

flinksql写法,定义1天滚动窗口,在group by时只写window_start,不写window_end,老版本flink只写一个会报错,我是flink1.16,这样写能使滚窗频繁输出结果,效率很高。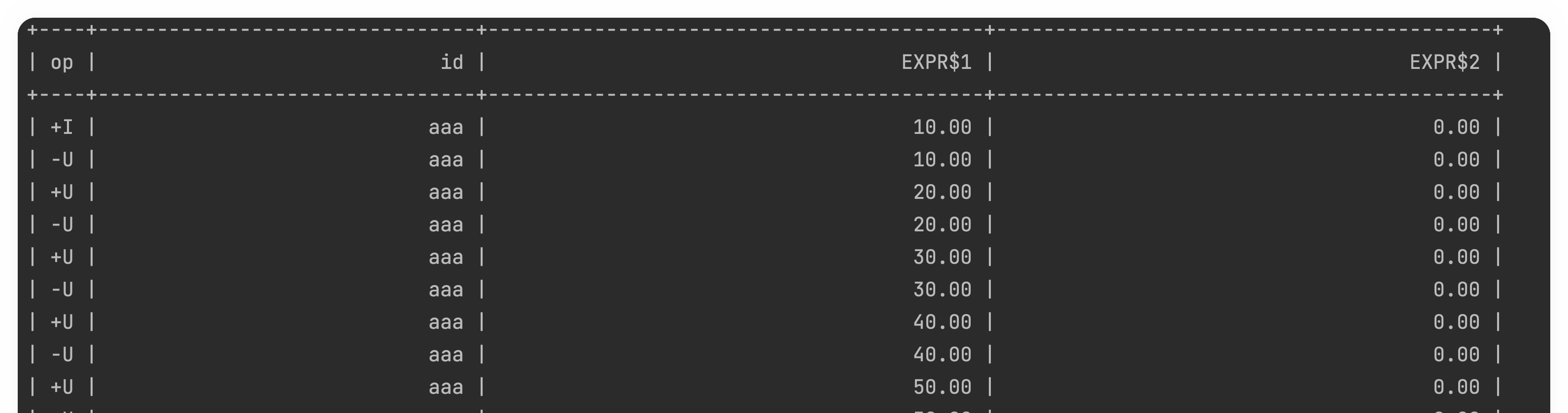
这个是打印出来的效果。找了很多官方文档,没看到有这么用的,大家帮忙看看呢
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink SQL中,定义滚动窗口(TUMBLE)时,通常需要在GROUP BY子句中同时包含window_start和window_end字段。然而,您提到的场景中,仅使用window_start而不包含window_end,并且在Flink 1.16版本中能够正常运行,这种用法确实不常见于官方文档中。
以下是对此问题的详细分析和解答:
滚动窗口(TUMBLE)是Flink SQL中的一种窗口类型,用于将数据流划分为固定大小、无重叠的时间区间。其基本语法如下:
TUMBLE(time-attr, size-interval)
time-attr:时间属性字段,可以是Processing Time或Event Time。size-interval:窗口的大小,例如INTERVAL '1' DAY表示一天的窗口。在GROUP BY子句中,通常需要同时指定window_start和window_end,以明确窗口的起始和结束时间。例如:
SELECT
TUMBLE_START(order_time, INTERVAL '1' DAY) AS window_start,
TUMBLE_END(order_time, INTERVAL '1' DAY) AS window_end,
COUNT(*) AS order_count
FROM MyTable
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY);
window_start的情况根据您的描述,在Flink 1.16中,您仅在GROUP BY子句中使用了window_start,而未包含window_end。这种写法在某些情况下可能不会报错,但需要注意以下几点:
GROUP BY子句中必须同时包含window_start和window_end,否则会导致语法错误。window_start进行分组。但这属于非标准用法,可能会导致兼容性问题,尤其是在升级到更高版本时。window_start,可能会导致窗口的边界信息丢失,从而影响结果的正确性。根据知识库中的参考资料,官方文档明确建议在GROUP BY子句中同时包含window_start和window_end,以确保窗口的完整性和结果的准确性。例如:
SELECT
TUMBLE_START(order_time, INTERVAL '1' DAY) AS window_start,
TUMBLE_END(order_time, INTERVAL '1' DAY) AS window_end,
COUNT(*) AS order_count
FROM MyTable
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
TUMBLE_START(order_time, INTERVAL '1' DAY),
TUMBLE_END(order_time, INTERVAL '1' DAY);
window_start可能导致窗口边界信息丢失,进而影响聚合结果的准确性。为了确保代码的可读性和兼容性,建议按照官方推荐的方式编写SQL,即在GROUP BY子句中同时包含window_start和window_end。例如:
SELECT
TUMBLE_START(order_time, INTERVAL '1' DAY) AS window_start,
COUNT(*) AS order_count
FROM MyTable
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
TUMBLE_START(order_time, INTERVAL '1' DAY);
如果您希望减少输出字段的数量,可以在最终查询中省略window_end,但在GROUP BY子句中仍需保留它。
虽然Flink 1.16允许仅使用window_start进行分组,但这种用法并不符合官方推荐的标准,可能存在数据一致性和兼容性风险。建议遵循官方文档的规范,在GROUP BY子句中同时包含window_start和window_end,以确保作业的稳定性和结果的准确性。
如果您仍有疑问或需要进一步验证,请提供更多上下文信息,我们将为您深入分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

