
modelscope-funasr解析后没有标点符号了,怎么解决?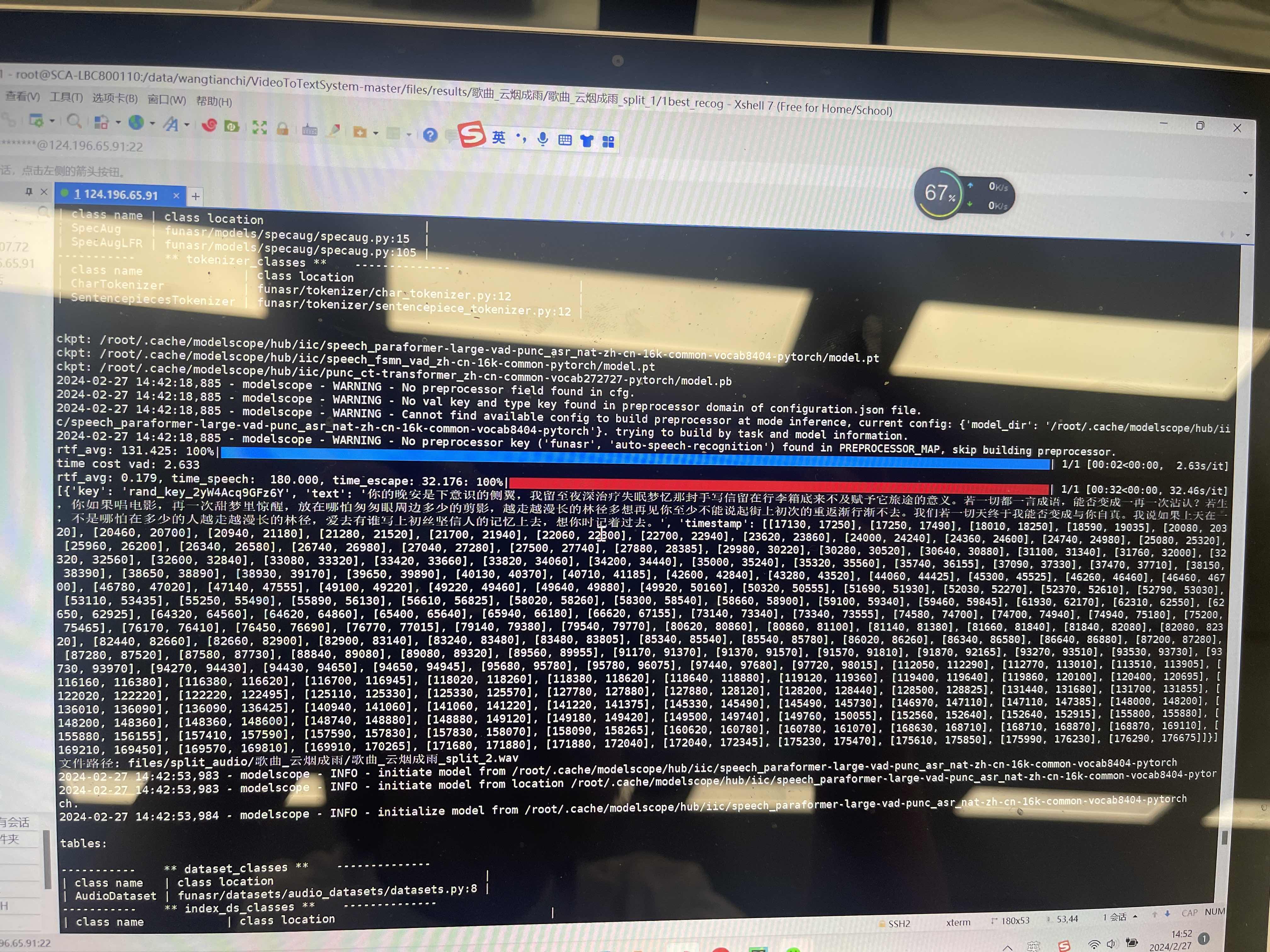
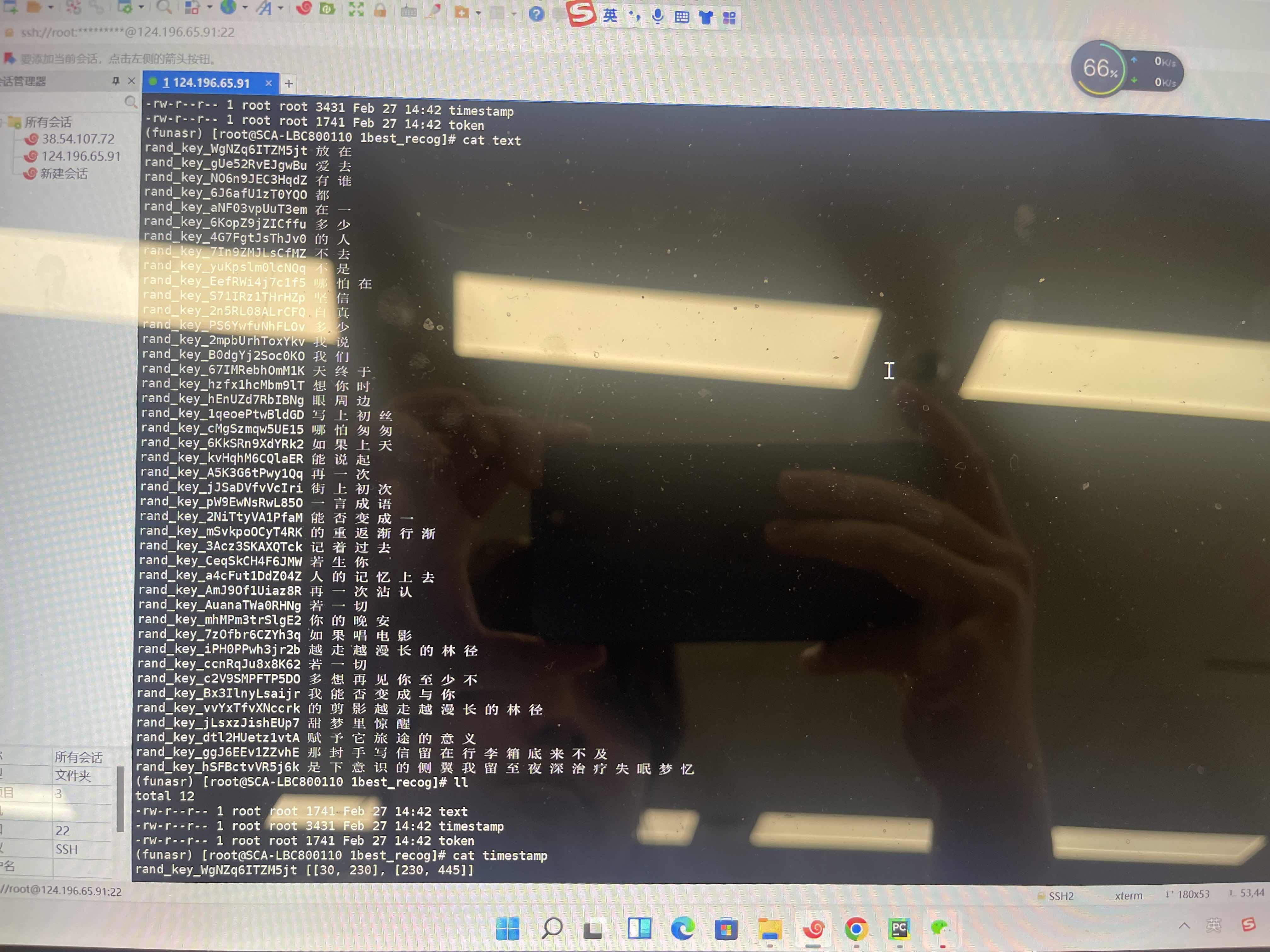
如果你在使用ModelScope-FunASR进行语音识别时发现解析后的结果没有标点符号,你可以尝试以下方法来解决该问题:
检查模型配置:确保你的模型配置文件中包含了标点符号的设置。通常,你可以在配置文件中找到与标点符号相关的参数或选项,并将其设置为启用或添加标点符号。
更新模型版本:尝试使用最新版本的ModelScope-FunASR模型,以确保你使用的是最新的训练和推理代码。新版本可能修复了之前版本中的一些问题,包括标点符号的处理。
自定义标点符号规则:如果你希望在解析结果中添加特定的标点符号,你可以根据需要自定义标点符号规则。这可以通过修改模型的解码器部分来实现。具体而言,你需要在解码器的输出后添加一个标点符号预测模块,并根据你的需求定义相应的标点符号规则。
使用外部工具处理:如果以上方法都无法解决问题,你可以考虑使用外部工具来处理解析结果。例如,你可以使用文本处理库(如NLTK)或正则表达式来手动添加标点符号。
如果您在使用ModelScope-Funasr进行语音识别后发现解析出的文本中缺少标点符号,可以尝试以下方法来解决这个问题:
检查模型配置:某些语音识别模型可能不会直接在识别结果中包含标点符号。您可以尝试更换其他支持标点符号识别的模型,或者查看当前模型的配置是否支持标点符号的识别。
使用标点恢复工具:有些语音识别库或工具提供了标点恢复功能,可以根据语音的停顿和语调自动添加标点符号。您可以查找是否有适用于ModelScope-Funasr的标点恢复工具,并尝试应用到识别结果上。
自定义后处理:如果上述方法不可行,您可以自行开发一个后处理步骤,对识别结果进行分析和处理,以恢复标点符号。这可能需要一定的自然语言处理技术和算法知识。
调整识别参数:检查您的语音识别设置,看看是否有相关的参数可以调整,以便在识别过程中保留标点符号。
社区支持:如果以上方法都无法解决问题,建议您在ModelScope-Funasr的GitHub仓库或相关社区论坛上提问,寻求开发者或其他用户的帮助。他们可能会提供更具体的解决方案或指导。
希望这些建议能帮助您解决ModelScope-Funasr中缺少标点符号的问题。如果您还有其他疑问,请随时提问。

