 条件中的字段符合 MySQL 的最左前缀原则。在 Flink 1.19 中,LEFT JOIN 的多次使用可能会因数据倾斜、内存不足、维表限制或版本升级等原因导致报错。建议从以下几个方面入手解决问题: 1. 使用 SKEW 或 REPLICATED_SHUFFLE_HASH 提示优化数据倾斜。 2. 调整维表缓存策略,避免内存溢出。 3. 确保 JOIN 条件符合维表的限制要求。 4. 检查 SQL 语法和提示,确保与新版本兼容。
如果问题仍未解决,建议提供具体的报错信息和 SQL 语句,以便进一步分析和定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

