
使用 阿里云全托管flink产品, 在flink1.17版本中, 使用 KafkaSource API创建source端,源码中默认开启了checkpoint的时候提交offset 到kafka-broker, 自己的代码中不用在手动开启checkopint, 全部通过 VVR产品界面开启,但是目前发现一个问题,就是消费数据的时候,消费一段时间后,kafka-group的 offset 就重置了,看起来像重置到 earliest 了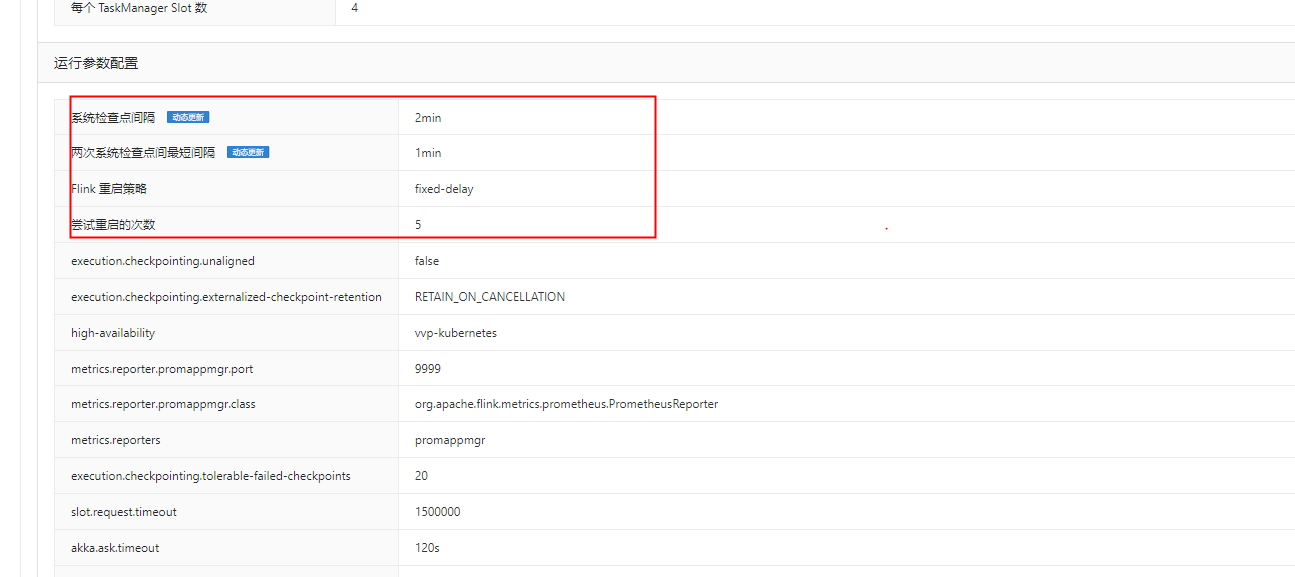
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink 1.17 版本中,如果您遇到 Kafka 消费者组的 offset 在消费一段时间后被重置的情况,这通常与 Flink 的检查点(checkpoint)机制和 Kafka 的消费者配置有关。以下是可能导致 offset 重置的几个原因及解决方法:
auto.offset.reset 配置:Kafka 消费者的 auto.offset.reset 配置决定了当消费者组找不到之前提交的 offset 时该如何处理。如果这个配置设置为 earliest,那么消费者会从分区的开始位置读取数据,这可能解释了您观察到的 offset 被重置到最早的行为。enable.auto.commit 配置:在 Flink 中,如果开启了检查点,enable.auto.commit 配置将会失效,因为 Flink 会使用检查点来控制 offset 的提交。如果没有开启检查点,那么 enable.auto.commit 配置将决定 Flink 何时提交 offset。auto.offset.reset 的配置来选择从何处开始消费。综上所述,为了解决这个问题,您需要检查 Flink 作业的检查点配置是否正确,并确保 Kafka 消费者的相关配置(如 auto.offset.reset 和 enable.auto.commit)与您的期望一致。此外,监控检查点的成功率和作业的重启情况也是非常重要的,以确保数据的一致性和准确性。
这个问题可能是由于Flink的checkpoint机制导致的。在Flink中,checkpoint是用于保证故障恢复的一种机制,它会定期将状态数据存储到持久化存储系统中。当作业出现故障时,可以从最近的checkpoint恢复状态,从而继续处理数据。
在你的情况下,可能是因为checkpoint的频率设置得过高,导致Kafka的offset被重置到了最早的位置。你可以尝试调整checkpoint的频率,以解决这个问题。具体操作如下:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


