
modelscope-funasr运行魔搭社区的模型报错下面的错误该怎么解决?
modelscope-funasr运行魔搭社区的“Paraformer分角色语音识别-中文-通用damo/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn”模型报错下面的错误该怎么解决?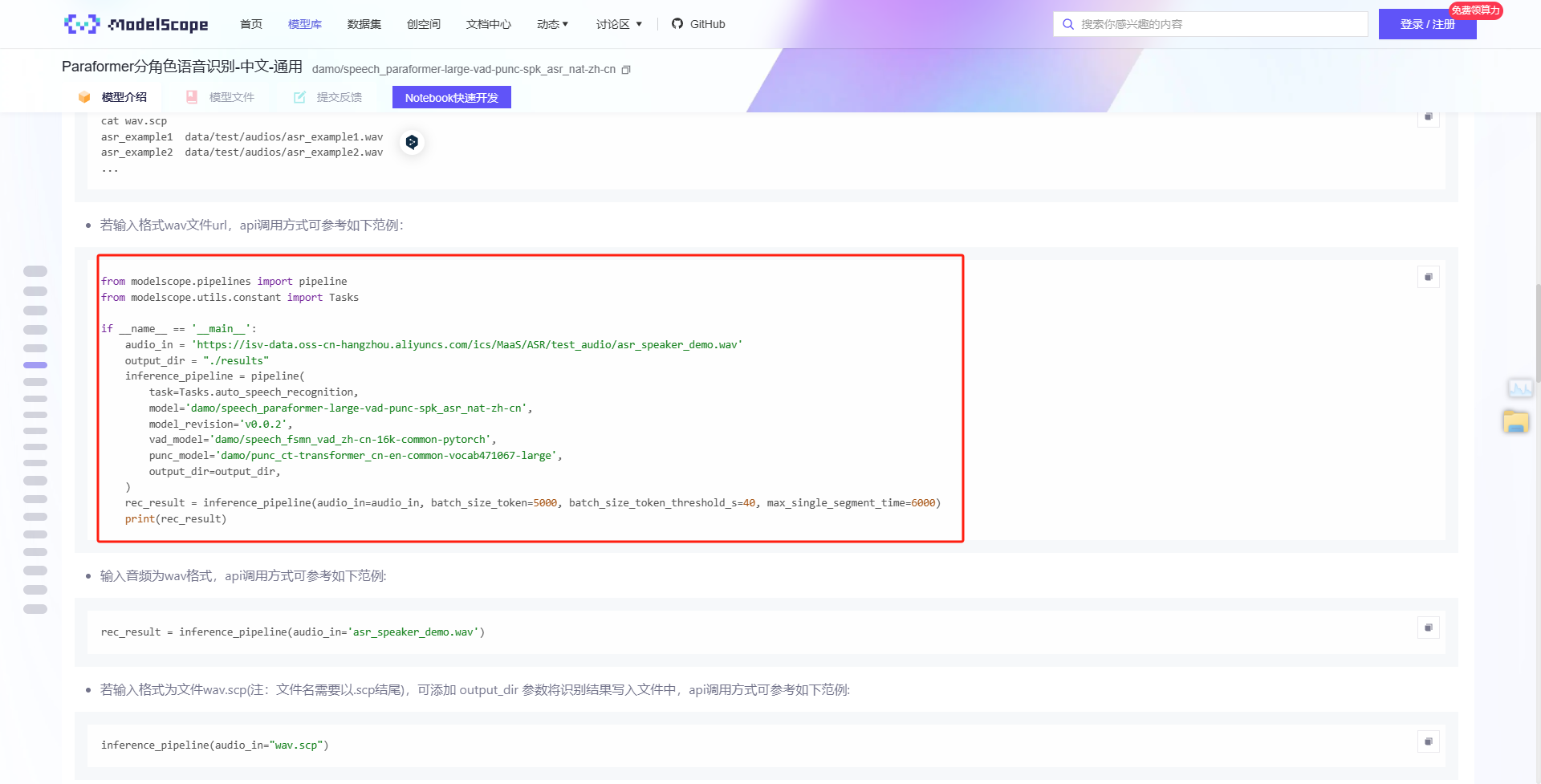
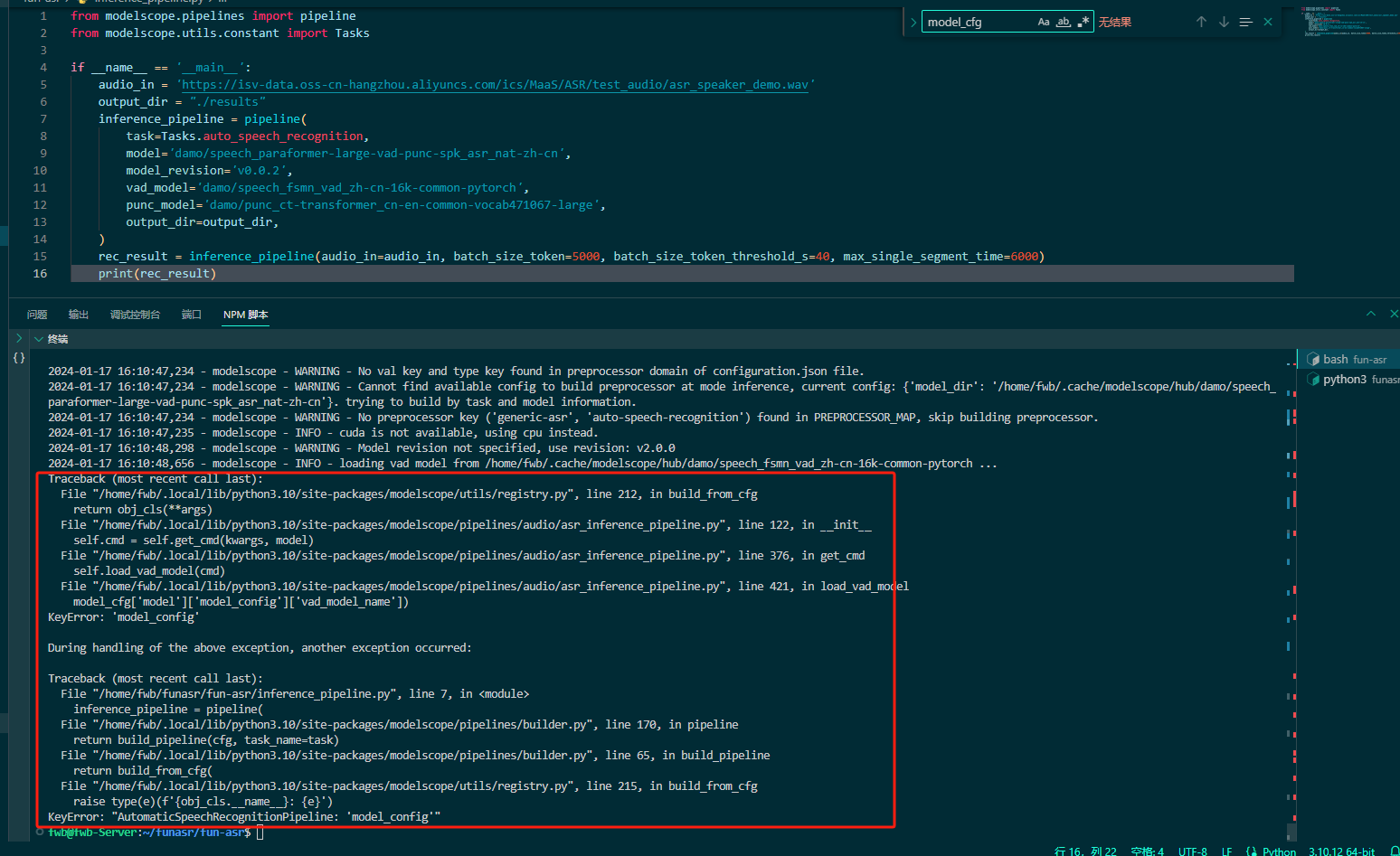
根据您提供的错误信息以及魔搭社区的“Paraformer分角色语音识别-中文-通用”模型相关知识库资料,以下是可能的原因分析及解决方案:
1. 检查输入音频格式和采样率
Paraformer模型对输入音频的格式和采样率有明确要求。如果输入音频不符合模型支持的格式或采样率,可能会导致运行报错。
- 支持的音频格式:
pcm、wav、mp3、opus、speex、aac、amr。 - 支持的采样率:
paraformer-realtime-v2支持任意采样率。- 其他版本(如
paraformer-realtime-v1或paraformer-realtime-8k-v1)仅支持特定采样率(如 16kHz 或 8kHz)。
解决方法: - 确保输入音频文件为支持的格式之一。 - 如果采样率不匹配,请使用音频处理工具(如 ffmpeg)将音频转换为目标采样率。例如:
ffmpeg -i input_audio.wav -ar 16000 output_audio.wav
2. 检查模型名称和参数配置
在调用模型时,需要确保传递的模型名称和参数与模型的实际支持能力一致。例如,您提到的模型名称为 damo/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn,请确认以下内容:
- 模型名称是否正确:确保模型名称与实际部署的模型完全一致。
- 参数配置是否符合要求:
format参数需指定正确的音频编码格式(如wav)。sample_rate参数需与音频的实际采样率一致。- 如果启用了语义断句功能(
semantic_punctuation_enabled),请确保该功能仅在 v2 系列模型中使用。
解决方法: - 检查代码中传递的模型名称和参数是否正确。例如:
payload = {
"task": "asr",
"function": "recognition",
"model": "damo/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn",
"parameters": {
"format": "wav",
"sample_rate": 16000,
"semantic_punctuation_enabled": True
}
}
- 如果不确定参数配置,可以参考官方文档中的 API 示例代码进行调整。
3. 检查热词定制功能
如果您在调用模型时启用了热词定制功能(vocabulary_id 参数),请确保热词 ID 已正确生成并生效。如果热词 ID 配置错误或未启用,可能会导致模型运行失败。
解决方法: - 确认是否需要使用热词功能。如果不需要,可以移除 vocabulary_id 参数。 - 如果需要使用热词功能,请参考官方文档中的“定制热词”部分,确保热词 ID 正确生成并传递。
4. 检查依赖环境和 SDK 版本
Paraformer 模型依赖于特定的 SDK 和运行环境。如果您的开发环境中 SDK 版本过旧或未正确安装,可能会导致运行报错。
解决方法: - 确保已安装最新版本的 SDK。例如,对于 Python 环境,可以通过以下命令更新 SDK:
pip install --upgrade modelscope-funasr
- 如果使用的是 Java 环境,请参考官方文档中的安装指南,确保 SDK 已正确安装。
5. 查看错误日志并定位问题
如果上述方法均无法解决问题,请仔细查看错误日志,定位具体的错误原因。常见的错误类型包括: - 输入音频格式或采样率不匹配。 - 模型名称或参数配置错误。 - 热词 ID 配置无效。 - SDK 或运行环境问题。
解决方法: - 根据错误日志中的提示信息,逐一排查问题。 - 如果问题仍无法解决,可以将错误日志提交至技术支持团队,提供详细的上下文信息以便进一步分析。
总结
通过以上步骤,您可以逐步排查并解决 modelscope-funasr 运行 Paraformer 分角色语音识别模型时的报错问题。重点在于确保输入音频格式和采样率符合要求、模型名称和参数配置正确、热词功能按需启用,并保持 SDK 和运行环境的最新状态。
如果仍有疑问,请提供更多具体的错误日志信息,以便进一步协助您解决问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。