
flink cdc可以对ClickHouse进行操作吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink cdc connector 消费 Debezium 里的数据,经过处理再sink出来,给到Clickhouse,这个流程还是相对比较简单的。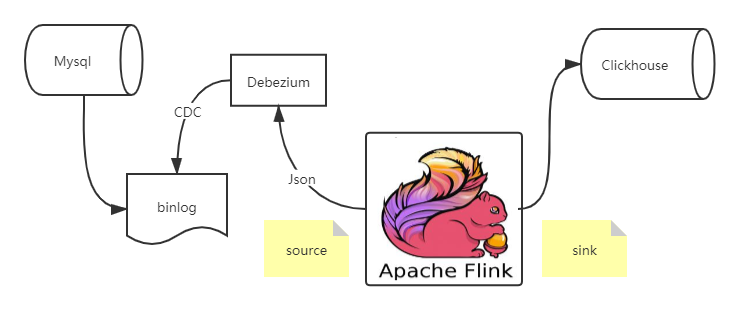
package name.lijiaqi.cdc;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.google.gson.Gson;
import com.google.gson.internal.LinkedTreeMap;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.source.SourceRecord;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.HashMap;
public class MySqlBinlogSourceExample {
public static void main(String[] args) throws Exception {
SourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("localhost")
.port(3306)
.databaseList("test")
.username("flinkcdc")
.password("dafei1288")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 添加 source
env.addSource(sourceFunction)
// 添加 sink
.addSink(new ClickhouseSink());
env.execute("mysql2clickhouse");
}
// 将cdc数据反序列化
public static class JsonDebeziumDeserializationSchema implements DebeziumDeserializationSchema {
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
Gson jsstr = new Gson();
HashMap<String, Object> hs = new HashMap<>();
String topic = sourceRecord.topic();
String[] split = topic.split("[.]");
String database = split[1];
String table = split[2];
hs.put("database",database);
hs.put("table",table);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取数据本身
Struct struct = (Struct)sourceRecord.value();
Struct after = struct.getStruct("after");
if (after != null) {
Schema schema = after.schema();
HashMap<String, Object> afhs = new HashMap<>();
for (Field field : schema.fields()) {
afhs.put(field.name(), after.get(field.name()));
}
hs.put("data",afhs);
}
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
hs.put("type",type);
collector.collect(jsstr.toJson(hs));
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
public static class ClickhouseSink extends RichSinkFunction<String>{
Connection connection;
PreparedStatement pstmt;
private Connection getConnection() {
Connection conn = null;
try {
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
String url = "jdbc:clickhouse://localhost:8123/default";
conn = DriverManager.getConnection(url,"default","dafei1288");
} catch (Exception e) {
e.printStackTrace();
}
return conn;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = getConnection();
String sql = "insert into sink_ch_test(id,name,description) values (?,?,?)";
pstmt = connection.prepareStatement(sql);
}
// 每条记录插入时调用一次
public void invoke(String value, Context context) throws Exception {
//{"database":"test","data":{"name":"jacky","description":"fffff","id":8},"type":"insert","table":"test_cdc"}
Gson t = new Gson();
HashMap<String,Object> hs = t.fromJson(value,HashMap.class);
String database = (String)hs.get("database");
String table = (String)hs.get("table");
String type = (String)hs.get("type");
if("test".equals(database) && "test_cdc".equals(table)){
if("insert".equals(type)){
System.out.println("insert => "+value);
LinkedTreeMap<String,Object> data = (LinkedTreeMap<String,Object>)hs.get("data");
String name = (String)data.get("name");
String description = (String)data.get("description");
Double id = (Double)data.get("id");
// 未前面的占位符赋值
pstmt.setInt(1, id.intValue());
pstmt.setString(2, name);
pstmt.setString(3, description);
pstmt.executeUpdate();
}
}
}
@Override
public void close() throws Exception {
super.close();
if(pstmt != null) {
pstmt.close();
}
if(connection != null) {
connection.close();
}
}
}
}
——参考链接。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


