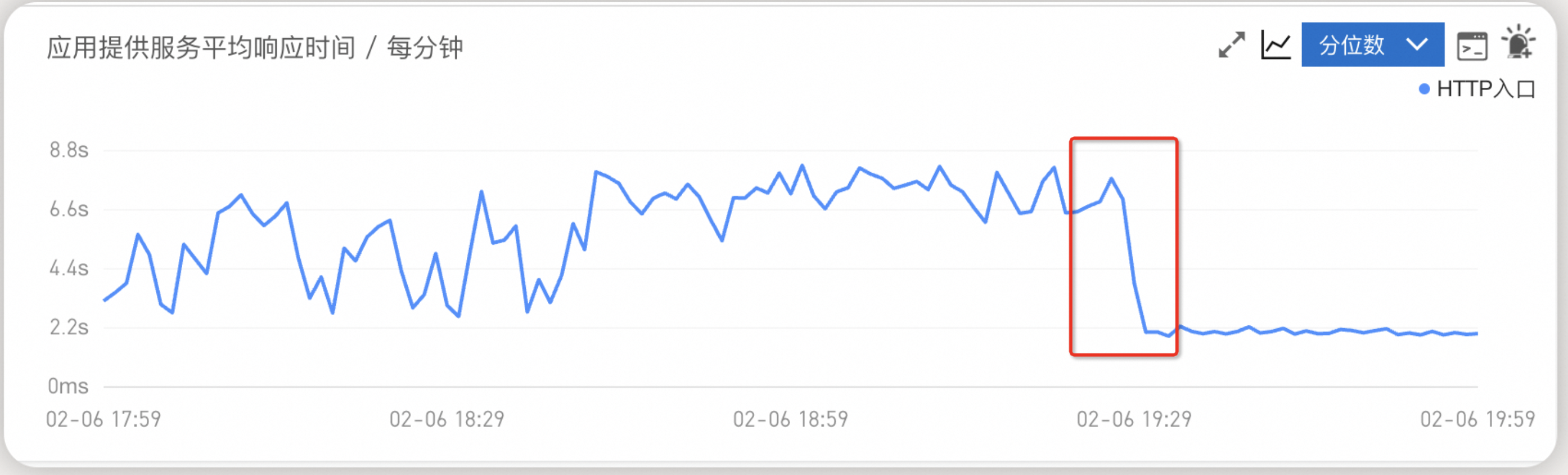
根据您提供的信息,支付接口在2月6日晚上6点到8点期间响应缓慢,但CPU、内存和JVM指标均未出现异常。通过扩容Pod副本数从2个增加到4个后,ARMS监控显示服务响应时间从7-8秒降低到2秒多。以下是对问题的分析和定位建议:
1. 问题现象分析
- 接口响应慢:支付接口的响应时间在特定时间段内显著增加(7-8秒),但扩容后响应时间明显下降(2秒多)。
- 资源使用正常:CPU、内存和JVM指标均未出现异常,说明问题可能并非由资源瓶颈引起。
- 扩容有效:扩容Pod副本数后,响应时间显著改善,表明问题可能与请求负载分布或单个Pod处理能力有关。
2. 可能的原因分析
结合知识库资料和您的描述,以下是可能导致该问题的原因:
(1) 线程池瓶颈
- Java应用通常依赖线程池处理请求。如果线程池配置不合理(如线程数不足或队列过长),在高并发场景下可能导致请求堆积,从而引发响应时间延长。
- 验证方法:
- 检查支付接口的线程池配置(如核心线程数、最大线程数、队列大小等)。
- 使用ARMS监控中的线程池监控功能,查看线程池的使用率和排队情况。
(2) 外部依赖性能问题
- 支付接口可能依赖外部服务(如数据库、缓存、第三方API等)。如果这些外部依赖在特定时间段内性能下降(如网络延迟、连接池耗尽等),会导致整体响应时间变长。
- 验证方法:
- 使用ARMS的调用链追踪功能,分析支付接口的上下游调用链路,定位是否存在慢调用或超时。
- 检查外部依赖的日志和监控数据,确认是否存在性能瓶颈。
(3) 锁竞争或同步问题
- 如果支付接口涉及共享资源(如分布式锁、数据库行锁等),在高并发场景下可能出现锁竞争,导致请求阻塞。
- 验证方法:
- 检查代码中是否存在同步块或锁操作。
- 使用ARMS的JVM监控功能,查看是否存在线程阻塞或死锁。
(4) Pod调度或网络问题
- 在ACK集群中,Pod的调度和网络通信可能影响性能。例如:
- Pod之间的网络延迟或丢包。
- 调度器未能均匀分配请求到多个Pod副本。
- 验证方法:
- 使用阿里云日志服务SLS检查Pod侧日志,确认是否存在网络异常或调度问题。
- 检查ACK集群的事件监控,查看是否存在Pod调度失败或网络抖动的情况。
(5) GC行为异常
- 尽管JVM内存使用正常,但如果发生频繁的Full GC或GC停顿时间较长,也可能导致接口响应变慢。
- 验证方法:
- 使用ARMS的JVM监控功能,查看GC频率和停顿时间。
3. 问题定位步骤
以下是具体的排查步骤,帮助您进一步定位问题:
(1) 检查ARMS监控数据
- 接口性能:查看支付接口的响应时间分布,确认是否存在特定时间段内的性能波动。
- 调用链分析:使用ARMS的调用链追踪功能,分析支付接口的上下游调用链路,定位慢调用或超时环节。
- 线程池监控:检查线程池的使用率和排队情况,确认是否存在线程池瓶颈。
- JVM监控:查看GC行为和内存使用情况,排除GC异常的可能性。
(2) 检查外部依赖
- 确认支付接口是否依赖外部服务(如数据库、缓存、第三方API等)。
- 检查外部依赖的性能监控数据,确认是否存在性能瓶颈。
(3) 检查Pod日志和事件
- 使用阿里云日志服务SLS检查Pod侧日志,确认是否存在异常信息。
- 检查ACK集群的事件监控,查看是否存在Pod调度失败或网络抖动的情况。
(4) 模拟高并发测试
- 使用压测工具(如PTS)模拟高并发场景,观察支付接口的性能表现。
- 结合ARMS监控数据,分析高并发场景下的性能瓶颈。
4. 优化建议
根据问题定位结果,以下是一些可能的优化措施:
(1) 优化线程池配置
- 根据实际负载调整线程池的核心线程数、最大线程数和队列大小,避免请求堆积。
(2) 优化外部依赖
- 如果外部依赖存在性能问题,可以考虑以下措施:
- 增加连接池大小。
- 引入缓存机制,减少对外部服务的直接调用。
(3) 优化锁机制
- 如果存在锁竞争问题,可以考虑以下措施:
- 使用无锁数据结构(如
ConcurrentHashMap)。
- 减少锁的粒度,避免长时间持有锁。
(4) 优化Pod调度
- 确保Pod副本均匀分布在不同的节点上,避免单节点资源争抢。
- 配置合理的HPA(Horizontal Pod Autoscaler)策略,动态调整Pod副本数以应对流量波动。
(5) 优化GC配置
- 如果GC行为异常,可以调整JVM的GC参数(如使用G1GC或ZGC),减少GC停顿时间。
5. 总结
通过上述分析和排查步骤,您可以逐步定位支付接口响应慢的根本原因。扩容Pod副本数虽然暂时缓解了问题,但并未解决根本原因。建议结合ARMS监控数据和日志信息,深入分析线程池、外部依赖、锁机制等方面的潜在问题,并采取相应的优化措施。
如果您需要进一步的帮助,请提供更多详细信息(如支付接口的调用链路、线程池配置、外部依赖等),以便更精准地定位问题。