
Flink CDC 里Calcite数据管理实战 这本书中,有个LOAD案例,根据内容我执行的时候报错这个是为什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述,您在执行Flink CDC中的LOAD案例时遇到了报错。以下是可能的原因分析及解决方案,基于知识库中的相关资料进行整理和推导:
如果您的LOAD案例涉及复杂的SQL逻辑或大量表的加载操作,可能会导致生成的JobGraph过大,从而触发类似以下错误:
RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051
这种问题通常发生在作业逻辑过于复杂或数据量较大的场景中。
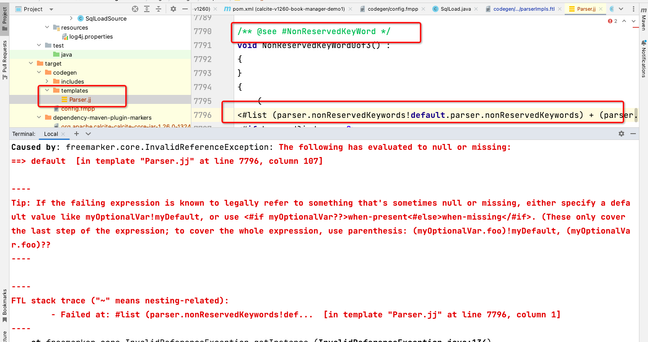
如果您在执行LOAD案例时使用了某些自定义函数或依赖了社区版的内部API(例如org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery),可能会出现以下错误:
Caused by: java.lang.NoSuchMethodError
这通常是由于依赖冲突或使用了阿里云Flink版本未兼容的内部API导致的。
如果您的作业中引入了第三方库(例如org.codehaus.janino.CompilerFactory),可能会因为类加载顺序不一致导致冲突,报错信息类似于:
java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
这种情况通常发生在不同机器上运行时,类加载顺序不一致导致的冲突。
如果您的LOAD案例涉及外部数据源(例如MySQL、Kafka等),可能会因为网络连通性问题导致任务失败。例如: - 如果配置了自建DNS域名解析,可能会出现JobManager heartbeat timeout错误。 - 如果Flink无法正确解析Kafka Broker的Endpoint,可能会导致timeout expired while fetching topic metadata错误。
根据上述可能的原因,以下是针对性的解决方案:
table.exec.operator-name.max-length: 1000
具体操作请参考如何配置自定义的作业运行参数。
@Public或@PublicEvolving的API。如果使用了社区版的内部API,请替换为兼容的实现。classloader.parent-first-patterns.additional: org.codehaus.janino
同时,确保Flink相关依赖的作用域设置为provided,例如:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
jobmanager.retrieve-taskmanager-hostname: false
这不会影响作业通过域名连接外部服务。
zkCli.sh或zookeeper-shell.sh工具登录Kafka使用的Zookeeper。get /brokers/ids/{your_broker_id}
listener_security_protocol_map中的Endpoint是否可以被Flink访问。LOAD案例涉及MySQL CDC源表,请确保以下配置正确:
SHOW MASTER STATUS;
查看Binlog_Do_DB和Binlog_Ignore_DB字段。
LOAD案例涉及大批量数据加载,建议调整下游存储的batchsize参数,避免因缓存机制导致数据延迟或性能瓶颈。希望以上内容能够帮助您定位并解决问题!如果仍有疑问,请提供具体的报错信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

