
请问我在NLP自学习平台的文本实体提取中,做了任务标注、模型发布,然后这里的概率都是0,请问这个怎么处理呢?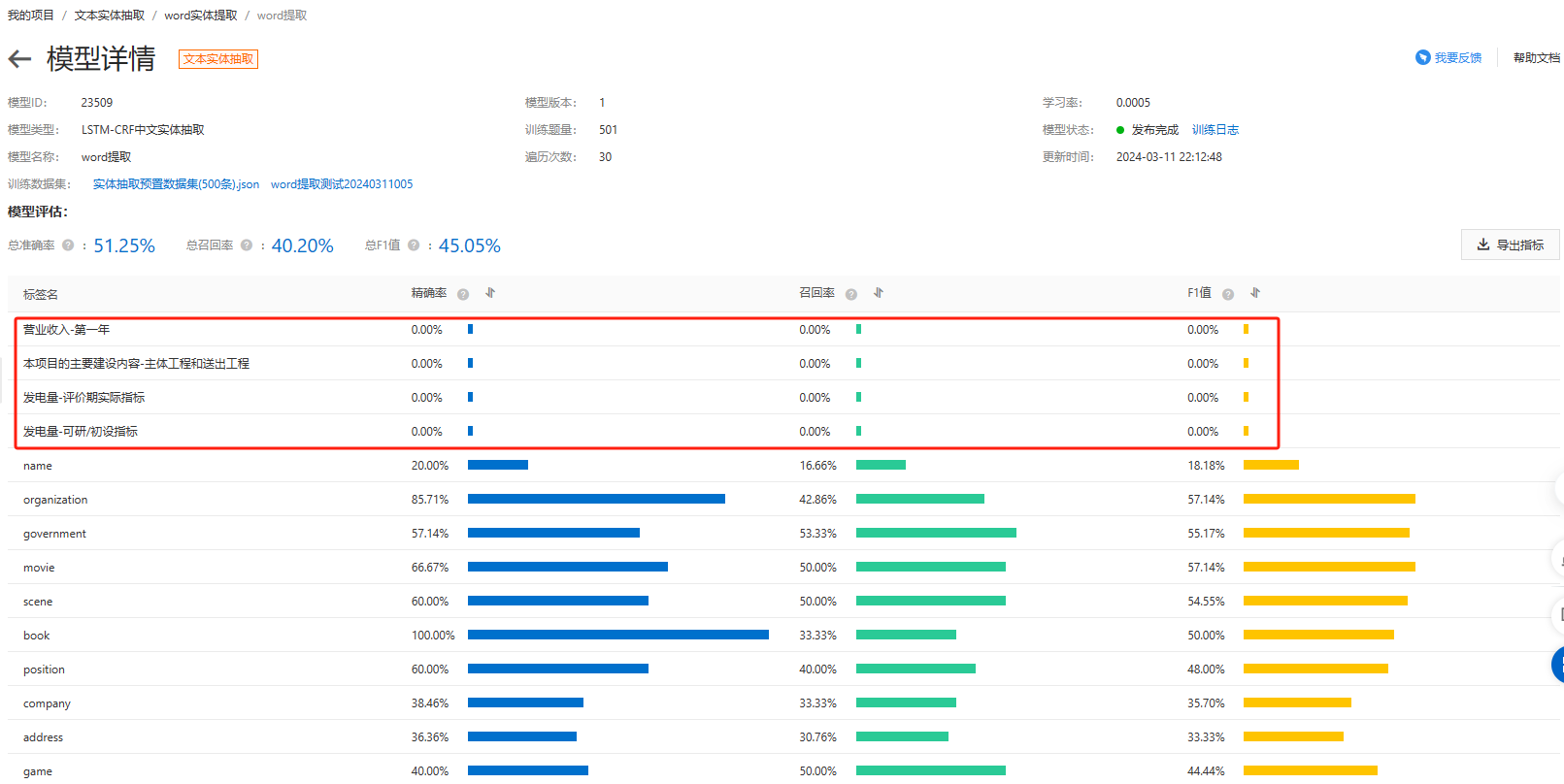
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在NLP自学习平台进行文本实体提取时,如果模型发布后预测结果中所有实体的概率都是0,这可能意味着模型未能正确地从训练数据中学习到实体特征,或者存在一些潜在问题。以下是几个排查和解决步骤:
数据检查:
模型训练情况:
模型配置与参数调整:
模型评估与输出解读:
技术支持:
重新训练:
请注意,在实际操作中,解决问题往往需要结合具体场景和平台提供的功能工具来逐步排查和优化。

