
DataWorks中mc使用数据集成同步oss的时候出现了表明和oss文件名不一致的问题,多了后缀?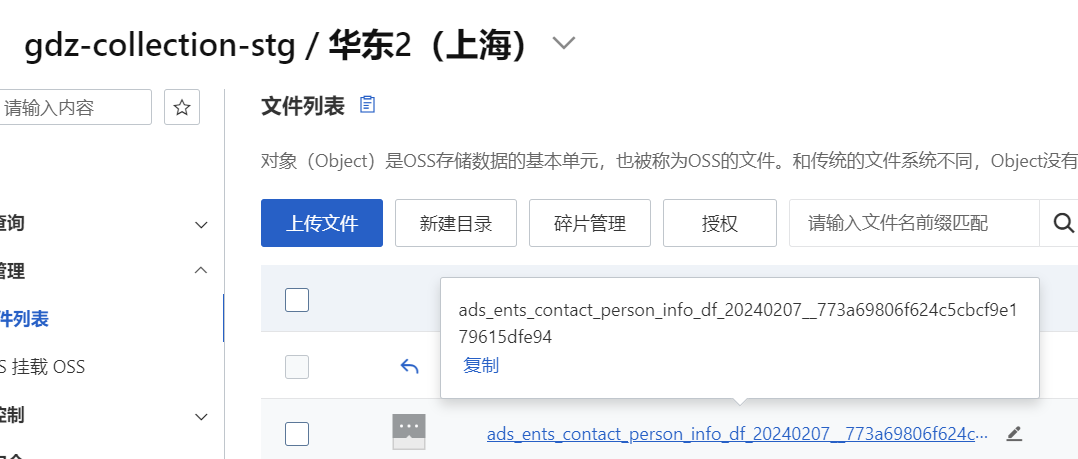
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中使用MaxCompute(MC)进行数据集成同步到OSS时,如果出现了表名和OSS文件名不一致且多了后缀的问题,这通常与OSS Writer的配置有关。以下是可能的原因和解决方案:
总的来说,为了解决表名和OSS文件名不一致的问题,您需要检查OSS Writer的配置,确保数据源名称的正确性,并考虑是否需要调整时区设置。如果问题依旧存在,建议查阅官方文档或联系技术支持以获得更详细的指导。
后缀部分原因可以参考看下oss writer插件文档相关说明哈 https://help.aliyun.com/zh/dataworks/user-guide/supported-data-source-types-and-read-and-write-operations#concept-uzy-hgv-42b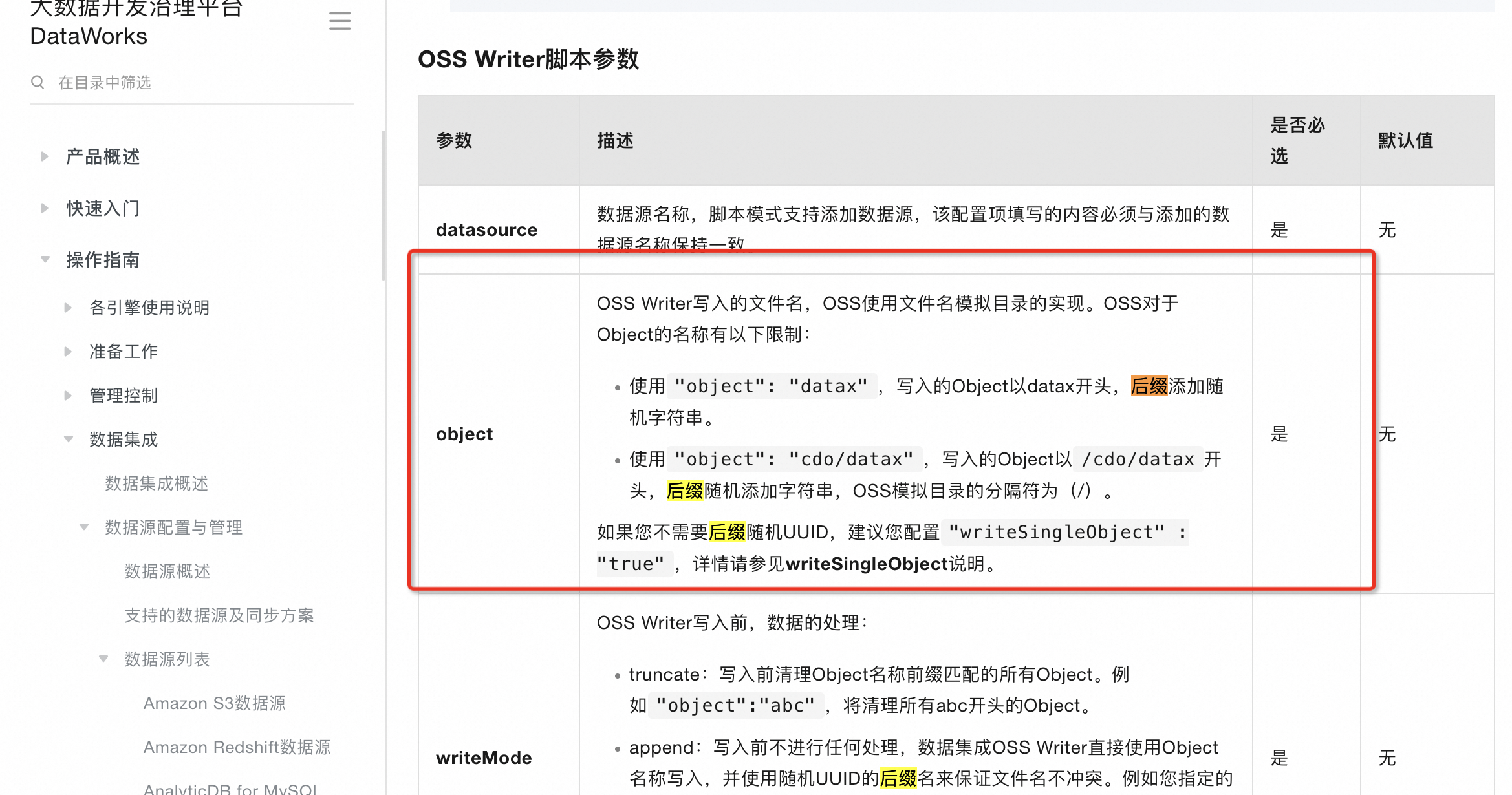
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


