
modelscope-funasr的同一个文件,多次调用,咋还会返回不同的结果?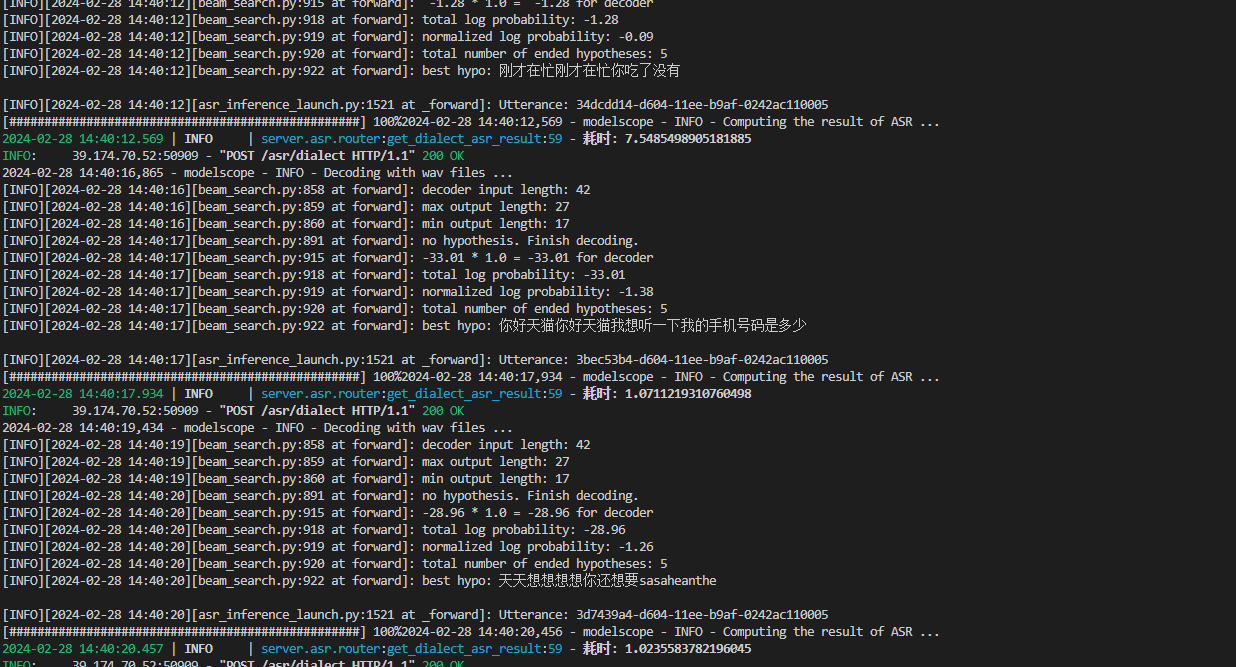
AutomaticSpeechRecognitionPipeline.call() missing 1 required positional argument: 'audio_in'
modelscope-funasr的同一个文件,多次调用,可能会返回不同的结果。原因可能包括:
随机性:模型在处理输入数据时可能会引入一些随机性,尤其是在使用概率模型的情况下。
训练数据的变化:模型的训练数据可能会随着时间而变化,或者在重新训练模型时使用了不同的数据集。
模型参数的初始化:每次调用模型时,其参数可能会被初始化为不同的值。
环境因素:例如计算资源、操作系统等都可能影响模型的输出。
其他未知因素:可能存在其他未考虑到的因素导致模型的输出有所不同。
如果你希望获得更一致的结果,可以考虑对模型进行更多的调优,或者确保在调用模型时使用相同的参数和设置。
在使用ModelScope-Funasr进行语音识别时,同一个文件多次调用返回不同结果的情况可能是由于以下原因:
为了减少这种不确定性,可以尝试以下方法:
总的来说,了解这些可能的原因和解决方案,可以帮助您更好地使用ModelScope-Funasr进行语音识别,并提高结果的稳定性。
你去看0.8.8分支的文档。main分支是1.0版本的用法。 https://github.com/alibaba-damo-academy/FunASR/discussions/1319 此回答整理自钉群“modelscope-funasr社区交流”

