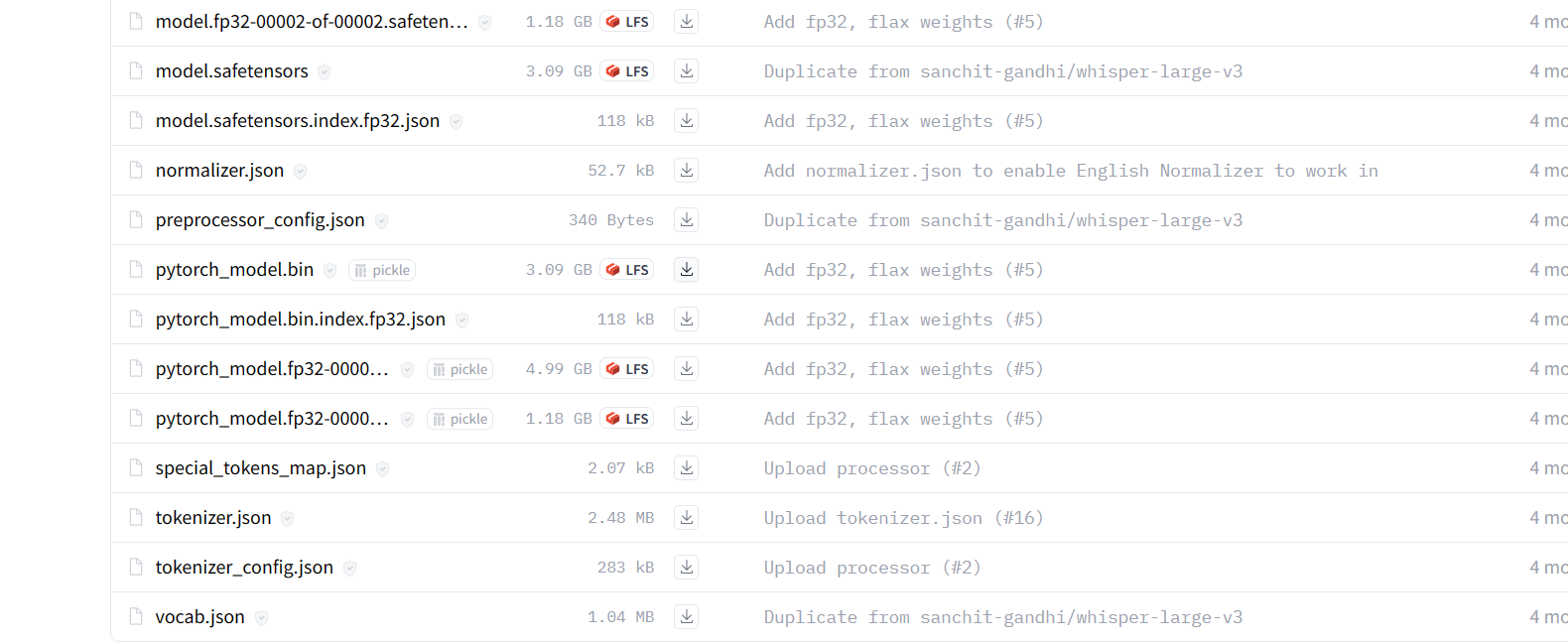
modelscope-funasr的whisper-large-v3 是不是 没有对应的 tokenizer?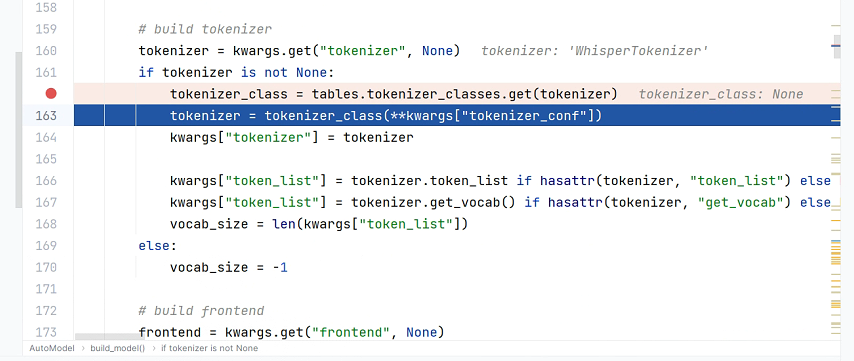

Whisper-large-v3模型通常不提供单独的tokenizer。
在深度学习中,特别是在自然语言处理(NLP)领域,模型和tokenizer通常是配套提供的。Tokenizer负责将文本数据转换为模型可以理解的格式,例如将句子分割成单词或子词(subwords)。然而,对于自动语音识别(ASR)模型,如Whisper-large-v3,它们通常接收原始音频数据作为输入,而不是已经分割好的文本。因此,这些模型不需要传统意义上的tokenizer来预处理文本数据。
此外,如果您需要在ASR之后对接NLP模型,您可能需要一个单独的tokenizer来处理ASR输出的文本数据。在这种情况下,您可以使用适合您NLP模型的tokenizer,例如BPE(Byte Pair Encoding)或其他适用于您所用NLP框架的tokenizer。
总之,Whisper-large-v3作为一个ASR模型,其设计目的是直接从音频文件中提取文本信息,因此不包含用于文本预处理的tokenizer。如果您需要在ASR之后进行NLP处理,您需要另外准备一个tokenizer来适配您的NLP模型。