
机器学习PAI模型是如何区分哪个是emb,哪个是dense的啊?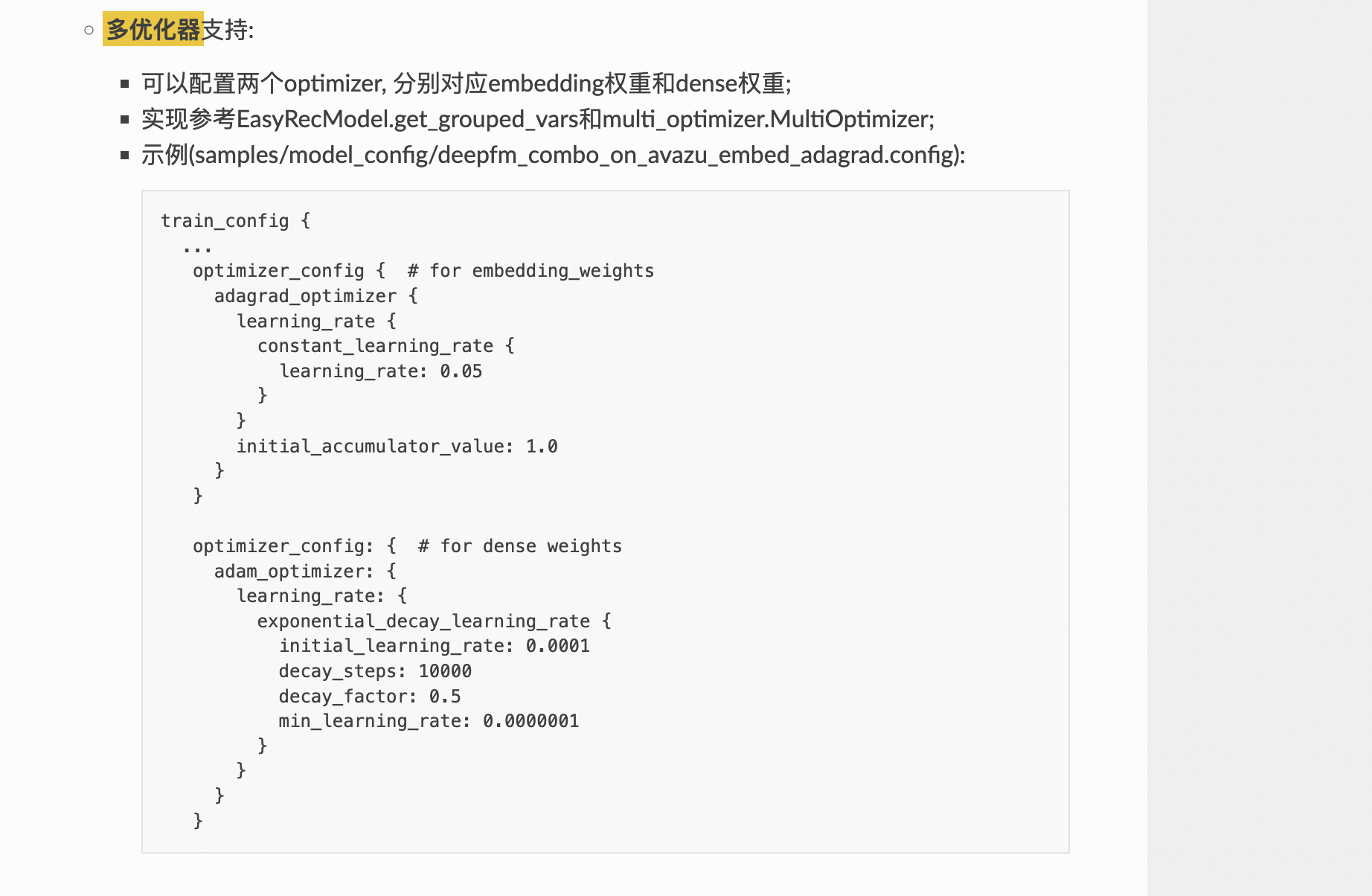
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云机器学习平台PAI中,模型区分embedding(emb)和dense(稠密)特征的方式主要依赖于用户在配置文件或代码中的显式定义。以下是具体的区分方式和实现细节:
在PAI的组件化框架(如EasyRec)中,特征通常被组织为不同的Feature Groups,每个组可以明确指定其包含的特征类型。例如: - dense组:用于存储连续型数值特征。 - sparse组:用于存储离散型特征(如ID类特征),这些特征通常会被映射为Embedding。
以下是一个示例配置文件片段:
feature_groups: {
group_name: "dense"
feature_names: "F1", "F2" # 连续型特征
}
feature_groups: {
group_name: "sparse"
feature_names: "C1", "C2" # 离散型特征
}
在这个配置中,dense组的特征会直接作为模型输入,而sparse组的特征则会通过Embedding层进行映射。
对于离散型特征(如ID类特征),PAI提供了专门的Embedding机制来处理。例如,使用tf.get_embedding_variable或feature_column接口时,用户需要明确指定哪些特征需要通过Embedding进行映射。
# 使用EmbeddingVariable定义稀疏特征
var = tf.get_embedding_variable("var_0", embedding_dim=3, initializer=tf.ones_initializer(tf.float32))
emb = tf.nn.embedding_lookup(var, tf.cast([0, 1, 2, 5, 6, 7], tf.int64))
# 使用feature_column定义稀疏特征
columns_list = [tf.contrib.layers.sparse_column_with_embedding(column_name="col_emb", dtype=tf.string)]
W = tf.contrib.layers.shared_embedding_columns(sparse_id_columns=columns_list, dimension=3)
在这段代码中: - embedding_lookup或shared_embedding_columns明确指定了哪些特征需要通过Embedding层进行处理。 - 其他未经过Embedding处理的特征(如连续型特征)则被视为dense特征。
在PAI的深度推荐算法模型(如DLRM)中,模型的主干网络(Backbone)通过blocks定义了不同特征的处理方式。例如: - num_emb块:处理数值型特征的Embedding。 - sparse块:处理稀疏特征的Embedding。
以下是一个示例配置:
backbone {
blocks {
name: 'num_emb'
inputs {
feature_group_name: 'dense'
}
}
blocks {
name: 'sparse'
inputs {
feature_group_name: 'sparse'
}
}
}
在这个配置中: - num_emb块处理的是dense组的特征。 - sparse块处理的是sparse组的特征。
在数据预处理阶段,用户可以通过标注字段的类型来区分dense和emb特征。例如,在PAI Designer工作流中,用户可以在字段设置中选择哪些列是特征列,并标注其类型(连续型或离散型)。
| 字段名称 | 字段类型 | 处理方式 |
|---|---|---|
| F1 | 连续型 | 直接作为dense特征输入 |
| C1 | 离散型 | 通过Embedding层映射为emb特征 |
PAI-TF引入了动态Embedding机制(如EmbeddingVariable),允许用户无需预先指定词汇表大小(vocabulary_size),而是根据训练数据动态扩展词典。这种方式特别适用于在线学习场景,能够自动区分并处理稀疏特征。
var = tf.get_embedding_variable("dynamic_var", embedding_dim=16)
emb = tf.nn.embedding_lookup(var, tf.cast([0, 1, 2, 5, 6, 7], tf.int64))
在这种情况下,dynamic_var会动态地为稀疏特征分配Embedding空间,而其他未涉及的特征则默认为dense。
dense,哪些是emb。EmbeddingVariable可以避免手动管理词汇表大小的问题,同时支持特征无损训练。通过以上方法,PAI模型能够清晰地区分dense和emb特征,并针对不同类型特征采用合适的处理方式。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。
