根据您描述的问题现象和提供的日志信息,以下是可能的原因分析及解决方案:
问题现象
- Nacos版本为2.2.3,运行一段时间后持续报错。
- 应用重启后无法连接Nacos,但不重启时仍能正常访问。
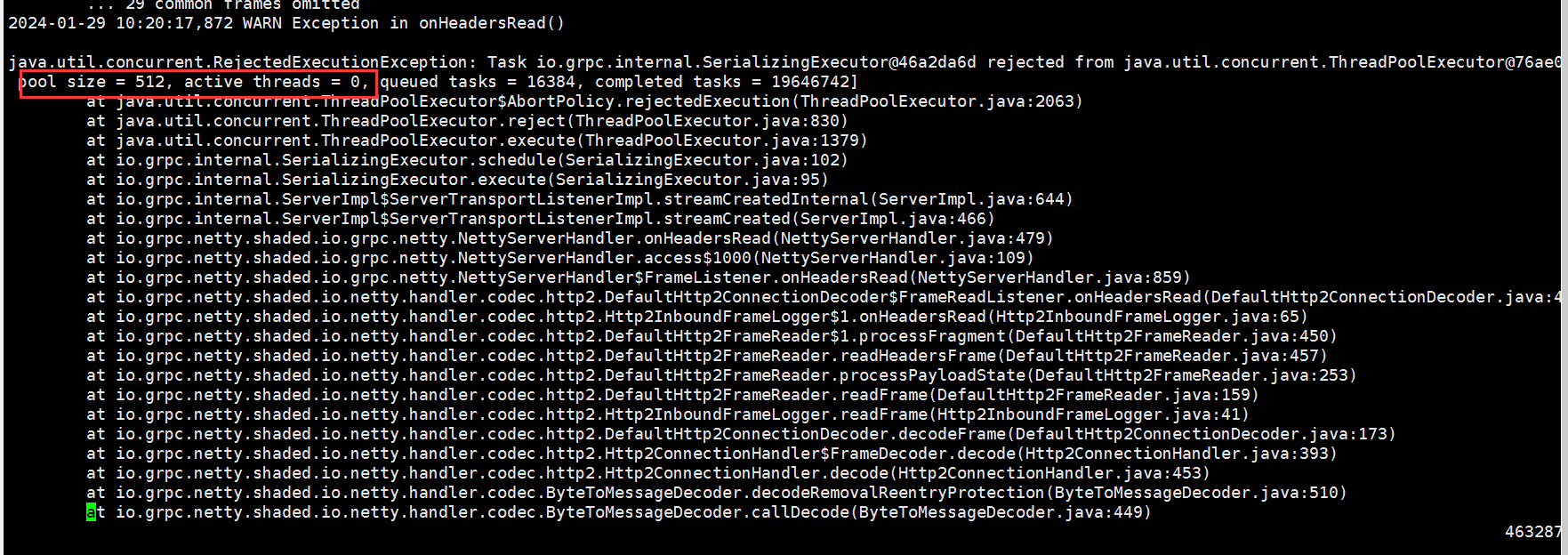
- 线程池相关日志显示:
pool size = 512, active threads = 0,线程池大小较大,但活跃线程数为0。
可能原因分析
1. 线程池配置异常
- 日志中提到的
pool size = 512表明线程池大小被设置为512,而active threads = 0表示当前没有活跃线程在处理任务。这可能是由于线程池配置不合理或任务调度异常导致的。
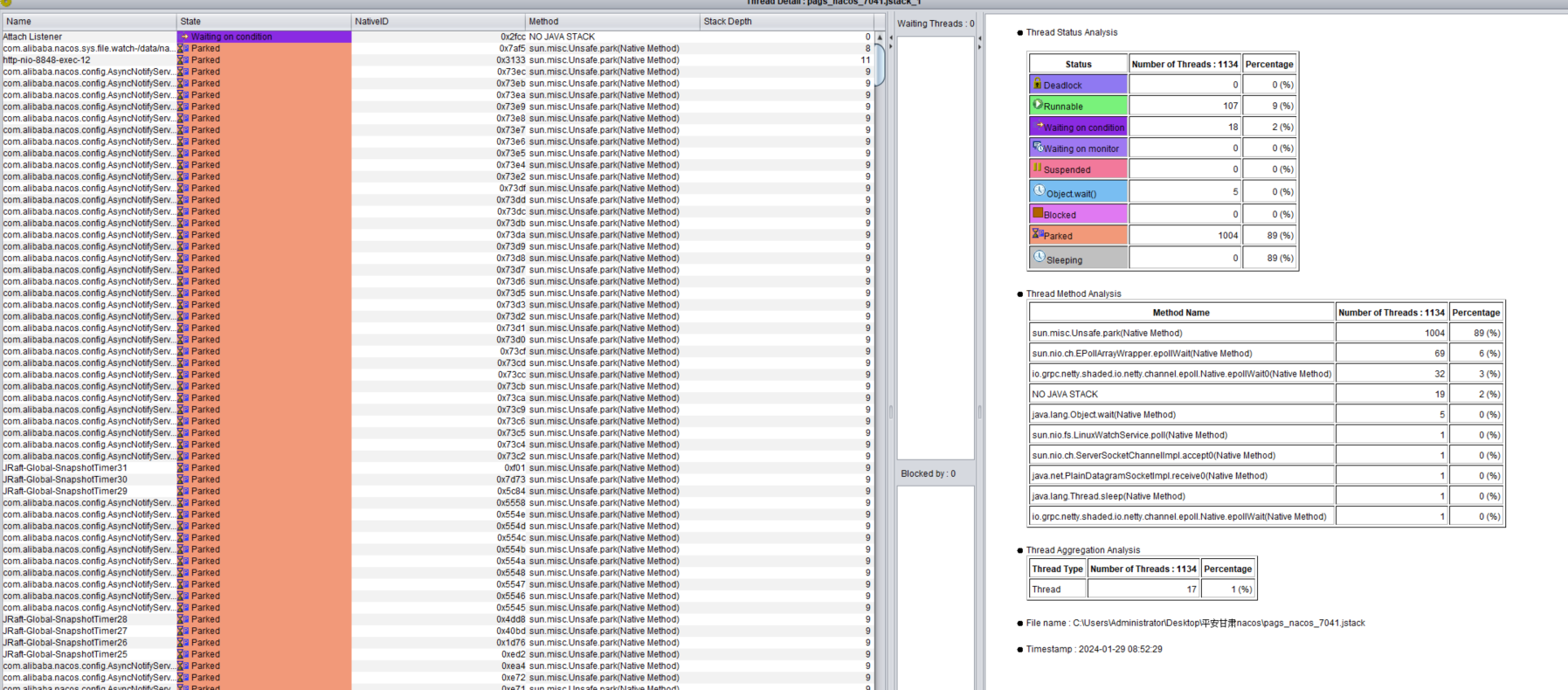
- 如果线程池过大(如512),可能会导致资源浪费或线程调度问题,尤其是在高并发场景下。
2. 客户端与服务端连接异常
- 根据知识库中的描述,Nacos客户端与服务端之间的连接可能出现问题,例如网络不稳定、服务端重启或客户端未正确处理连接状态。
- 您提到应用重启后无法连接Nacos,这可能是因为客户端在重启时未能正确重新建立与服务端的连接。
3. CPU或内存资源争抢
- 日志中提到
cpuremote.executor.times.of.processors,这可能与CPU资源争抢有关。如果系统资源不足(如Full GC、OOM等),可能导致线程池无法正常工作。
4. 配置中心功能未正确使用
- 如果仅使用了Nacos的服务发现功能,但未删除不必要的配置中心依赖,可能会导致客户端尝试连接配置中心失败,从而引发异常。
解决方案
1. 检查线程池配置
- 调整线程池大小:建议将线程池大小调整为合理的值(如64或128),避免过大的线程池导致资源浪费或调度问题。
- 检查线程池任务队列:确认是否有任务堆积或未正确执行的情况。可以通过日志或监控工具查看线程池的任务处理情况。
2. 排查客户端与服务端连接问题
- 检查网络连通性:
- 使用
telnet ${nacos.server.address}:8848测试客户端与服务端之间的网络连通性。
- 如果使用公网连接,请确保已设置公网白名单。
- 确认VPC配置:
- 如果使用内网连接,确保客户端和服务端处于同一VPC内。
- 检查服务端状态:
- 登录MSE控制台,查看Nacos实例的节点状态是否为“运行中”。如果发现非正常节点,请等待2~3分钟,若仍未恢复,请提工单处理。
3. 监控系统资源
- 检查CPU和内存使用率:
- 使用监控工具(如阿里云监控中心)查看客户端的CPU使用率、内存使用率以及是否存在Full GC或OOM等问题。
- 优化资源分配:
- 如果系统资源不足,建议增加实例规格或优化应用代码以减少资源消耗。
4. 确认功能使用情况
- 删除不必要的配置中心依赖:
- 如果仅使用Nacos的服务发现功能,请删除与配置中心相关的依赖,避免客户端尝试连接配置中心失败。
- 升级Nacos客户端版本:
- 确保使用的Nacos客户端版本为最新稳定版本(如2.2.3.1),以修复已知问题并提升稳定性。
5. 开启鉴权功能
- 如果未开启鉴权功能,建议开启鉴权以增强安全性,并避免因权限问题导致的连接异常。
重要提醒
- 线程池配置:请根据实际业务需求合理调整线程池大小,避免过大或过小。
- 网络连通性:确保客户端与服务端之间的网络畅通,尤其是使用公网连接时需设置白名单。
- 版本升级:建议将Nacos客户端和服务端升级至最新稳定版本,以修复已知问题并提升性能。
通过以上步骤,您可以有效排查并解决Nacos运行异常的问题。如果问题仍未解决,请提供更详细的日志信息以便进一步分析。