
speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch modelscope-funasr搭配vad模型无法使用gpu,使用示例代码都报错,怎么解决?已经提issue了,https://github.com/alibaba-damo-academy/FunASR/issues/1307 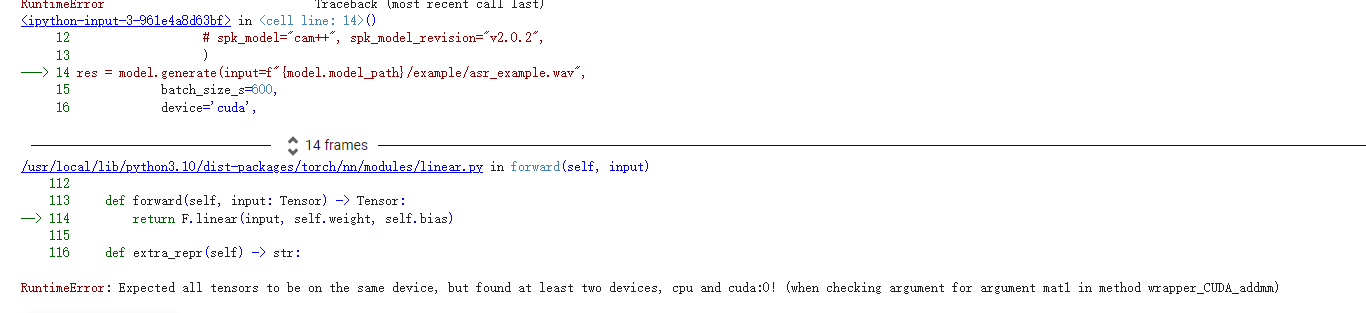
根据您描述的问题,speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch 模型在与 modelscope-funasr 和 VAD 模型搭配使用时无法调用 GPU,并且示例代码报错。以下是针对该问题的分析和解决方法:
从您的描述来看,问题可能涉及以下几个方面: - GPU环境配置问题:可能是由于 GPU 驱动、CUDA 或 cuDNN 的版本不匹配导致模型无法正确加载到 GPU。 - 依赖库版本冲突:某些依赖库(如 PyTorch、FunASR 或其他相关库)可能存在版本不兼容的情况。 - 代码实现问题:示例代码中可能存在未正确指定设备(如 device='cuda')的逻辑。
确保您的 GPU 环境已正确配置,具体包括以下内容: 1. 确认 GPU 可用性: - 运行以下命令检查 GPU 是否被系统识别: bash nvidia-smi 如果未显示 GPU 信息,请检查 GPU 驱动是否安装正确。 2. 确认 CUDA 和 cuDNN 版本: - 检查 CUDA 和 cuDNN 的版本是否与 PyTorch 兼容。可以通过以下命令查看: python import torch print(torch.cuda.is_available()) # 应返回 True print(torch.version.cuda) # 查看 CUDA 版本 - 如果 torch.cuda.is_available() 返回 False,请重新安装与 GPU 驱动匹配的 CUDA 和 PyTorch。
modelscope-funasr 和 funasr 库。运行以下命令更新:
pip install --upgrade funasr modelscope
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
在示例代码中,确保模型和数据被正确加载到 GPU 上。以下是一个典型的代码片段示例:
import torch
from funasr import AutoModel
# 检查 GPU 是否可用
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 加载模型并指定设备
model = AutoModel(model="speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch", device=device)
# 示例输入
audio_file = "example.wav"
result = model(audio_file)
print(result)
如果代码中未明确指定 device 参数,请手动添加。
RuntimeError: CUDA out of memory:可能是显存不足,尝试减少 batch size 或清理显存。ModuleNotFoundError:可能是某些依赖未正确安装。fuser -v /dev/nvidia*
kill -9 <PID>
您提到已经在 GitHub 提交了 issue,建议持续关注该 issue 的回复。同时,您可以尝试以下操作: - 在 issue 中提供详细的错误日志和环境信息(如 Python 版本、CUDA 版本、PyTorch 版本等),以便开发者更快定位问题。 - 如果问题仍未解决,可以尝试联系 FunASR 的官方支持渠道。
conda 或 venv)隔离项目依赖,避免版本冲突。通过上述步骤,您可以逐步排查并解决 GPU 无法使用的问题。如果问题仍然存在,建议结合具体的错误日志进一步分析,或等待 FunASR 官方团队的回复。
希望以上解答对您有所帮助!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
