

我想问一下,pg cdc 在执行检查点的时候是不是要和数据库有关系,比如提交slot 的消费点,我手动改了一下这两个数据库中监控的表,检查点马上就成功了,还有就是检查点执行频繁了对数据库性能有影响没得,如果这个库长时间没有变动,会导致检查点失败,有什么解决办法没得(目前我想到就是定时更新一个表中的某条数据)。
下面是我改了数据后的检查点,基本上都是成功。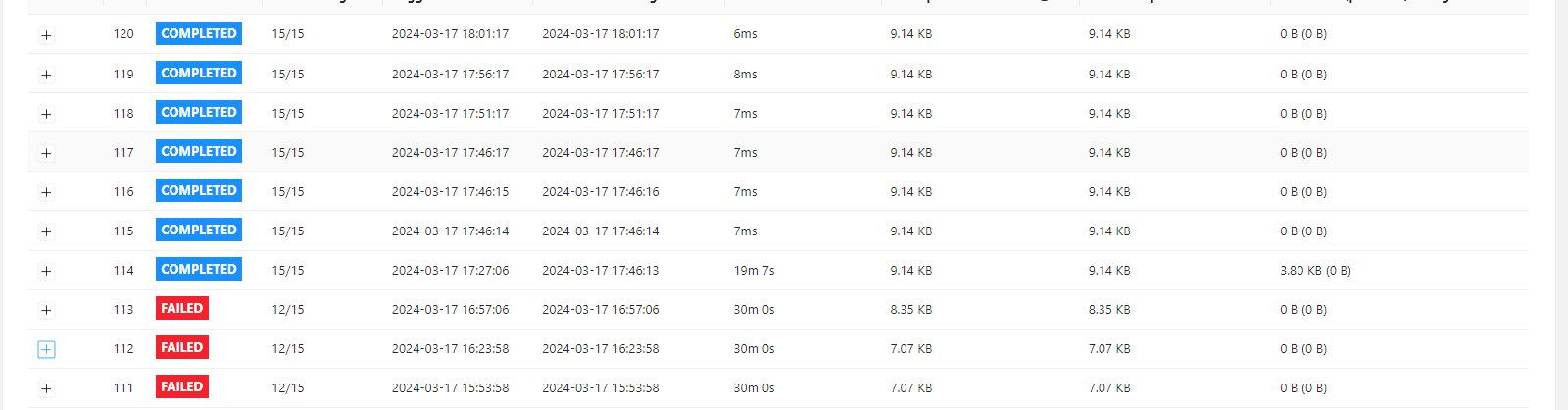
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您的问题主要涉及以下几个方面: 1. PostgreSQL CDC(Change Data Capture)检查点与数据库的关系。 2. 检查点执行频繁对数据库性能的影响。 3. 长时间无数据变动导致检查点失败的解决办法。
以下是对这些问题的详细解答:
在 PostgreSQL 中,CDC 的实现依赖于逻辑复制槽(Logical Replication Slot),而逻辑复制槽的核心机制是通过 pg_replication_slots 视图中的 restart_lsn 和 confirmed_flush_lsn 来管理 WAL(Write-Ahead Logging)日志的保留和消费点。
restart_lsn:表示消费者可能仍然需要的最旧 WAL 地址。如果该值为 NULL,则表示没有保留的 WAL 日志。confirmed_flush_lsn:表示逻辑槽的消费者已经确认接收到的数据位置。对于物理槽,此字段为 NULL。当您手动修改了监控表中的数据后,检查点成功的原因可能是: - 数据库检测到有新的事务或数据变更,触发了 WAL 日志的更新。 - 这些变更使得 restart_lsn 和 confirmed_flush_lsn 的值得以推进,从而允许检查点成功完成。
因此,检查点的成功与否确实与数据库中是否有数据变动密切相关。如果没有数据变动,WAL 日志可能不会更新,导致检查点无法推进。
检查点的执行频率对数据库性能的影响主要体现在以下几个方面:
pg_replication_slots 中的 restart_lsn 和 confirmed_flush_lsn),这会消耗一定的 CPU 和内存资源。建议:根据业务需求合理配置检查点的频率,避免过于频繁的检查点操作。可以通过调整 checkpoint_timeout 参数来控制检查点的时间间隔。
如果数据库长时间没有数据变动,可能会导致以下问题: - WAL 日志无法推进:由于没有新的事务或数据变更,restart_lsn 和 confirmed_flush_lsn 的值无法更新,导致检查点失败。 - 资源浪费:未使用的 WAL 日志文件会占用磁盘空间,增加存储成本。
针对这种情况,您可以采取以下解决方案:
restart_lsn 和 confirmed_flush_lsn 的值。UPDATE your_table SET update_time = NOW() WHERE id = 1;
max_slot_wal_keep_size 参数max_slot_wal_keep_size 参数用于限制逻辑复制槽保留的 WAL 日志大小。如果设置为非负值,可以避免 WAL 日志无限增长。ALTER SYSTEM SET max_slot_wal_keep_size = '1GB';
SELECT pg_reload_conf();
temporary 类型)。临时复制槽不会被保存在磁盘上,并且会在会话结束时自动删除。SELECT * FROM pg_create_logical_replication_slot('temp_slot', 'test_decoding', true);
SELECT pg_drop_replication_slot('slot_name');
max_slot_wal_keep_size 参数以限制 WAL 日志的增长。通过以上措施,您可以有效避免检查点失败的问题,同时优化数据库性能。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
