为什么 我们这边的文字识别OCR现在出现了发票类型识别不稳定的情况 ? 帮忙处理一下。现在系统用的时候 会经常性的有问题。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个是因为有时候pdf转图片的时候缺少了字体,然后转出的图片效果有问题导致的。我们已经根据一些pdf,添加了相应的字体。加上字体后,刚才试了下这个 “深圳欧华1月1.pdf” 这个文件,是正常的,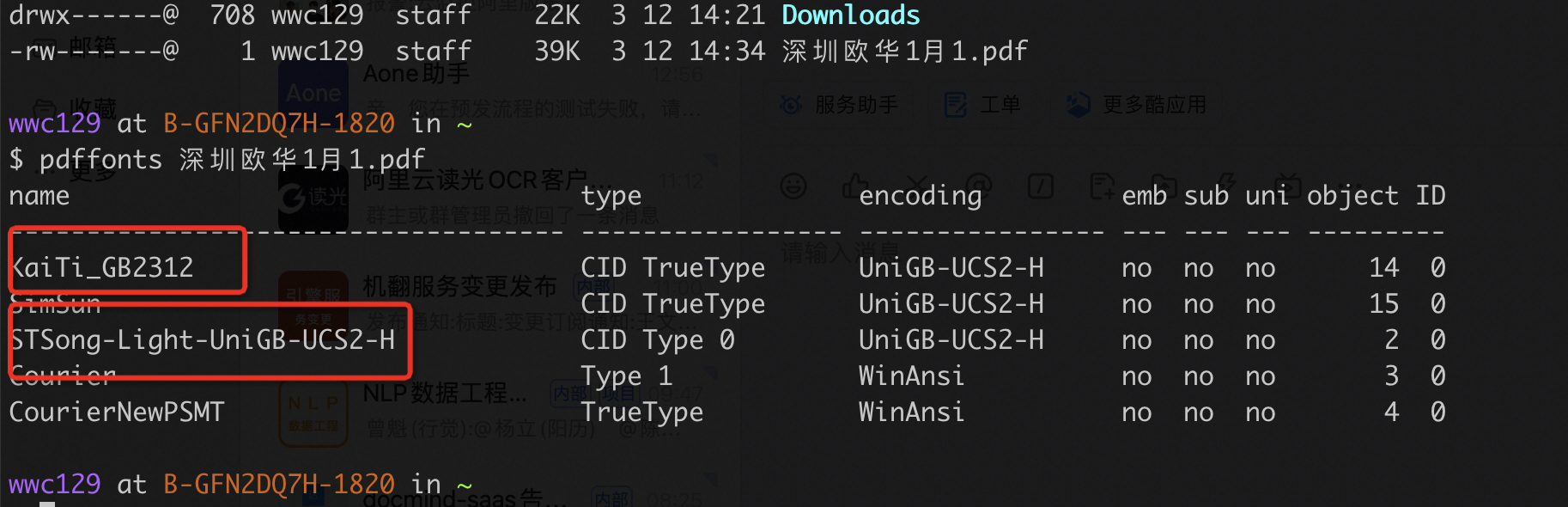 缺少了这2种。 此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”
缺少了这2种。 此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”
文字识别(OCR)在发票类型识别方面出现不稳定的情况可能由多种原因造成。以下是一些可能的原因以及相应的解决方案:
图像质量问题:发票图像的清晰度、对比度、亮度等因素都可能影响OCR的识别效果。如果图像质量不佳,可能导致OCR引擎无法准确识别发票类型。
发票类型多样性:不同的发票类型具有不同的格式、布局和字符特点。如果OCR引擎没有针对这些差异进行充分优化,就可能出现识别不稳定的情况。
OCR引擎性能:OCR引擎的性能和准确性直接影响发票类型的识别效果。如果引擎性能不佳或存在缺陷,就可能导致识别错误或不稳定。
系统环境问题:系统资源不足、网络延迟或其他软件冲突也可能导致OCR识别出现问题。
优化图像质量:
更新或替换OCR引擎:
增加预处理和后处理步骤:
定制训练和优化:
优化系统环境:
错误处理与反馈机制: