
文字识别OCR这个模板和模型有啥区别?我现在觉得模板识别不准,是不是得用模型?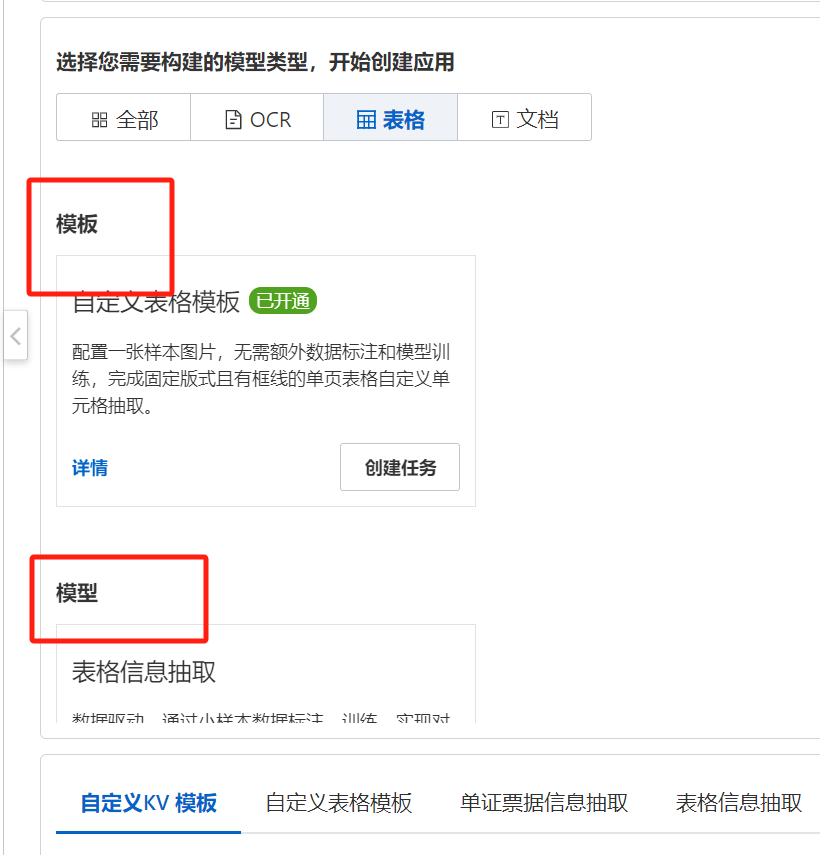
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,这里您看到的自定义表格模版和表格信息抽取模型都属于OCR文档自学习的内容。
自定义表格模板是针对固定版式的单页有框线表格表单数据提供的一款定制化产品,经过配置调优的模板识别准确率可达85%以上。参考文档:文档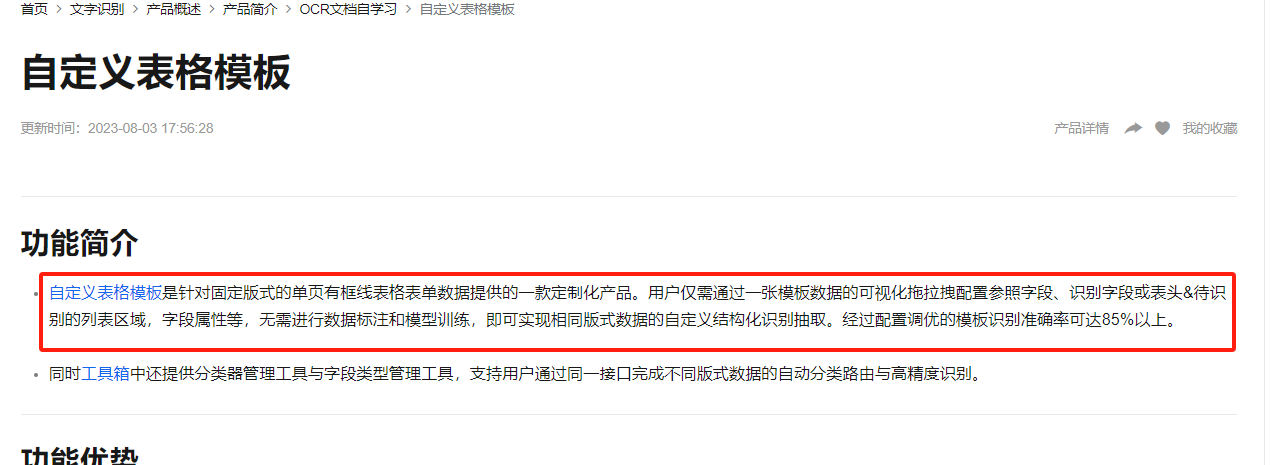
表格信息抽取是基于深度学习的信息抽取自学习模型任务,可对版式相对固定的表格、表单的等类型数据有较好的效果,支持用户自定义抽取字段,通过平台可视化引导,完成数据标注和模型训练,在图像质量较好情况下,通过100+训练样本标注,调优后模型识别准确率可超95%+。参考文档:文档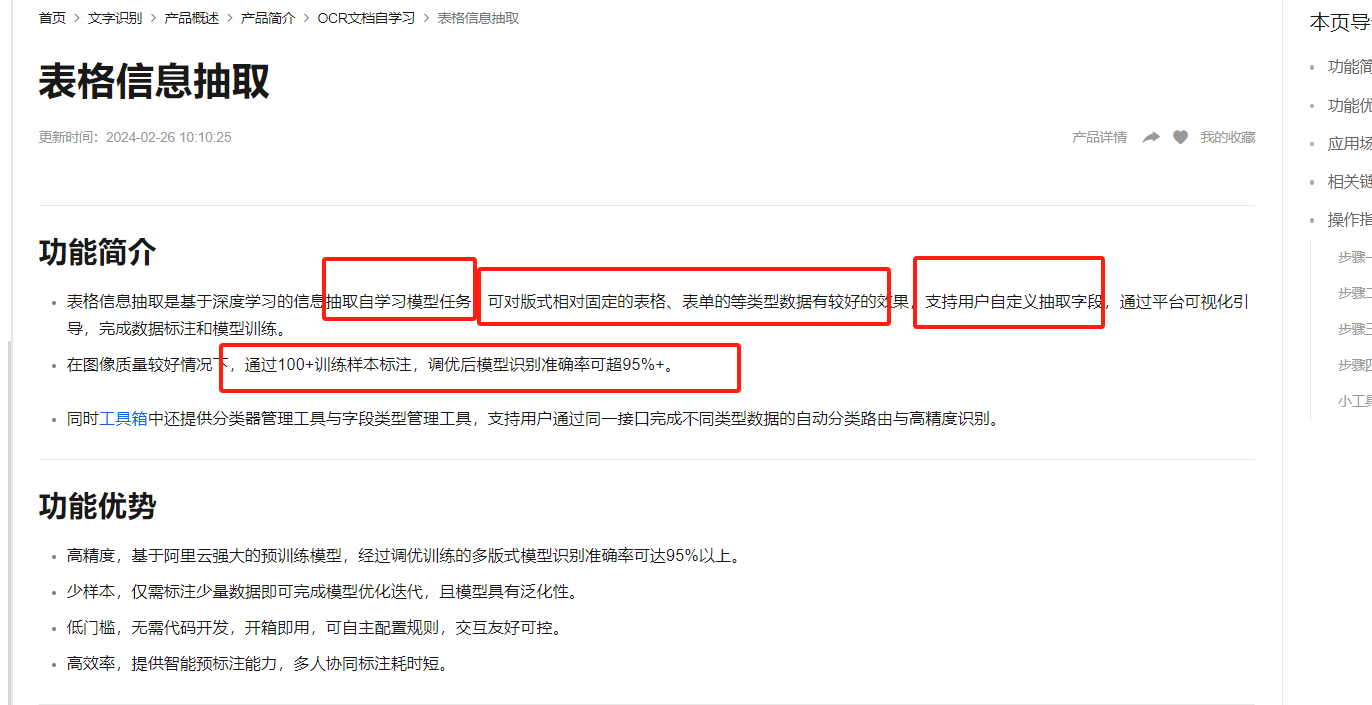
您可以尝试表格信息抽取自学习模型,看识别效果如何。
文字识别OCR中的模板和模型确实存在区别。
首先,我们来了解一下它们的定义:
如果你发现使用模板识别的结果不准确,可能是因为你的文档内容或格式与模板不完全匹配。在这种情况下,可以考虑以下几种解决方案:
综上所述,选择使用模板还是模型取决于具体的应用需求和文档特性。对于固定格式且变化不大的文档,模板可能是一个简单有效的解决方案;而对于格式多变或需要高度定制化的应用,使用模型可能会更加灵活和准确。
在文字识别OCR领域,模板和模型各有其特点和适用场景。以下是具体分析:
模板识别:
优点:模板识别的优点在于它可以针对特定的文档格式和布局进行定制,从而提供较高的识别精度。通过模板,开发者可以预设文档的结构和样式,使得OCR系统能够更准确地定位和识别文本内容。这种方法适用于固定格式的文档,如发票、表单或任何具有重复布局的文档。
缺点:模板识别的缺点是它需要人工干预来创建和调整模板,这可能需要一定的时间和专业知识。此外,当文档格式发生变化时,模板可能需要更新,这限制了其灵活性。
模型识别:
优点:基于深度学习的OCR模型通常更加灵活,能够处理各种不同类型的文本和字体。这些模型通过学习大量的数据来提高识别的准确性,并且可以适应不同的识别任务和环境变化。
缺点:模型识别可能需要更多的计算资源和数据来进行训练,而且对于某些特定类型的文档,通用模型可能不如专门定制的模板准确。
综上所述,如果您发现模板识别不够准确,那么使用基于深度学习的OCR模型可能是一个更好的选择。这些模型能够自动学习和适应不同的文本特征,从而提高识别的准确性。不过,具体选择哪种方法还需要根据您的具体需求和应用环境来决定。



